Automatic software analysis in context - inaugural speech TU Eindhoven
Introduction
Software is an interesting concept. It is a technology, an economic engine, a societal phenomenon. What exactly is software? And, why would we analyze software? Software Engineering is a relatively young field of study which is not easily compared to established fields like Physics or Chemistry. Comparing Software Engineering to fields which seem comparable, say Architecture and Construction, or Electrical Engineering, can lead to faulty and misleading metaphors. So, before discussing the purpose and the challenges of software analysis research, we should explore first what is so special about software as a technology and Software Engineering as a field of study.
The software concept is often misunderstood; one the one hand it is frequently underestimated as an area of academic research, on the other hand it is, also frequently, overestimated as some kind of “black art”. Is software simply a literal representation of existing mathematical and physical sciences knowledge? Is software a complex and hard-to-learn instrument, handled by an elite of programmers who are controlling and manipulating our world outside of our own control? There exists a down-to-earth outlook on software, which neither diminishes the reading and writing of software to a trivial form factor of something else, nor blows it out of proportion towards a supernatural art.
The software concept is a form of language. Like blueprints of buildings and musical notation are forms of language, software is a form of written language. A special ingredient to the software concept is that its expressions are not only produced and consumed by human beings, but also by computers. The human readable form of software is dubbed “source code”. Computers execute software by interpreting and executing the code in mechanical fashion. We humans write source code to make this happen. Perhaps surprisingly, we do read source code more often than we write it. We read code to learn about the original intent of the author or to be able to repair an error. We also read code for quality assurance. Many times we read code to enable us to extend it with new functionality, adapting the code to the ever-changing reality it should perform in.

The first page from "De Kellner en de levenden", written by Simon Vestdijk on a typewriter in Dutch and distributed using the printing press and trucks. Next to this a part of the grammatical analysis of programming languages, written on a MacBook Pro and distributed via the web. Software, is first and foremost a message, just like natural language.
Software is to a computer what literature is to the printing press. Software is incredibly universal, just like printed literature. We can describe music with it, cartoons, journalistic media, company administrations, weather prediction, laws, telecommunication protocols, board games, etc. Like with normal printed texts we can, literally, convey and execute fantastical ideas using software. This is why I am personally fascinated by software: writing source code is a form of creativity which is limited only by your own imagination.
Although software is quite abstract in its literal source code form, we do experience its effects quite intensely. We can not only feel the effects of software via standard peripheral devices such as computer screens, printers and loud speakers but also via other actuators such as injection manifolds in diesel engines, washing machines programs and the social security deposits into our bank accounts. The mobile device in your pocket -smartphone- has made the software experience even more pervasive and personal.
The impact on our daily lives should urgently motivate everybody to learn about software. It also motivates society at large to improve the digital literacy and computer literacy of all of its members. Yet, even the experts do not know how to answer plain and simple questions about existing software. The side-effects of using software are very important to us, but at the same time they are opaque and hard to explain.
To use most software, you do not in the least have to understand what it does or how it works. Like the old phone company slogan said: “If you can count to ten, you can call the whole world!”. At the same time you are vulnerable to information leakage, lack of robustness, energy consumption, and emerging operating and maintenance costs. Email is generally send “without an envelope” and everybody, in theory, can have a glance at the contents of your email in transit. Which information is being collected while we work, play, buy, go on a date? With whom does this information end up and how is it subsequently used?
As happy users of software services and products we do witness the effects of using software, but we hardly ever realize there is a simple cause to it all: what was written in the source code by somebody. A software engineer, on the other hand, witnesses source code all the time in some form or another. Who analyzes software, does that like a critic would analyze a modern novel: at different levels of detail and from different analytical perspectives. To achieve a complete understanding, every level of detail matters. An exciting plot of a novel can be ruined by broken sentences and bad choice of words, just like a brilliant software architecture can be ruined by unreadable source code which hides a privacy leak in its obscurity. The following non-exhaustive overview illustrates that software can be analyzed and understood in at least as many ways as a novel:
| Natural Language | Software Language |
|---|---|
| Spelling | Lexical syntax |
| Sentences | Context-free syntax |
| Paragraphs | Procedures and Functions |
| Semantics | Static and dynamic semantics |
| Chapters | Modules, components |
| Storyline, plot | Features, user stories |
| Framed story | Procedure and function calls |
| Character development | User interface |
| Theme | Application domain |
| Intertextuality | Dependency, reuse |
| Creative process | Design and implementation process |
| Writing tools | Interactive Development Environment |
The software literate has power. Software is now ubiquitous in society. Software has such a deep impact due to the computing and networking machines it runs on. These machines have become so small that they can literally be hidden inside almost anything. They have universal computational power. They have unimaginable capacity for storage, and unimaginable capacity for speedy computation. And finally, they are fully connected through the internet. Who writes software has a direct influence, if not power, over others, on every scale of human interaction. Professional software engineers know and understand this huge responsibility and take care to design software in close collaboration with its stakeholders.
