Bringing NewsML G2 into the Semantic Web
Authors: Raphaël Troncy, Michiel Kauw Tjoe
$Date: 2008/03/28 14:23:08 $, $Revision: 1.17 $
More and more news are produced and consumed each day.
News are still mainly textual stories, but they are more and more often
illustrated with graphics, images and videos. News can be further processed
by professional (newspapers), directly accessible for web users through news
agencies, or automatically aggregated on the web, generally by search engine
portal and not without copyright problems. For easing the exchange of news,
the International Press Telecommunication
Council (IPTC) is currently developping the NewsML G2 Architecture whose
goal is to provide a single generic model for exchanging all kinds of
newsworthy information, thus providing a framework for a future family of
IPTC news exchange standards, including NewsML, SportsML, EventsML,
ProgramGuideML or WeatherML. All are XML-based languages used for describing
not only the news content (traditional metadata), but also their management,
packaging, or related to the exchange itself (transportation, routing).
However, despite this general framework, some
interoperability problems occur. News are about the world, so their metadata
might use specific controlled vocabularies. For example, IPTC itself is
developping the IPTC News Codes
that currently contain 28 sets of controlled terms. These terms will be the
values of the metadata in the News Architecture. But the news descriptions
often refer to other thesaurus and controlled vocabularies, that might come
from the industry, and all are represented using different formats. From the
media point of view, the pictures taken by the journalist come with their EXIF metadata. Some videos might be
described using the EBU format or even with
MPEG-7.
Our goal is to bring NewsML G2 to the Semantic Web and to
show the practical added-value of these technologies for integrating
heterogeneous metadata, searching, browsing and presenting the news.
NewsML is a method/standard developed by the International Press Telecommunications Council
(IPTC) for packaging, relating, and managing diverse pieces of media. The
second generation of this standard, named News Architecture for
G2-standards (NAR), is closed to
its final development. The basic goal of NAR is to provide a single generic
model for exchanging all kinds of newsworthy information, thus providing a
framework for a future family of IPTC news exchange standards.
The IPTC also maintains a number of controlled
vocabularies, called NewsCodes,
that are used to annotate news items. These vocabularies are publicly
available and used by IPTC members as well as third parties.
The News Architecture framework (NAR) defines 4 main objects: a newsItem, packageItem, conceptItem
and knowledgeItem. Information about these structures and associated processing model can be found
in the approved package available on the IPTC web site:
http://www.iptc.org/NAR/.
NewsML-G2 specifies an extension of the generic newsItem, when this newsItem is used to
represent media objects (textual stories, images or audio clips).
The case for using Semantic Web languages (RDF, SKOS,
OWL)
The IPTC decided a few years ago that its new G2 family of
News Exchange standards must be compatible with the Semantic Web.
Particularly, it decided that:
- Terms from taxonomies used for News would be associated with individual
URIs.
- IPTC would encourage the use of GRDDL to convert News marked up with
metadata into forms understood by SemWeb tools.
Even though NewsML is formalized in UML diagrams, the
ontologization is not trivial: explain the modeling decisions; explain the
various issues (structure, CURIEs, etc.)
Issue 1: QCODES versus QNAMES
IPTC has defined the
notion of QCODE, prefix:localname which has the following
properties:
- Each coding scheme is associated with a URI. That URI must
resolve to a resource (or resources) containing information about the
scheme.
- The prefix represents the URI of the scheme within which the local part
is allocated.
- There are almost no constraints on the values of the local part. For
example, the local part (the code) is allowed to start with a digit.
- The two taken together must form a legal URI.
- This URI should provide access to a definition of the concept
represented by that code within that scheme, i.e. it is
dereferencable.
NewsML G2 examples:
<pubStatus code="stat:usable"/>
<locCreated code="city:Paris"/>
<creator code="team:DOM"/>
<subject code="cat:04000000"/>
<subject code="isin:NL0000361939"/>
<subject code="pers:021147"/>
<description role="dsc:caption">text ...</description>
Note:The tuple prefix:localname is not
identical to a compact URI; the two parts (scheme and code) each have a
meaning. This is a big difference between QCodes and CURIES, as currently
defined.
