Figure 11.1
Pascal Implementation by Steven Pemberton and Martin Daniels
The previous chapter outlined the structure of the P-code machine. This chapter is concerned primarily with the assembler for the P-code machine. However, the software provided with the P4 implementation kit does not rigidly separate the functions of the assembler and interpreter, indeed they are presented as one program. So although the assembler will be described in this chapter there will of necessity be some overlap with the next chapter where the interpreter is discussed. In particular the major declarations and type definitions will be introduced here along with an introduction to the main data structures used.
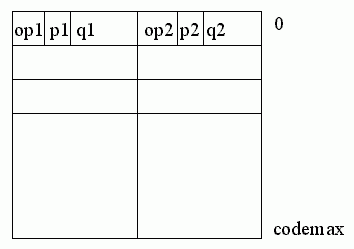
The assembler generates two data structures for later use by the interpreter. The first is the code section which holds the P-code instructions instructions in assembled form and will also be used by the assembler as an extension to the label table for handling forward references. Figure 11.1 shows the internal arrangement.
Figure 11.1
Each word contains two P-code instructions. (This is an efficient use of store on a CDC 6000 series computer for which it was originally written but is not the best arrangement for smaller machines. On an eight-bit computer, for example, a P-code instruction would typically occupy four bytes of store). This structure is also used by the label definition process to be described later.
The second structure generated by the assembler for the interpreter holds the constants that are separated from the code section. This structure is held, along with the stack and heap, in the store array. The arrangement is shown in figure 11.2.
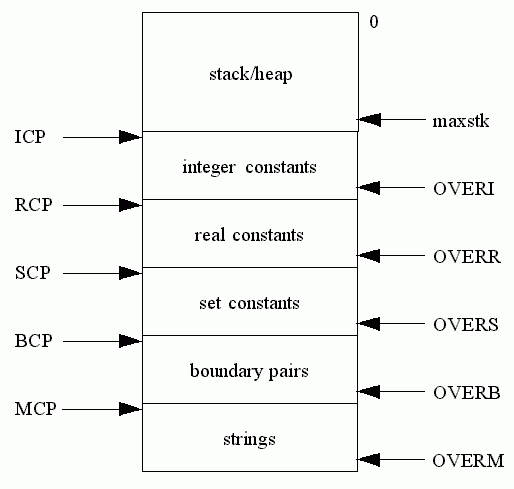
Figure 11.2
The store array is manipulated by a number of pointers, the maxstr pointer defines the maximum size of store and maxstk defines the maximum area available to the stack and heap. The other pointers are concerned with the storing of constants. Each type of constant has its own pair of pointers -- the over pointer gives the end of the available area while the other pointer denotes free space. Although each type of constant has its own portion of store and pointers this is not an absolute necessity and this arrangement leads to an inefficient use of store. It would be sufficient to have a single constants area and a single pair of pointers.
A detailed analysis of the assembler now follows.
[23-38] Constants
[23-4] Codemax and pcmax are directly related constants: codemax is used to define the length of the array which will hold the code. As each word of this array is used to hold two instructions pcmax should be twice the value of codemax. Maxstk defines the maximum space available for the stack and heap in array store.
[26-30] These constants are used to set the boundaries within the constants table; the values must be selected by trial and error as the constants generated depend on the user's program.
[32] Largeint. This constant defines a large integer which is a function of the declarations on line [42], being the largest integer that will fit in an instruction.
[33] Begincode. The first instruction that the assembler processes will be stored at this address. This makes room for the second code record that consists of three instructions.
[34-7] These four constants define names for the file variable locations which are held at these addresses in the program stack frame. Outputadr and prradr are not used by name.
[38] Duminst, dummy instruction, is used for the symbol search mechanism by the assembler [270]. It is one greater than the last actual instruction.
[40-5] Types
The first three types are used primarily to define the instruction format. Unfortunately the names are not consistent, for example, if it is assumed that bit4 is correct then bit6 should be 0..63.
[43] Datatype, covers the types that are allowed in store. Undef is not actually used.
[47-86] Variables
[47-54] Code holds instructions as they are assembled. Each record holds two instructions as previously discussed.
[58-68] Store
This declares the array that will hold the stack, heap and constants table. Use is made of the variant record. Undef should have been included with empty () as this was part of the datatype definition. [63] sett is defined as a set of 0..47: this value is parameterised in the compiler and it should be parameterised here too. [67] mark is used for storing register values within a stack frame.
[69] The four stack and heap pointers are defined.