It is nevertheless an Achilles’ heal of software that to design and create new source code you do not have to understand its future behavior in an evolving context. This leads to the conclusion that more arbitrary software will be written now than we will probably ever fully understand. Did you know that even “rocket scientists” have seen their billion euro project explode, simply because they did not understand that their old software would not run correctly on their new rocket? Why then do we insist on believing that the privacy of our children is guaranteed by the administrative software that our schools and school inspection uses? I certainly do not. The authors of a software system are not the most objective source of information about the internal quality of their own software, let alone those who sell this software. So: we have to learn how to objectively analyze the source code of software systems that matter to us, in order to answer relevant questions about it within a reasonable budget.
Intermezzo Dear policitians, lawyers, economists, and science colleagues, please start paying closer attention to the influence which the people who design and create our software have on our society, on our private lives, on our enterprises and on our research output. They are accountable, like architects and constructors are accountable for the quality of dikes, bridges, tunnels and buildings.
- Politicians, do you know how to judge (let alone test) whether or not your policies will actually be implemented, or not? Do you know if the authors of the software would be able to this themselves at least?
- Lawyers and judges, are the experts to whom you leave the judging of software quality indeed capable of answering the questions you ask them? To what extend is their advise accurate and trustworthy?
- Entrepeneurs, is the production and consumption of software visible at all as economic activity in your books? Is new software deprecated over time as it should be? How do you compute the deprecation value? Is software maintenance in your budgets?
- Scientists, is the software that you use in your data-driven research methods valid? Has the source code been scrutinized for mistakes or fraud? How? Who is monitoring this process and who is validating the result?

The baroque National Library of the Czech Republic in Prague. We write more software in more different languages today than we write normal books in natural languages. The challenge of the field Software Analysis is to enable engineers to analyse all that software, by understanding all that baroque variety.
Software language is not equal to natural language. The simile with natural language is possibly insightful for the layperson, but we should not carry it too far. Who rewrites a novel, ditching the original, simply because the societal context in which it was written is of the past? Who deems Shakespeare’s “Romeo and Juliet” despicable trash, simply because it contains spelling errors according to the contemporary English dictionary? Who collaborates on writing an epos which nobody could read in its entirety, simply because it would take more than a lifetime to browse through it? For a software engineer this is all quite normal.
Software is more dynamic than literature and other technologies such as constructing or electrical engineering. It is a mistake to think that this is just because software is easier to adapt than it is to adapt a train station which was already built, or a circuit board which was already printed. The more important cause of dynamics is the connectedness of software to its application context. Software users actively depend on software; therefore especially the successful software must continuously adapt to its ever changing context (panta rei). Older software, in general, is software which has been updated and extended many times. This is the reason the field of Software Evolution exists, which studies software from a biological perspective in terms of growth, metamorphosis and the emerging properties associated with these concepts. The viewpoint that, as opposed to software as a “novel”, actual software grows and morphs in its context is necessarily a strong factor in future research in software analysis. More about this later.
The viewpoint that the essence of software is that it is a language, does fit well to the reality that we have brought thousands of software languages to life, and millions of others have learned these languages to write billions of pages of source code. Software, as a language, also implies that we must not only write source code, but we must also read and interpret it; a.k.a. analysis. The viewpoint that software is language remains insightful. For example: the whimsical productivity of programmers is often lamented; how to control software engineering productivity? You do not; it is like controlling the creativity of a novelist. You let go of the control and you enable the engineers to design and create and to improve their creations.
The enormous variety in programming languages and programming technologies is also strongly related to the human factor: software engineers with their particular education level and expertise influence the situation as readers and writers of source code. Research in better tools for software analysis is caught in an almost paradoxical cycle of having influence on the future of software engineering, while inevitably being framed by the status quo. Every new tool must somehow fit into the context of today’s software engineers, to be successful.
Intermezzo: On the one hand we, as software analysis researchers, can enjoy the luxury of direct applicability and valorization of our research output to today’s software industry. On the other hand we must pay attention to the risk that fundamental research in software analysis is not limited to the volatile context of the present. The future, and also the past, must remain important sources of inspiration. The best software analysis research is “what if?” research, always challenging previous assumptions, folklore and the generality of simplistic theories.
Software analysis
Software analysis is a must. To be able to interpret existing software is a central skill which defines the art of software engineering. Based on a (partial) understanding of the source code and its context, the software engineers makes smaller as well as bigger design decisions. Smaller decisions are about the how and why of changing existing code, to fix a bug for example or to add a small feature. The larger decisions are about re-designing and renovating large components of a system, to remove deprecated components or to add new external dependencies.