The W3C Technical
Architecture Group is currently investigating the differences
between XML QNAMEs and SPARQL Prefixed Names. Strictly SPARQL does not
use QNAMEs, however it defines a syntactically similar construct called a
prefixed name.
- The XML recommendation defines the notion of Qualified Names.
Strictly, a QNAME in XML is a
syntactic abbreviation for an expanded name comprising
{<namespaceURI>, <localname>} where
<namespaceURI> is obtained by namespace expansion of the
prefix component of a QNAME.
- The SPARQL candidate recommendation defines the notion of Prefixed
Names. SPARQL prefixed
names are abbreviations for an IRI formed by the direct concatenation
of <prefixExpansionURI><localName> where prefix
expansion resolves a prefix to an absolute IRI. A SPARQL prefixed name is
ill-formed if the corresponding IRI is not syntactically valid.
It should be noted that SPARQL is not an XML based syntax, ie. prefixed
names do not appear enclosed in either angle brackets or quotes. However,
prefixed names are considered as a feature at-risk.
The RDF-in-HTML task force has produced the CURIE: A syntax for expressing Compact
URIs working draft.
- CURIE (or Compact URI) generalizes the QNAMES approach for expressing
URIs in a generic and abbreviated syntax.
- Lax use of QNAMES (i.e. local names that are not valid XML element
names) is somehow already popular. Hence, a wiki generally transforms:
"Go and buy T. V. Raman's [[isbn:0321154991][book on XForms]]"
into "Go and buy T. V. Raman's <a
href="http://www.amazon.com/?isbn=0321154991">book on
XForms</a>".
- The main difference between CURIE and QCODE is that in the latter case,
the two parts (scheme and code) each have a meaning, while a CURIE could
be arbitrary splited into any two strings.
- Read also the
review from the
TAG on 28/03/2008.
Solution: define rules for the construction of a code URI
from the corresponding scheme URI and the code. These rules may or may not
specify simple concatenation. But then, IPTC asked if it should opt for
"#" or "#_" or "/" or "?" or
"?<foo>=" or some other string as the scheme URI terminator?
See: http://lists.w3.org/Archives/Public/public-swd-wg/2007Sep/0023.html
The SWD WG has taken this issue and will recommend a solution in Best Practice Recipes for
Publishing RDF Vocabularies that discusses the hash vs slash issues +
some Apache configuration + "303 see other" http code.
Issue 2: Reification
IPTC needs to handle statements about statements. For
example, for each piece of descriptive metadata, IPTC supports attributes
such as: creator, date modified, confidence,
relevance, why present
Thus one can, losely speaking, express:
On 7 September 2007, Reuters stated that this News item has a subject of:
- George W. Bush (with 60% confidence)
- George H. W. Bush (with 40% confidence)
Issue 3: Linking OWL with SKOS
How to define a OWL class with a restriction on values for
a property, these values being SKOS terms?
How to define a OWL class with a restriction on values for
a property, all the values must come from a SKOS Scheme?
Overview of the NewsCodes:
Latest version: version 10, Excel file of the NewsCodes schemes
See also the various XML files: are they up-to-date?
Issues:
- QCODE (see above): it is not really different from CURIE-s (which will be used in RDFa)
except for the fact that in QCODE, there is a strong requirement that all prefix URI-s should
be strictly dereferencable to something meaningful, whereas CURIE-s do not make this
requirement. Actually, unlike both QNames and CURIEs, QCodes require that both the scheme
URI and the code URI be dereferenceable.
- Long thread in the MMSEM XG (43 messages):
RE: Towards a
TAG consideration of CURIEs.
Traditional debate between the '/' versus "#' option for constructing URIs.