[78-80] The three arrays declared here hold fixed tables. Instr will become a symbol table for the mnemonic instruction codes. All the codes involve three letters only, therefore the use of type alfa is inefficient. Alfa is a non-standard type for the CDC implementation which is equivalent to
alfa: packed array [1..10] of char;
i.e. 10 slots are allocated where only 3 are used. Also only 62 mnemonic instruction codes exist, 63 if the dummy instruction is included and consequently the index type of bit6 is inappropriate i.e. over half the array is not used. A better declaration might be:
type alpha: packed array [1..3] of char; var inst: array [0..duminst] of alpha;
Similar comments apply to sptable and cop.
[83-6] The remaining variables are mainly temporary. Adl, c and j are not used.
The three arrays instr, cop and sptable are only used in the procedure load and therefore they should be declared within that procedure.
op1 and op2 should be declared as 0..duminst.
The P-code assembler lies between [90-434] and exists as the procedure load. It follows traditional one-pass assembler lines. There is one further major data structure to manipulate, the label table.
The assembler reads the P-code source statements from the prd file and assembles these statements generating machine code which is left in the code array. The label table is generated by the assembler in order to look after label definitions and forward references. The declaration of the table is between lines [91-7] and [100]. This generates a structure as shown in figure 11.3.
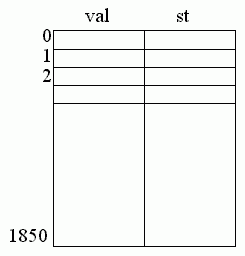
Figure 11.3
There is one location for each label number. The right hand column, st, will denote when a label definition has been found and the left hand side, val, will either be the label address when the particular label has been defined, or if forward references to the label occur then val is used as a pointer to the code array where the label address must be put when the definition is known. If further forward references to the same label occur then this instruction points to the next instruction that uses the label and so on. The value -1 terminates the list. Figure 11.4 illustrates this structure.
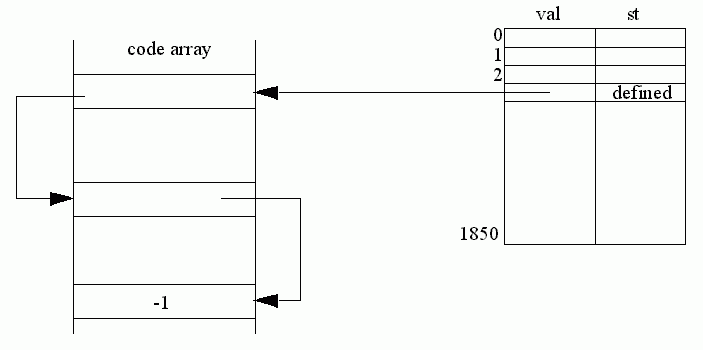
Figure 11.4
This procedure contains a number of nested procedures which comprise the assembler proper. The declarations will be discussed where used.
[103-65] init
The main purpose of this procedure is to build the various tables. The symbol table for mnemonic instruction codes is built between [105-35] and the standard procedures are dealt with in [137-47].
[149-53] cop (change opcodes)
This table is used by procedure typesymbol to give some of those instructions with a type parameter a unique opcode for every instruction/parameter pair. The array is not very efficiently used with only 9 locations filled, out of the declared 128.
[155]
The PC is initialised, this defines where the first segment of code
is to start.
[156-60] The boundaries of the constants within store have been defined, as previously discussed, and these five statements set up pointers to the various areas.
[162-3] The label table is set up with the initial values; the value -l representing a terminator and entered showing that the label has not yet been defined.
[164] The prd file contains the source P-code.
An undefined value undef has been defined in the set datatype. It would be a good idea if the store array were initiallsed with the undef value and then every access could be checked to ensure that a value exists, but this necessitates a change to the store declaration.
[167-71] errorl
This procedure is used to print an error message and halt execution when an error has occurred in loading. Halt [170] is a non-standard Pascal procedure which terminates program execution.
[173-98] update
Procedure update is called when a label definition has been found in the source [215]. Its purpose is to insert the label value into the table and to search for any forward references that had been made to this label and assign the label value in these cases. The technique was discussed at the beginning of this section. [174] curr and succ will be used to search through the list of forward references.
The parameter x is the number of the label that has been found. [178] x is used as a subscript to the label table to check if the value has already been entered. If forward references have occurred then labeltab[x].val will contain a pointer to the start address in the code array. [181] illustrates this mechanism and starts the search down the list to resolve the forward references. Endlist indicates the end of the list, this will be set true when a -1 is found.
[182-93] The search is performed here. The list is stored in code
and as there are two instructions to a location the code section
must be divided in two and a test made to determine which half
needs to be referenced. The list is traversed until the end is
reached at which point the label table is marked as defined and the
label value is put into the table [196]. This latter statement puts
either the PC value of the label into the table or if the label was
introducing a constant into the code then the constant value is put
into the table.