Not only the quality of software, but also the economy of its production and maintenance are directly coupled to the activity of software analysis:
- Without analysis software can not be trusted. Software which was written based on misunderstanding or lack of understanding can only accidentally do the right thing. Using accurate analysis, important decisions can be made consciously, leading to rational and defendable software instead. Untrustworthy software does not only not do what we want (“Computer says no!”, “It crashed, again…”), it also does more than we bargained for (“My file is gone!”, “Why is it still running?”). Prime examples of unwanted behavior are storage or spread of false information, leaking secrets, and using more time, space or energy than strictly necessary.
- Software errors are costly. Not only is fixing software errors costly, also the impact of software errors in society is costly. Some software is safety-cricital, managing matters of life and death, while other software has enormous economical impact such as payment systems and wire transfers, taxes and social benefits. Practically all businesses and institutions can (and probably eventually will) incur serious damage due to software errors. Not all software errors are observable to its users, yet they pose significant economical risk to its owners. There exist dormant errors which only come to expression when usage patterns change (like peak load or the start of a new millenium), which can suddenly deeply embarrass its owners. There also exist design errors in source code which do not trigger acute problems, but still generate an emerging growth of complexity which eventually drives the cost of maintenance beyond the capacity of the owner. This is due to the inevitable rising cost of software analysis. The day on which its engineers are “suddenly” not able to perform the next fix or the next extension undoubtedly comes as a surprise nevertheless.
- Software analysis itself it a large cost item. To do analysis well, professional software engineers invest more than half of their time to the study of existing source code. Consequently they invest less time in creating new code. The current state-of-the-art in software engineering does not make full error prevention possible. This is why analysis (diagnostics) of software error (testing, debugging, fixing, refactoring) after the software has been constructed remains a necessary activity next to the analysis we do before the software is constructed (design, formalize, check, prove). The modern software engineering processes (agile methods in particular) are targeted to do a posteriori analysis as soon and as often as possible (continuous integration and testing) to avoid the risk of dormant or emerging issues. These methods also target avoiding wasteful a priori analysis, which can never predict the ever changing context. Automation of software analysis fits right into this agile philosophy by improving the speed of the design, test, improvement cycle.
- Software is potent engine of innovation. To unleash this potential, putting new products and services onto the market, there must be time for engineers to create new things next to maintaining the fast-growing mountains of existing software. The only way to create space for change is by optimizing the analysis of existing software. To mitigate cost of maintenance to acceptable levels.
There is too much code, and its too complex, to analyze source code “manually”
What is hard about understanding software anyway? If somebody can read and write software, wouldn’t she be able to simply apply the necessary changes? No, usually not.
The challenge is the “complexity” of software systems. Software systems are usually so enormous and so inter-connected (internally and externally) that the effort of true analysis does not seem to weigh against the risks of blindly adapting or extending the software by trial-and-error. Moreover, reading software is infinitely duller than writing it. Actually, just like in studying nature itself, patience and humility are fitting attitudes towards software analysis; we will probably never fully understand all software which has been written but we can try hard and we can use any help we can get, and we can use any tool we can get our hands on.
The rise of effective software tools, such as modern high-level programming languages, interactive development environments (IDEs), reusable software components and free software has fundamentally changed the art of software engineering, but not always for the greater good. Now everybody can, using very fast computers and internet, quickly compose more complicated and more flexible software then ever before. This development exacerbates the every growing analysis problem even more.
Still tools do exist already which can help in demystifying software. The last decennia of research in fields like Software Metrics, Program Comprehension, Software Re-engineering, Reverse Engineering, Software Refactoring, Dynamic Analysis and Static Analysis, Software Verification, Software Testing and Mining Software Repositories have produced an abundance of algorithms and tools for software analysis. These tools may answer specific questions about existing software with a certain accuracy. Examples of such specific questions are: Which components does this system comprise? Which components depend on which other components and how? Which parts of this system are harder to maintain? Which type of changes typically leads to which kinds of errors? Where in the source code is this feature implemented? Which components overlap in functionality?
My colleagues at the MDSE section of the TU Eindhoven also work on some of these tools from different perspectives: for example by the design and theory of formal models of communication or machine control, or by the empirical study of software engineering process meta-data (software repositories). My own interests lie with the source code, complementing the other members. Together we cover the larger part of the software analysis field: via code, via models and via meta-data.
Automating software analysis, software for software analysis, has added value because it scales much better than manual analysis. The reason is that automated analysis tools can:
- process large amounts of source code (and other related sources of information) very rapidly. This helps, for example, in localizing specific source code of interest without having to read through all of it.
- execute enormous amounts of deductive reasoning steps (for inference or verification). This helps, for example, in propagating impact of local changes to other parts of the system (if this has to change, then this has to change as well, etc.) Also it helps in predicting erroneous behaviors (e.g. model checking).
- compute descriptive statistics. For example, to make the distribution of hard-to-maintain code insightful over an entire software system.