Interesting point from
Richard Cyganiak:
If you want to serve appropriate content to both humans and machines, you have these options
(preference is exactly in this order):
- use content negotiation and 303-redirect from the domain object's URI to HTML or RDF documents
basend on the Accept header
- 303-redirect from the domain object's URI to an HTML document and have a <link> header
pointing to the RDF document
- 303-redirect from the domain object's URI to an HTML document and use GRDDL to extract RDF
- 303-redirect from the domain object's URI to an RDF document and have a CSS or XSLT stylesheet
for a human-readable view
Using hash URIs, one can do away with the 303 redirects, which makes 2 and 3 even more appealing IMO.
EXIF: Photos come with EXIF metadata, that are
translated into RDF (Kanzaki
conversion or SWAP
conversion or JPEG
RDFizer conversion or Norman
Walsh conversion).
LSCOM: IPTC News Codes can be mapped to LSCOM
ontology, see A
Light Scale Concept Ontology for Multimedia Understanding for TRECVID
2005
WordNet: Laura Hollink has proposed a mapping
between LSCOM and WordNet.
The idea is to increase the density of the semantic graph representing all the metadata.
The case for using semantics techniques, inference and textual/image/video analysis techniques
to have more metadata and more links between the existing metadata.
Work with Krishna (QMUL) for extracting relevant low-level
features from the images and detect some semantic concepts. Ideally, provide
around 600 images (i.e. 10% of the corpus) to Krishna for the learning phase.
Base on the world cup images, Krishna thought he could automatically detect:
- flag versus non flag
- the ball
- a crowd
- a player / a team ?
- the nets
- stadium versus non stadium
- the grass
Another possibility is to apply existing Semantic Concept
detectors, coming from the TRECVid community, that will detect LSCOM
concepts.
Report on using GATE
(General Architecture for Text Engineering) for extracting named entities
(persons, organizations, places, dates, etc.) from the textual stories.
Perhaps mention the work of Victor de Boer (UvA) about
finding automatically instances of relationships based on redundancy (e.g.
find that Bill Gates is the CEO of Microsoft).
K-Space partners such as UEP and DFKI would be happy to run the SPROUT and Ex tools
on a subset of the textual stories and image captions from AFP in order to extract
named entities with their type: persons, places, events, etc.
Based on the images metadata and the textual stories (+
their metadata), how to automatically find links between them, i.e. find the
associated images of a given story. The date, named entities should be used.
We can set up experiments: the baseline would be "find the images based
solely on their metadata" (generally poor) and our contribution would be
"find the images now we have guessed the links with the stories" ... so the
textual story becomes an index for the image!
For whom, what are we trying to do would be useful to?
- Fact findings: Journalists want to find precised information about past
stories to help them writing their next article.
- Keep up-to-date: Browsing the news to get informed (overview versus
in-depth view)
- Alerts: Receive notification, news at any moment about a particular
topic. Could require some multimodal adaptation to receive the news at
any moment and any place.
The dataset from AFP we use:
| Description |
# items |
| AFP news feed in French, June and July 2006 |
59, 549 |
| AFP news feed in English, June and July 2006 |
39, 845 |
| AFP World Cup 2006 photos + NewsML2 descriptions |
3, 567 |
| AFP news feed of a normal day (14th June 2006) + photos |
235 |
Some statistics of the most used keywords in the new stories. The keywords
are extracted from the slugline.