[202-21] Generate
Procedure generate is the controlling procedure. It reads the first character of each source statement and this determines one of four possible actions. This is implemented using the case statement of line [209].
[210] reads a comment line which is simply ignored.
[211] recognises labels. Label definitions may appear in two ways either as
l 3
or
l 4= 16
The first case is a simple label definition, the second case is a
means of embedding constants into the source code. [213] deals with
these possibilities, if an equals sign is present then the label
value will become the value of the constant, otherwise the current
PC value.
[217]
A line consisting of a single Q defines the end of each of the
two segments and this will flag an exit from procedure generate by
setting again to false.
[218] When a line begins with a space then a source statement is present and procedure assemble is called to load it.
[223-427] Assemble
Procedure assemble converts one source P-code instruction into obiect form which is stored in the code array.
[228-35] When a label is found in the operand field of the source instruction procedure lookup is called to either insert the reference into the forward reference list [230-2] or retrieve the label's already-defined value [233].
[237-41] Labelsearch
Procedure labelsearch is called when a label is expected as an operand. All intervening characters are taken from the prd file until a letter l is encountered and then the label number is read in. Procedure lookup is then called to insert the value into the label table.
[243-8] getname
When the start of either a mnemonic instruction code or a standard procedure is recognised the procedure getname is called to read and assemble the three characters that comprise a name into the array name.
It would be more straightforward to use name directly rather than word.
[250-64] Typesymbol
This procedure takes the c parameter and uses it to create a new
unique opcode. For example, while INCI has opcode 10, INCC becomes
opcode 94 and thus the c parameter is absorbed and the
interpreter will have no knowledge of it. Op is the opcode value
that has been found from the symbol table. Note also that although
typesymbol allows for it, some opcodes will never occur. For
example the compiler never generates INCR or INCS.
[266] The instruction opcode and parameters are initialised.
[267] Call getname to get the first instruction in the array name.
[268-70] This section is the most crucial part of the assembler as the overall performance hinges on these three statements. This is a linear search of the symbol table to identify the input mnemonic.
The input mnemonic is stored first at the end of the table by the instruction in line [268], duminst is used to access this position. The search proper is performed by the while statement - the value of op is incremented until there is a match between name and the accessed location of the symbol table. Op gives the corresponding opcode value of the input instruction. If op equals the value duminst then the instruction has not been recognised and indicates that an error has occurred in the P-code and assembly is halted.
A linear search in this context is very inefficient. To obtain a significant improvement a hashing or binary search algorithm should be used.
[272] The case statement is used to determine the parameters for each particular P-code instruction represented by the value op. The instructions do not appear in any logical order - a numerical sequence would help.
[274-87] The first cluster of instructions dealt with are the
comparison instructions. The main transformation performed here is
to change a letter, giving type information about the op, into a
number. The only exception occurs when the letter referred to is
m meaning string type and in this case the parameter q is read
and will denote the length of the strings to be compared.
[289-291] The instructions LOD and STR have basic op values of 0
and 2 respectively. The procedure typesymbol translates these
values so that there will be a unique op value for each type
i.e.
LODI 0 STRI 2 LODA 105 STRA 70 LODR 106 STRR 71 LODS 107 STRS 72 LODB 108 STRB 73 LODC 109 STRC 74
Values for p and q are obtained and give a level and an address respectively.
[293]
p and q parameters, a level and an address, are read for the LDA
instruction.
[295]
p, a level, is read for the CUP instruction. A label is also
expected and this is dealt with by a call to the procedure
labelsearch.
[297]
p, a level, is read for the MST instruction.
[299-306] This case statement deals with the instruction for return from procedures and functions. [300] is for procedures while [301-305] are function returns - one for each possible type of function value to be returned. Line [300] is an example of inconsistency: it could have been handled in a similar way to line [277] as p is initialised to zero. It is probably better to change line [277] to match this line.
[320-322] CSP (call standard procedure). This routine is used to
deal with the standard procedures, for example, WRC [623]. The for
statement removes intervening characters in the P-code statement
and the procedure getname then packs the next three characters
(which are the CSP name) into the array name. This is very
dependent on the P-code format - it would be better to program it
to skip spaces, for example
repeat read(prd , ch) until ch <> ' ';
A linear search is performed to allocate a numeric value to the q
parameter. This section is very similar to the code in lines
[267-70] but in this case you will notice that there is no check
for a nonrecognised CSP name.