- quickly produce diagrams and other visualizations. For example, great visualization exists which can produce an overview of inter-component dependency. We leave the interpretation to the human engineer, and use the computer to do the boring collecting and (faithful) mapping of a huge amount of data to the visual.
There simply is too much code, and too complex code, to do these kinds of analyses by heart. Ergo, high-quality software can simply not exist without automated software analysis. That is why programmers do use software analysis tools all-the-time, as part of their programming environment, often unknowingly. Examples of such analyses are IDE features such as Content Assist/Autocomplete, Jump To Definition, Rename and Browse Type Hierarchy. The more advanced tools however, prototypes which come out of research labs, are usually not integrated because they are either too slow to be useful or to inaccurate to interpret their outcome. A lot of research is still to be done to improve this situation; many baby steps mostly, and giant leaps once in a while.
Intermezzo: is prevention not always better than curing? Should we not make software in a different way; a way which avoids inhumanly complex source code? Can we not write software which is easy to understand from the start and easy to change in the future? This is the field of Software Construction. It fits very well into the picture of “software as a language” that progress in Software Construction (to write code as simply and flexibly as possible), is mostly driven by the invention of new languages. Not only do researchers focus on new programming languages to control existing computing and networking hardware, but also on new modeling languages which can enable the construction of new software in entire software application domains.
With Model Driven Engineering we use specific languages which allow software engineers (or sometimes directly the domain experts) to create new software within a specific domain, and also to change software within that domain. The underlying translation from the models down to code, includes interesting software analysis again. Source code which is written (or drawn) in modeling languages also enables useful analysis which are not possible at the general programming level. Examples of this are correctness proofs which need certain assumptions guaranteed by the code generators, and are not possible or feasible as such in a general purpose programming language. There is good reason why the MDSE section invests deeply in this direction.
However, whichever new languages we come up with, all code must be analyzed. Also to migrate from existing programming languages to the new modeling languages we must analyze the existing code. The conclusion is that software analysis is an important ingredient of both methodologies that prevent future software complexity, and of methodologies that try to remedy existing complexity.

School of Athens - Raphaël. Plato and Aristotle in their eternally impossible dispute on the essence of truth: idea versus observation. We can bring every Platonic idea to existence using software, but still this software is constrainted by our human reality and limitations: we must remain able to write and read it.
The defining quality of automated software analysis tools is accuracy of the produced answers.
First, it is important to realize that these analyses try to produce answers to questions which are often not even decidable or computable in theory, let alone feasible using limited resources in practice. This is why it is necessary to introduce design trade-offs in these tools, which can be done in four different, yet principled, manners and a fifth confusing manner:
- by allowing the occasional wrong answer (false positives). The trade-off of over-approximation is that a human being must manually check all answers for truth, or decide to take even false alarms seriously. The benefit of the tool remains the ratio between having to read all the code versus having to go through a list of answers.
- by occasionally leaving out right answers (false negatives). The trade-off of under-approximation is that we never know if we seen it all, but still we have a number of answers which are guaranteed to be interesting.
- by redefining the question in a weaker form (e.g. yes/maybe, or maybe/no). Now the answer is always accurate in an artificial manner, but at least it communicates clearly the uncertainty of the answers. When we interpret “maybe” results carefully, the previous two interpretations of over-approximation and under-approximation can be applied again.
- by accepting that in arbitrary cases the analysis does not terminate, or at least not within an acceptable time or memory budget.
- and finally, and most confusingly, by combining the above four strategies in arbitrary ways. This leaves the outcome of an analysis almost impossible to assess. It seems unlikely any designer would go for this option, but contemporary tools in IDEs do have this unfortunate –perhaps unavoidable– aspect of being both under-approximations and over-approximations, as well as sudden longer running times, and weakly defined analysis questions. Programmers sometimes reject the whole concept of software analysis based on their experience with such, promising yet hard-to-gauge, tooling.
Even if most software analyses are approximations of the actual questions asked in arbitrary manners, still we can compare their quality objectively, scientifically. All theoretical results in software analysis must be validated empirically, due to the unavoidable design trade-offs. These design decisions are commonly based on what their designers think real code looks like. Evidence must be acquired to support these design assumptions, and to be able to clearly diagnose failure when it eventually happens (not if).
We use “laboratory experiments” as well as “field studies”. The first isolates the positive or negative effect of a new tool in a controlled environment, compared to the state-of-the-art in manual or automated analysis for the same analysis question. The latter applies the new tool on a corpus of realistic systems in order to asses its relevance and impact on software “in-the-wild”.