| Top 20 for July'06 (English) |
Top 20 for July'06 (French) |
Top 20 for August'06 (English) |
Top 20 for August'06 (French) |
| Keyword |
Number Of Occurences |
| fbl |
3509 |
| wc2006 |
3162 |
| us |
2594 |
| unrest |
1845 |
| politics |
1467 |
| iraq |
1183 |
| mideast |
1148 |
| eng |
891 |
| fra |
742 |
| britain |
709 |
| tennis |
680 |
| stocks |
653 |
| iran |
632 |
| attacks |
602 |
| china |
559 |
| nuclear |
547 |
| economy |
528 |
| russia |
494 |
| eu |
487 |
| france |
485 |
|
| Keyword |
Number Of Occurences |
| foot |
4728 |
| 2006 |
4664 |
| mond |
4172 |
| hippisme |
3225 |
| usa |
2614 |
| justice |
2144 |
| sport |
1957 |
| politique |
1564 |
| fra |
1486 |
| social |
1479 |
| france |
1231 |
| irak |
1205 |
| po |
1176 |
| violences |
1141 |
| gouvernement |
1126 |
| ue |
1078 |
| presse |
1004 |
| palestiniens |
860 |
| en |
835 |
| prévisions |
825 |
|
| Keyword |
Number Of Occurences |
| mideast |
4254 |
| conflict |
2557 |
| us |
2455 |
| unrest |
2361 |
| fbl |
1488 |
| lebanon |
1257 |
| politics |
1098 |
| britain |
878 |
| nkorea |
760 |
| israel |
742 |
| fra |
735 |
| eng |
712 |
| iraq |
695 |
| wc2006 |
693 |
| missile |
661 |
| tennis |
629 |
| un |
620 |
| china |
551 |
| japan |
517 |
| cricket |
510 |
|
| Keyword |
Number Of Occurences |
| po |
4768 |
| hippisme |
3239 |
| conflit |
2989 |
| liban |
2967 |
| foot |
2909 |
| 2006 |
2822 |
| israël |
2325 |
| usa |
2223 |
| sport |
1840 |
| violences |
1800 |
| mond |
1774 |
| fra |
1589 |
| france |
1525 |
| justice |
1306 |
| social |
937 |
| cyclisme |
894 |
| onu |
888 |
| politique |
871 |
| cl |
833 |
| presse |
800 |
|
| Top 20 for 01/07/2006 (English) |
Top 20 for 01/07/2006 (French) |
Top 20 for 01/08/2006 (English) |
Top 20 for 01/08/2006 (French) |
| Keyword |
Number Of Occurences |
| us |
132 |
| politics |
91 |
| fbl |
84 |
| wc2006 |
73 |
| nuclear |
71 |
| iran |
58 |
| britain |
35 |
| unrest |
34 |
| facts |
32 |
| iraq |
29 |
| stocks |
29 |
| indonesia |
28 |
| fra |
27 |
| open |
26 |
| eng |
26 |
| quake |
24 |
| tennis |
24 |
| energy |
23 |
| un |
23 |
| afpentertainment |
22 |
|
| Keyword |
Number Of Occurences |
| usa |
139 |
| 2006 |
116 |
| justice |
113 |
| hippisme |
98 |
| foot |
94 |
| politique |
83 |
| nucléaire |
79 |
| gouvernement |
77 |
| social |
72 |
| iran |
68 |
| ue |
64 |
| mond |
63 |
| sport |
58 |
| partis |
56 |
| france |
52 |
| people |
51 |
| ps |
47 |
| roland |
45 |
| tennis |
45 |
| présidentielle |
42 |
|
| Keyword |
Number Of Occurences |
| fbl |
85 |
| wc2006 |
72 |
| unrest |
59 |
| mideast |
58 |
| us |
53 |
| eng |
49 |
| iraq |
40 |
| fra |
38 |
| wimbledon |
37 |
| tennis |
37 |
| cricket |
29 |
| politics |
26 |
| china |
26 |
| por |
22 |
| shuttle |
19 |
| bra |
19 |
| space |
19 |
| trade |
18 |
| news |
15 |
| qaeda |
15 |
|
| Keyword |
Number Of Occurences |
| 2006 |
223 |
| foot |
188 |
| mond |
164 |
| hippisme |
107 |
| fra |
90 |
| sport |
82 |
| bra |
82 |
| usa |
59 |
| israël |
52 |
| po |
51 |
| enlèvement |
48 |
| palestiniens |
46 |
| dc |
42 |
| por |
40 |
| eng |
40 |
| irak |
33 |
| en |
32 |
| cyclisme |
32 |
| offensive |
30 |
| tdf |
30 |
|
The case for using a facetted browser.