[324-376] LDC (load constant). This instruction may have six
different types of parameter: these are separated by the case
statement. The p parameter is set in each case to identify the
type. Three instructions, LDCR, LDC( (for sets) and LDCI with
'large' integers, get converted into instruction 8 which is an
assembler generated instruction. This means 'load long constant',
where the parameter points to an entry in the constants table.
[325-36] Integer. After p is set to indicate an integer type the operand is read. A special process is undertaken if this value is greater than 26144 or less than -26144. This process changes the previously set opcode value now to eight and searches the constants table to find if this value has been previously referenced. The constants for large integers are stored in the array store and are pointed to by the icp pointer. This pointer is left pointing at the next free slot and so in this routine the first action is to put in the new large integer and set the parameter q to the bottom of the table [328]. The statement at line [329] increments the value of q until there is a match between the contents of the table and the value of the large integer. If when a match has been found q is the same value as the value of icp this means that the large integer has not been put into the table before. If the values are different then the large integer has already been referenced and placed in the table. In the latter case the pointer need not be changed, that is, although the large integer was placed in the table it will be overwritten when another large integer is encountered. When placing a new value into the table the pointer must be incremented [331] and a check made to see if there is any more space available: if not an error message is given (in this particular case "integer table overflow"). Line [335] deals with the case when a normal integer is encountered and here q is simply set to the value of the integer.
[338-47] Real. Similar to the treatment of large integers except that they are inserted into a separate area of the constants table.
[349]
The character N represents the nil pointer and no changes are
required to values of p and q.
[351] Boolean. Reads either zero or one to represent a boolean value for q.
[353-61] Character. The character is delimited by quotes and therefore characters are read repeatedly until a single quote character is found, the next character to be read will be used as the constant. [357] performs the reading of the constant and converts it to an integer. This is followed by checking that the second quote is present. (This is not strictly necessary.)
[362-74] Set. The set is represented in the P-code source as a
series of integers enclosed in round brackets. [362] initialises
the set variable s to the empty set. The while statement controls
the reading of the set elements which are inserted into s. After s
is complete the next six lines perform the insertion of the set
into the constants table, which is similar to [329-36]. This
completes the LDC instruction.
[378-93] CHK (check)
The CHK instruction is provided in order to include some run time
error checks. The main check ensures that the tested values lies
between a lower permissible value and an upper permissible value
i.e. the lower and upper bounds. After the procedure typesymbol is
called, the lower and upper bounds are read in. If the opcode is 95
(CHKA) only the lower bound is relevant, otherwise the boundary
values must be inserted into the constants table since they will
not both fit in the instruction.
[395-404] LCA (load address of constant)
This instruction deals with string constants. A check is made initially to ensure that space is available for the sixteen characters that comprise a string. The mcp pointer is incremented by 16 and q is set to this new value of mcp.
[400-3] These four lines load the constants table with the
characters of the string. This instruction could easily be included
as part of the LDC instruction as it is only leaving a constant in
the table and setting q to the address of the position in the
table. Note that no action is taken in this case to avoid duplicate
strings in the table.
[406]
STO (store indirect)
The procedure typesymbol is called to give a unique opcode for each
of the STO variations.
[408-9] No modification is required for the instructions listed here: none of the opcodes use the p and q parameters.
[411-2] ORD, CHR
The unconditional jump at this point means that these two instructions will not appear in the code.
[414]
UJC
This instruction is used in the implementation of the case
statement along with UJP. A table (the 'jump' table) of UJP, UJC
instructions is arranged, for example, as follows:
UJP L 3 UJP L 10 UJC UJP L 15 UJC UJP L 8
The instructions are accessed using the indexed jump instruction,
XJP. The index is simply an offset of the table above and the UJC
instructions are used as 'fillers' for those options of the case
instruction that have not been included in the source code. This
gives rise to the comment on line [414] that the implementation of
UJC must have the same length as UJP.
[418-27] At the completion of the case statement the opcode (op)
and the parameters p and q should be assigned (where relevant) and
it is in this section that these values are stored in the code
array. The PC value, which is the pointer to the code array, is
divided by two to give the offset in the with statement. The test
provided by odd on PC determines which half of the record the
instruction should be stored in.
[425]
The PC value is incremented and reading of the current P-code
statement is completed by readln(prd).
[427] This marks the end of procedure assemble.
[429-34] This is the controlling segment for the assembler. Init is called to set up the symbol tables and the pointers to the constants table. Due to the way that the P-code source is generated i.e. with the first instructions appended to the main code, it is necessary to call generate twice.
This concludes the Assembler analysis.
Pascal Implementation by Steven Pemberton and Martin Daniels
Copyright © 1982, 2002 Steven Pemberton and Martin Daniels, all rights reserved.