We assess the quality of appromimations by comparing resource consumption (time & memory) and accuracy (sensitivity and specificity) to an existing oracle:
- manually constructed answers for a small collection of example software systems
- automatically produced answers by a previous generation competitive software analysis technology
Neither method is 100% water-tight, as you might imagine. We refer to the holes in experimental evaluation methods of software analysis as “threats to validity”. Next to generalizability, which seems the most obvious, simple human error is an often ignored threat to these scientific results. The validation and interpretation of the resulting data is often very tedious and therefore error-prone. It is not uncommon that previously published results are invalidated when we try to replicate them.
On the one hand we are observing the growing pains of a young research field; every new paper is introducing new research methods, applied to a new -and vulnerable- corpus. On the other hand, the application context of the tooling changes rapidly, such as the machines on which the experiments are executed, the software to which the tool is to be applied, and the programming environments the tools are a component of.
Ergo caveat emptor! Healthy scepsis is duly advised when reading and interpreting published academic research in software analysis.

M.C. Escher. The viewer of the painting is an actual part of the depicted landscape; a situation which characterizes the complex relation between Software Analysis research and the Software under study.
Intermezzo Sometimes promising new tools are evaluated for their usability and impact in resolving challenges programmer tasks. The method is “A/B testing”; programmer guinea pigs are observed while executing tasks with and without the new tool. This kind of research is costly, hard to execute well, and hard to interpret. There are so many environmental factors to the effectiveness of programmers which we have yet to identify, let alone understand. The A/B programming task method is inherently multi-disciplary between Computer Science, Psychology and Sociology. I am personally worried that our field is stepping to these empirical methods way too early; without an inkling of the quality of our own work. We should spent our funding making this research possible for the future.
If the mountain does not come to Mohammed… Yes, it is clear the challenge for software analysis is to achieve optimal accuracy for minimal resource consumption. But, we can also step out of this box to think about practical bounds for the design of source code within which we can just do analysis effectively. This too is a route towards understanding software. We can ask software engineers to offer extra (redundant) information (using annotations, test code or specifications), or we can limit programming languages in such a way that certain untraceable interactions are no longer possible a priori (type systems and domain specific languages fit into this perspective). The programming languages and modelling languages design fields can be positioned as such: to find an optimal balance between automated analyzability and human expressivity.
We are witnessing that the growing power of computing and networking technology is enabling deeper and more advanced code analyses, with higher accuracy and with faster response times. At the same time, another source of hope is the application of context information to software analysis.
Software is contextual to its core. To interpretation a novel, the social context of both the reader and the writer are certainly very important, but to interpret source code as it is written knowing its context is of vital importance. Only by learning about its context we can understand the why and how of the author of the code, and we might learn about the why and how of the code’s performance in its current (different) context. Examples of the kinds of context information which are relevant are the ever evolving business context, the hardware technology which the software controls, the natural phenomenon which the software intends to model, the users of the software, the time in which the software was written and its contemporary “best-practises”, the background philosophy of the programming paradigms used to write the software, the design of the programming languages used, the versions of the reusable components which are applied, etc. etc.
This is why we should never assume or expect that a software engineer with general software engineering skills and knowledge can accurately analyse any specific piece of software! The what, how and why, (ontological knowledge) of a specific application domain, and the corresponding skills for people, in that domain are simply missing. For example, a little error in the mathematical ocean model, which was constructed with skill and knowledge of oceanography and climate modeling, can break the prediction for minimal dyke heights in The Netherlands after global warming. The source code which computes these predictions may be a perfect representation of an otherwise absurd (with hindsight) theoretical simplification. Even if source code is an absolute definition of what a computer will do when it executes the code, the knowledge about the intention of the designers, and their design rationales remains implicit.
This contextuality of source code is the primary reason for professional software engineers to document their intentions and their reasoning using “source code comments”. There exists also the field of Requirements Engineering, with the purpose of discovering and documenting software design decisions, tracing them back to the requirements of the software. Also, Software Specification (Formal Methods), and Software Testing are ways of introducing redundant information to the development process. These methods make the assumptions under which the software should work explicit, after which they can be used to triangulate bugs or to show their absence.
On the one hand, requirements, annotations, specifications and tests do add usable information to the programmer. On the other hand, all this additional information adds to the enormous complexity of software systems, to its cost of maintenance. For example, languages for which formal specifications exist to assure the quality of their compilers are notoriously not in use anymore; too much energy went into proving the languages correct, taking away energy from resolving criticical issues for the users of the languages. Still, any additional information we do have could be a valuable input to automated analysis tools.
Domain Specific Software Analysis
The corrolary to the contextuality of software is that the study of software analysis must be based on intense collaboration with other fields of study, such as mathematics, electrical engineering, architecture, finance, and law. We have to deeply integrate the domain knowledge of these fields (theory, models, rules and regulations) into our own philosophy (programming paradigms, languages, frameworks, libraries, tools). Like model driven engineering integrates domain knowledge a priori into the development of new software via domain specific languages, domain specific software analyses will integrate contextual domain knowledge to unravel the secrets of software systems.