Map and Geonames: http://lists.w3.org/Archives/Public/semantic-web/2006Oct/0095.html
6 million and growing geographical features in the data base of Geonames are now described by a OWL ontology, and the RDF
description of each instance, including names, type, of course geolocation
elements, is now available through Geonames Webservice, adding to an already
impressive pack of services.
The ontology is very simple, and leverage elements of the wgs84_pos vocabulary.
The feature types are described using a simple SKOS vocabulary, which has
been embedded in the OWL ontology. If you add that, thanks to Google Maps
API, the geonames features can be created and edited through a wiki-like interface, this
as Web 2.0 as can be. Comments welcome, either here or in the Geonames
forum.
Timeline and bar histogram:
Display the amount of stories per topic and/or per unit of time (hour,day,
week, month) as a bar in an histogram chart so to see quickly what are the
hottest stories for a given period of time.
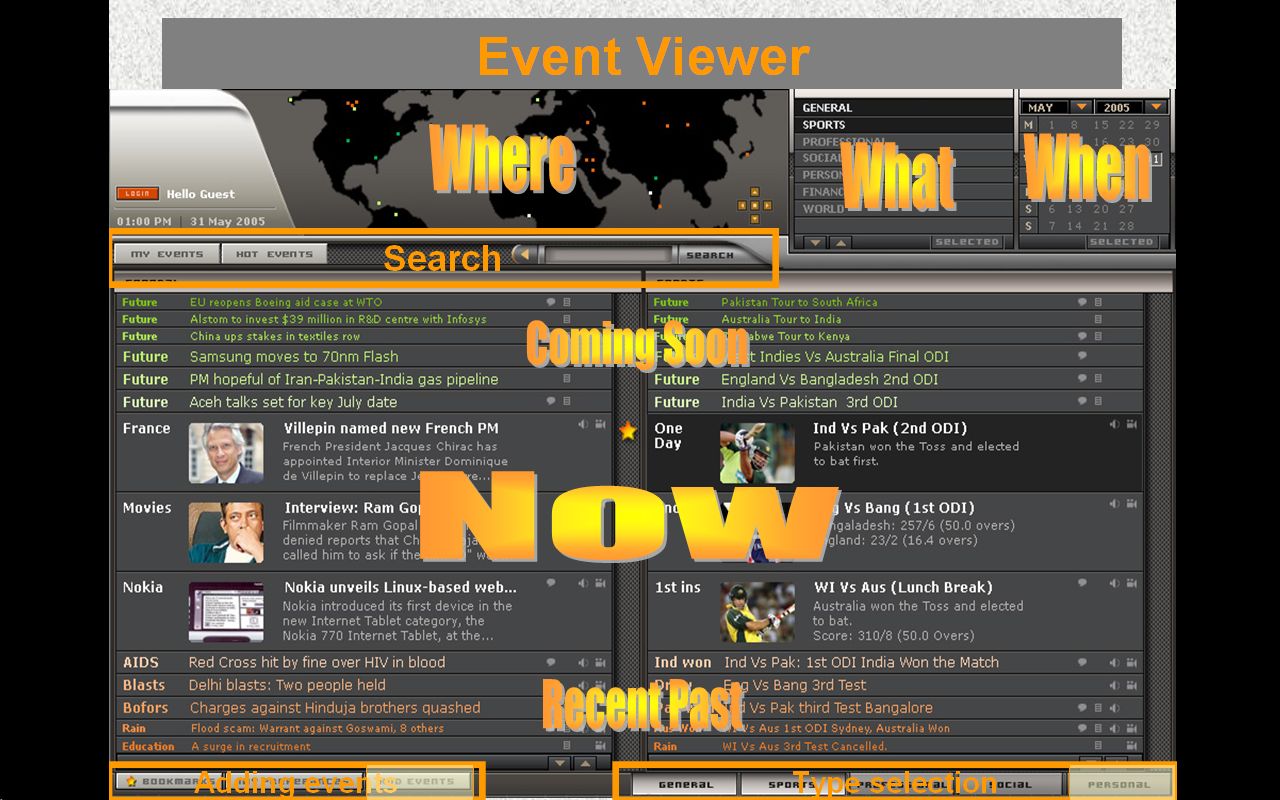
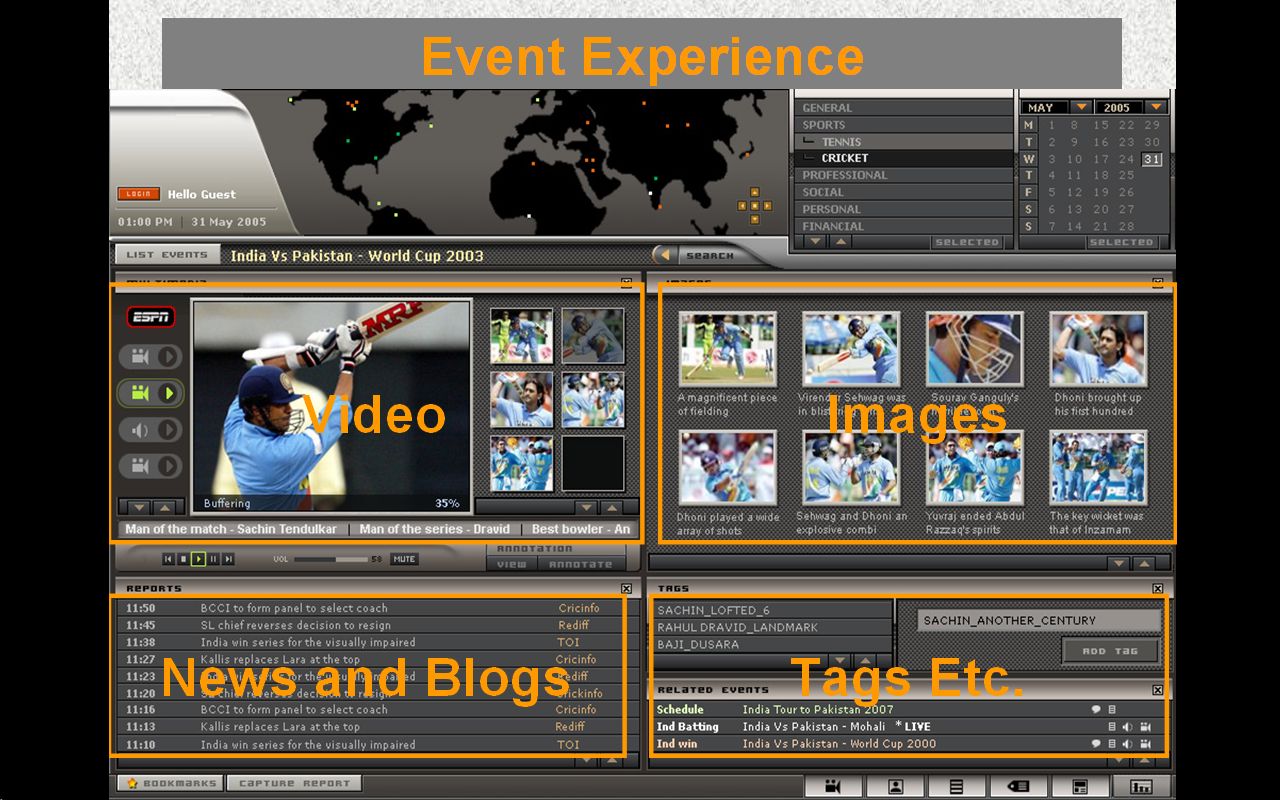
Sketch of interfaces
The final interface could be inspired by the one drawn by Ramesh Jain from his CIVR 2005 keynote
talk
What do we want to evaluate and how to evaluate it?
- The quality of the metadata: assessing the quality of the NewsML ontology,
formalizing the design choices, providing some general recommendations, etc.
- The enrichment of the metadata: how dense is the new metadata set? Set up
an experiment where the task would be to search for media on a particular topic, retrieve
the results before and after the enrichment and compare if the precision/recall increase.
- The interface for rendering the expanded metadata set: an experiment to set up could be to
i) select some images, video and texts and manually establish the list of all topics covered by this
data; ii) provide the interface to some users and ask them to browse the data during a limited period
of time for finding the media relevant to a set of topics and see whether they find all of them.
Analogy with the TRECVid interactive search task?
- P. Castells, F. Perdrix, E. Pulido, M. Rico, R. Benjamins, J. Contreras
and J. Lorés. Neptuno:
Semantic Web Technologies for a Digital Newspaper Archive. In 1st European Semantic Web Conference
(ESWC'04), pages 445-458, Heraklion, Crete, 2004.
- Norberto Fernandez Garcia, Jose Maria Blazquez del Toro, Luis Sanchez
Fernandez and Ansgar Bernardi. IdentityRank:
Named Entity Disambiguation in the Context of the NEWS Project. In 4th European Semantic Web Conference
(ESWC'07), Innsbruck, Austria, 2007.
- N. Fernández, L. Sánchez, J. M. Blázquez and J. Villamor. The NEWS
Ontology for Professional Journalism Applications. In Ontologies - A
Handbook of Principles, Concepts and Applications in Information
Systems, Integrated Series in Information Systems, Vol. 14, Springer
editor, 2007.
- N. Fernández, J. M. Blázquez, J. Arias, L. Sánchez, M. Sintek, A.
Bernardi, M. Fuentes, A. Marrara and Z. Ben-Asher. NEWS:
Bringing Semantic Web Technologies into News Agencies. In 5th International Semantic Web
Conference (ISWC'06), pages 778-791, Athens, Georgia, USA, 2006.
- Noberto Fernández and Luis Sánchez. Building
an Ontology for NEWS Applications (poster). In 3rd International Semantic Web
Conference (ISWC'04), Hiroshima, Japan, 2004.
- R. Garcia, F. Perdrix and R. Gil. Ontological
Infrastructure for a Semantic Newspaper. In 1st International Workshop on
Semantic Web Annotations for Multimedia (SWAMM'06), Edinburgh,
Scotland, 2006.
- Stephane Guerillot. News Agency needs: XML News. In Industry Forum of the 3rd
European Semantic Web Conference (ESWC'06), Budva, Montenegro, 2006.
- Luis Sánchez, Noberto Fernández, Ansgar Bernardi, Lars Zapf, Anselmo
Peñas and Manuel Fuentes. An
experience with Semantic Web technologies in the news domain. In International
Workshop on Semantic Web Case Studies and Best Practices for eBusiness
(SWCASE'05), Galway, Ireland, 2005.
- A. Sanfilippo, A. Bernardi, L. van Elst, L. Sanchez Fernandez and M.
Sintek. Integrating
Ontologies for Semantic Web Applications. In ENABLER/elsnet Workshop
International Roadmap for Language Resources, Paris, France, 2003.
- L. Zapf, N. Fernández and L. Sánchez. The
NEWS Project - Semantic Web Technologies for the news domain. In 2nd European Workshop on the
Integration of Knowledge, Semantic and Digital Media Technologies
(EWIMT'05), pages 455-460, London, UK, 2005.
- M. Naphade, J. R. Smith, J. Tesic, S.-F. Chang, W. Hsu, L. Kennedy, A.
Hauptmann, J. Curtis. Large-Scale
Concept Ontology for Multimedia. IEEE Multimedia Magazine, 13(3),
2006.