The application of contextual information is on the rise in software engineering. For example, precisly modeling the semantics of software frameworks in IDEs enables much more accurate analyses. To join the results of analyzing the server tier of a software stack (written in Java) with the results of analyzing its client tier (written in Javascript), can significantly increase the accuracy of both analyses. Either is context-information for the other party. Now, such a combination is only valid within the domain of Java/javascrip website software, but it can have enormous impact on the quality of the analyses and thus on the quality of the analyzed software.
Let’s say we need to answer dire questions about the information security of a banking website. This security is as strong as the weakest link in the entire stack; if we do not analyse the entire stack in concert we are not analyzing all of its possibly weak links at all. By combining the client analysis with the server analysis we can produce insight on the entire chain and hopefully identify and resolve any security weaknesses.
Given the enormous variety of software components and software technology their exists an enormous potency for these kinds of coupled analyses. Combining information sources for answering analysis questions should be a very fruitful enterprise.
Integrating context-information into software analyses is largely unexplored territory. Exceptions aside, most software analysis literature and the corresponding tools target maximal impact by designing analysis which are most generally applicable. I put forward that we will shortly be at the end of this rope; no more progress can be made by making tools which work on any piece of arbitrary code. Instead we must investigate analyses which are bespoke to software application domains. Context-sensitive analyses will be studied which integrate information from any available “external” sources next to source code. Examples of such sources of information are: configuration scripts for build and integration environments, law texts, formal ontologies, source code comments, glue code written in dynamically types scripting languages, mathematical models specified in Matlab or Mathematics, user manuals, etc. etc.

Vik Muniz. Like source code, this jelly jam and peanutbutter art can not be interpreted without a wealth of contextual knowledge: who is this lady for example?
The primary challenge for the future of automated software analysis is the effective integration of context-information. Effective means feasible within a budget as well as relevant and effective in improving analysis accuracy. The main issue is scale. How can we specialize analysis tools for their application context, using the information which is provided by said context? Constructing and evaluating accurate analysis tools is complex, detailed and tedious, work. How can we expect that for the practically infinite contexts the field can produce correct analysis tools? Who will take on this task anyway?
These questions finally bring us to the topic of my own specialism: designing, evaluating and applying “meta tools”. A meta tool is a tool to make a tool. A metaprogramming language is a programming language to construct programming language with. To create new specialized software tools, existing tools must be made in extensible and adaptable ways, using effective meta tools. To affect all these adaptations, a large group of software engineers must be able to use such meta tools effectively.
Rascal is an experimental metaprogramming language targeted at rapid construction, maintenance and application of software tools. The eventual goal is to learn to understand software. To do this we must create automated analysis tools. To design and construct these tools I will continue the design and implementation effort of Rascal. In concert, I will continue the track of empirically investigating the tools we construct, and applying these tools in empirical investigations in software engineering. Finally, the same tools are key in valorisation of academic research in industry. Specifically, open questions in the high-tech sector in Eindhoven, and the finance sector in Amsterdam, are on the agenda.
Research questions
Metaprogramming
When we have answers to the following questions in the metaprogramming field, we would be able to create new kinds of software analyses more efficiently and more effectively:
- Data acquisition: How can we rapidly model external information, and integrate it into the larger context of software analysis? How to effectively reuse (modular) meta-definitions of this information?
- Variability: How can we affect much more reuse between complex analysis tools, between programming languages, versions of programming languages, and frameworks? Which intermediate representations would enable such reuse? How to modularize software analyses?
- Scalability: How can we analyze large bodies of contextual information efficiently (relations, hierarchies), at once, in order to explicitize crossover relations and impact between different software components? How do we implement on-demand access to such semantically rich bodies of knowledge?
Software analysis
The next generation of software analyses is going to have to address more information and more kinds of information to be able to accurately answer the questions of both software engineers and software users:
- Code-to-model: how to extract useful domain knowledge (models) at a high level of abstraction from low-level source code?
- Context: how to integrate meta-information and configuration information about software systems into the static analysis of source code?
- Quality: how to assess, at least semi-automatically, important qualities such as information security, availability/robustness and maintainability of software systems?
- Renovation: how can we enable perpetual change and improvement (refactoring) of software systems using semantically deep analyses of the source code in its context?
Empirical research in software analysis
The empirical questions I will focus on concentrate around the evaluation of software analysis tools and the validity of these evaluations:
- Accuracy What is the accuracy of new and existing analysis tools? What would be the positive/negative impact of applying these tools during the software construction and maintenance process?
- Noise What is normal source code? What can we expect from the impact of new analysis tools among the noise of other factors on the quality of existing systems?
- Data quality What is the validity of the information (e.g. data from version control systems, issue trackers and continuous integration systems) which use to “improve” the accuracy of new analysis tools?
Valorisation challenges
Because software analysis itself is contextual to its core, it is practically always necessary to partner up with software industry or some other domain expert. This collaboration when forged immediately enables direct valorisation of any research output. However, to increase the wider impact of software analysis research we need better answers to the following questions:
- Priority Which challenges with respect to software analysis have highest priority in (local) industry?
- Ownership How to instill ownership for bespoke software analysis tooling? What are required features of meta-tooling to affect this ownership? Which educational measures can we employ?
- Implementation How to approach the implementation and use of new software tools in complex industrial contexts?
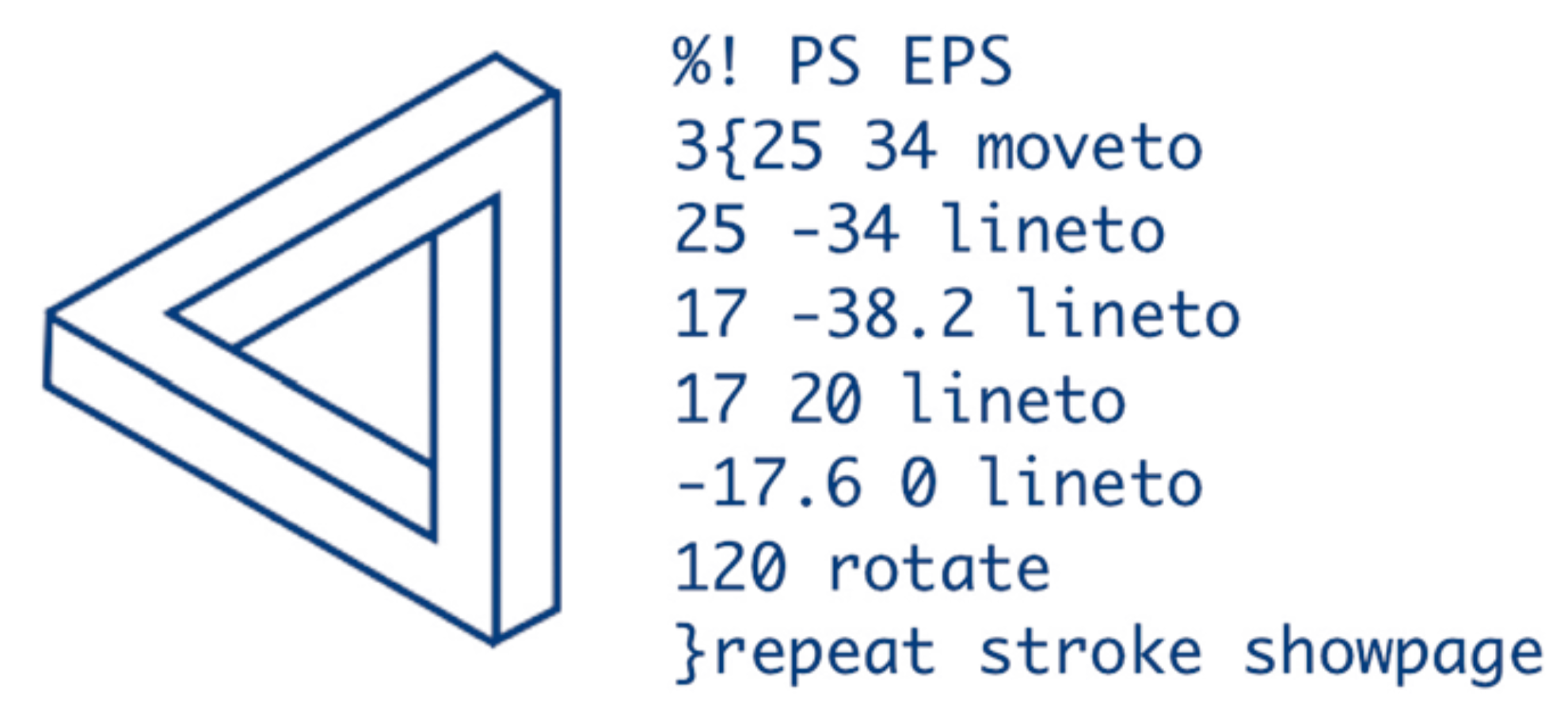
Kees van der Laan wrote this source code in the Postscript language to simulate a Penrose triangle. Valorisation is a necessary and required output of academic research, but its three stakeholders -government, academia and industry- do not literally align, like the three sides of a Penrose triangle. It's a creative matching process which requires continuous imagination and investment from all sides to make opportunity meet preparation.
Conclusion
Software is interesting, and not just from an intellectual perspective, but especially from a societal and economical perspective. Automated software analysis is a necessary research topic, to enable us to understand and control the software which already control us. There exist clear steps to undertake in the direction of contextual software analysis tools. For this, I intend to further explore the existing successful collaborations between the TU Eindhoven, CWI and their industrial partners.