- LSCOM
Lexicon Definitions and Annotations Version 1.0 DTO Challenge
Workshop on Large Scale Concept Ontology for Multimedia, Columbia
University ADVENT Technical Report #217-2006-3, March 2006.
Data set download site: http://www.ee.columbia.edu/dvmm/lscom/
More than 10 months employed by CWI, and no single blue
note written! Am I doing research in this institute? One can indeed wonder
what I'm doing... This blue note is a tentative to answer this lack of
written traces of my research, and also, a good opportunity to guide my
thoughts. The workplan below should be materialized in one or two paper(s).
The revision 1.3 of this blue note has been discussed
during the leesklub. The impression is that this paper sounds more like an
industry paper than a research paper in the sense that it shows
how known techniques can be applied to a particular domain (news), but it
does not yet provide a real new contribution to the state of the art. The
paper could, however, be focus on different aspects of the work, and thus
highlighting possible contributions:
- The modeling decisions that need to be taken when building an ontology
for NewsML. From the UML diagrams and the schemas, one could come with
different ontologies depending on the purpose (doing consistency
checking, shaping the data for browsing and searching, etc.). Reporting
the problems found with the news domain, and possibly the e-culture
domain, and trying to generalize the solutions might be a
contribution.
- New ways of interacting with news. Currently, news are syndicated (RSS
feeds) or aggregated on portals. We should find use cases where these
interfaces are too limited. We should show why having semantic (web) data
and a facetted browser provide novel and useful interfaces for accessing
and presenting the news.
- Infering new semantic links between stories is a challenge.
Could we say that two stories are somehow related to? To which degree?
Could we measure the relatedness between news stories? How much
having semantic web data and a facetted browser help to this perspective?
This blue note is getting bigger and bigger and at least two different topics have emerged:
1. WHY and HOW getting rich semantic metadata:
2. Presenting news using rich semantic metadata:
- Hypothesis: putting all the (enriched) RDF metadata into a Mazzle-like interface will
enhance the user experience when browsing/searching news. This hypothesis is supported by
AFP that also investigates seriously how a facetted browser type of interface could optimize
journalist work when searching for particular past news.
- Questions: what kind of (generic) interface components are necessary? Timeline, Maps, etc.
- Problems:
- How to evaluate the resulting system? With which kind of users: journalist? readers?
- Possible experiment (analogy with the TRECVid interactive search task):
- i) select some images, video and texts and manually establish the
list of all topics covered by this data;
- ii) provide the interface to some users (readers) and ask them to
browse the data during a limited period of time for finding *all* the media relevant to a set of
topics and see whether they find them all.
It seems that Susanne Boll has shown in Singapore during
the CIVR 2005 conference a fun video: How Google is going to take over the
world in 2015.
On June 29th leesklub, Alia has presented the results of
her second User Study,
CH Information Seeking Task Taxonomy and Use cases.
According to Sellen, the information seeking needs can be categorized in:
- Fact findings: (or question answering) easy to process and
answer
- Information gathering: often general goals that ned to be
decomposed; the information needs to be comlete in the knowledge base
- Topic watch: (or browsing), the goal is to find "what's new in
this area"
- + Transaction and House Keeping to be complete
Alia tried to abstract some patterns from the real queries that CH people
have:
- Person - Place
- Object - Place ∧ Object - Person ∨ Person - Person
- Object - Place ∧ Object - Time
Could we do that with the top categories of NewsML too? These categories are:
Entity, Person, Organization, Geopolitical Area (e.g. point of interest),
Date
Methodology: Interview some AFP journalists in
order to know what they generally search for and see whether:
- The data we have allows to answer to the query or identify what kind of
data is missing and how could we obtain it
- The interface we have satisfies the information seeking need, i.e. the
journalist is able to formulate his query in the interface
- From the interface we have, what could be improved to better satisfy
the information need