Words of thanks
It is a personal honor to be allowed to present an inaugural speech, yet I would like to share this honor with those who have enabled me, taught me, and inspired me. I have a lot of thank to my family, my teachers, my friends and my colleagues.
Rebecca Vinju-Maclean, and Simon, and David, you are the most important people to me, so you come first in this list. It is my salvation to know that being with you is better than being at work. I love you more than I love software, and then some, and of course to the moon and back and round again.
Annelies Vinju-Zuurveld, thanks you for my life and for your endless support, and for our educational adventures together “behind the screen”. Fred Vinju, thank you for everything that I’ve learned because of you: our computers which I could annex and for the guts to fix everything ourselves at home (the breaking of stuff is my own talent I believe). Krista de Haas, my sister, thank you for being rather exactly like me in many ways. It makes me feel not alone in the world, and not as crazy. Even though we don’t see eachother enough, my friends: Bas Toeter, Winfried Holthuizen, Warner Salomons, Hugo Loomans, Mieke Loomans, Allan Jansen, Arjen Koppen, Rob Economopoulos, Tijs van der Storm and Rik Jonker: thank you for your friendship.
Paul Klint, thank you for my entire professional career, from choosing Computer Science as a study to research manager and part-time professor, and everything I’ve been in between. It’s a short sentence, but I attribute the larger part of my personal growth to your coaching. Next to your advises I’m very happy you have left plenty room to make my own choices and with those, my own mistakes, to learn from. It remains a great pleasure to collaborate with you on a daily basis on the Rascal metaprogramming language.
Mark van den Brand, thank you for supervising my masters thesis as well as my PhD thesis work, and for the position as part-time full professor here at the TU Eindhoven. You have led by example: doing research, as a team, into language technology and its applications, building new tools, evaluating and applying them and then writing about it all. Now this is all I want to do. You as well have let me run free, which is one of the main reasons that I could come closer to you again professionally at this stage.
I have been especially inspired by studying the works of, or even discussing with, the following colleagues over the years: Gerald Stap, Jan Heering, Tijs van der Storm, Mark Hills, Hans Dekkers, James R. Cordy, Ralf Lämmel, Alexander Serebrenik, Tudo Gîrba, Anthony Cleve, Oscar Nierstrasz, Mike Godfrey, Frank Tip, Stéphane Ducasse, Friedrich Steimann, Peter Mosses, Terence Parr, Magiel Bruntink, Joost Visser, Andreas Zeller, Yannis Smaragdakis, and Robert M. Fuhrer. Also I want to thank the following colleagues in chronological order of influence: Chris Verhoef, Hayco de Jong, Pieter Olivier, Jeroen Scheerder, Merijn de Jonge, Leon Moonen, Eelco Visser, Arie van Deursen, Tobias Kuipers, Peter van Emde Boas, Niels Veerman, Steven Klusener, Jørgen Iversen, Slinger Jansen, Taeke Kooiker, Pierre-Étienne Moreau, Claude Kirchner, Rob Economopoulos, Jan van Eijck, Rober van Liere, Bert Lisser, Atze van der Ploeg, Paul Griffioen, Stijn de Gouw, Martin Bravenboer, Vadim Zaytsev, Ashim Shahi, Anya Helene Bagge, Elizabeth Scott, Adrian Johnstone, Dimitris Kolovos, Davide DiRuscio, Anamaria Moreira, Cleverton Heinz, Jan Friso Groote, Yanja Daysuren, Joost Bosman sr, and Joost Bosman jr. To agree or disagree with you, to work with you, to study your work, or to wildly philosophize on the future of software; it’s all absolutely wonderful.
Next to the CWI as a whole I would also like to thank a number of specific people that I appreciate as colleagues: Jos Baeten, Han La Poutré, Frank de Boer, Rob van der Mei, Ronald de Wolf, Dick Broekhuis, Karin Blankers, Bikkie Aldeias, Susanne van Dam, Margriet Brouwers, Karin van Gemert, Irma van Lunenburg, Marlin van der Heijden, Léon Ouwerkerk, Niels Nes, Wouter Mettrop, Rob van Rooijen and Angelique Schilders. Thank your for the excellent working environment at CWI.
I thank Bas Basten for the first PhD thesis that I was allowed to be co-promotor of. Thanks for the great collaboration on that wonderful topic.
Finally, and certainly not in the least, I thank (in alphabetical order) the current PhD candidates who are working on their grand challenge now: Ali Afroozeh, Anastasia Izmaylova, Davy Landman, Jouke Stoel and Michael Steindorfer. I’m sure that I’m learning as much from you as you are from me. Also a big shout out to the other Phd candidates in the SWAT group, for your boundless energy and enthusiasm: Gauthier van den Hove, Riemer van Rozen and Pablo Inostroza Valdera.