Jacco van Ossenbruggen, Oscar Rosell and Lynda Hardman.
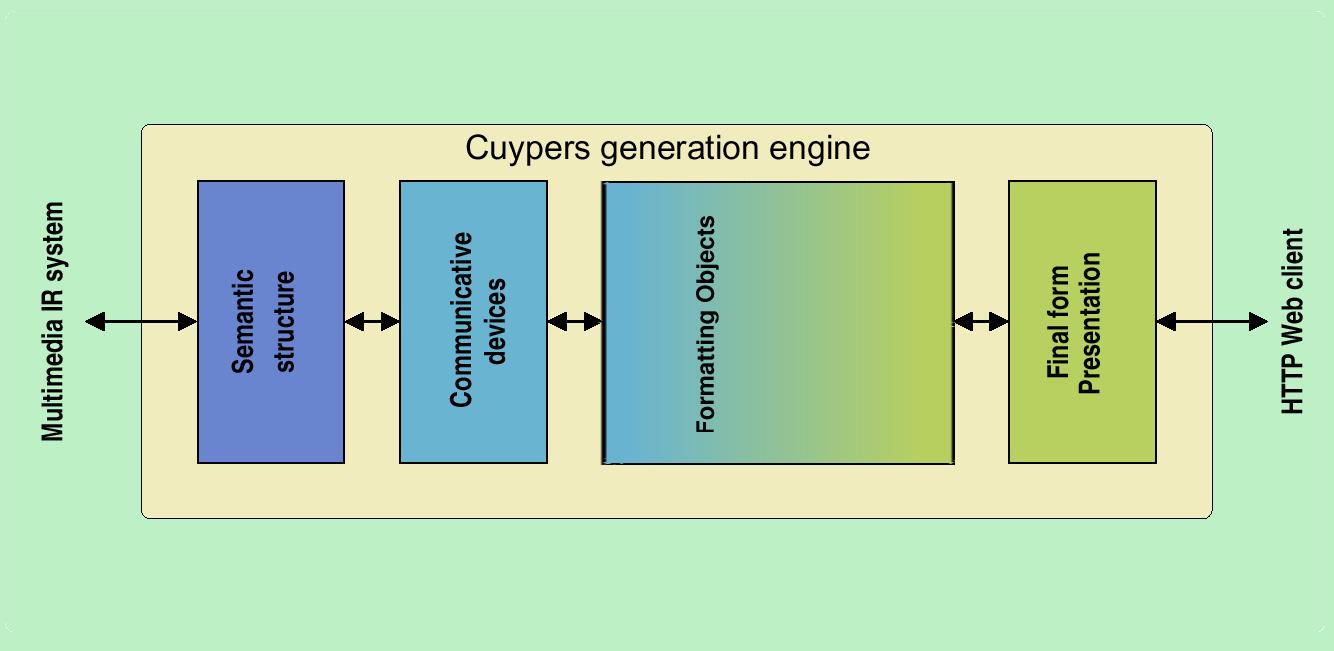
This bluenote is trying to sort out our requirements for a hypermedia formatting model. In general, a formatting model is the model that a style sheet or other transformation technique uses to describe the intended formatting of the presentation. In the context of the layers in the Cuypers system, this model should describe the abstraction level between the the communicative device level and the final presentation format. Qualitative and quantitative constraint handling (the two levels which appeared in the previous version of the architecture) is just a means of manipulating the elements in the formatting object tree and is hidden from the conceptual layering of the data-structures.
The term "hypermedia formatting model" is based on the assumption that this model should provide, in the realm of hypermedia, more or less what DSSSL's and XSL FO's formatting models provide in the realm of text.
As explained in Chapter 2.2 of Jacco's thesis, style sheet do two things intertwined:
This mix-up will become a problem in two scenarios. First, assume you have written a good style sheet, that transforms your document to SMIL. Then you decide that you need the same presentation, with exactly the same behavior and look and feel, but in a different output format, say HTML+TIME. Now you need to rewrite the entire style sheet from scratch, because your style sheet language cannot separate the "essential" design decisions from the SMIL-specific syntax details.
Second, what if the chosen target presentation format is so low-level or has such an arcane syntax (it may even be a binary format) that defining style rules in terms of this format becomes infeasible? This is the case for page-based text, where you do not want to write style sheets in terms of the individual bounding boxes of the character glyphs, or in terms of PostScript or low level TeX commands.
We are mainly interested in the second case, because it is very similar to our problem: we found that SMIL or even AHM are too low level to describe our transformation rules in terms of these models directly. So we need a convenient abstraction on top of AHM to simplify define the transformation rules.
Although our hypermedia formatting model is likely to be completely different from text, we can learn some lessons from the text case: the (implicit) formatting objects of HTML/CSS and the (explicit) formatting objects of XSL and DSSSL are all based on well-known presentation abstractions (inline/blocks, pages, floats etc) that have proved themselves in our long tradition of paper-based printing. So we could start by looking at well-known hypermedia presentation abstractions.
Be aware that the notion of an abstract formatting model is, even in text, not commonly accepted as a Good Thing. It has drawbacks as well: it is yet another abstraction you have to understand, yet another language you have to learn, and yet another level you need to process. In addition, the final presentation can only contain what can be described in your formatting model, so cool new features of the target format cannot be used unless the formatting model is updated. In addition, the fact that the formatting model itself has a serialization syntax in XML, means that formatted objects can be exchanged over the Web, and these documents contain even less semantic and structural information than HTML documents (and are thus, for example, a potential nightmare from an accessibility perspective). For example, an HTML h1 element could be formatted as an XSL FO block object with certain font properties and text-alignment properties. Exchanging such formatting objects over the Web will produce the same visual result on a standard browser, but carries insufficient information for other processing, e.g. "display" on a voice-synthesized interface, or adequate adaption on a WAP phone.
In XSL FO, formatting objects are the fundamental building blocks of the XSL formatting model. Each FO is a well-known presentation abstraction that has a set of formatting properties that define additional formatting behavior (e.g. font-family is a property of the fo:page-number object). Most formatting objects generate or return areas, where each area represents a rectangular portion of the screen/paper (actually, each area consists of three nested rectangles, the inner one contains only the content, a second one that is potentially bigger to provide padding space, and the outer one is potetially bigger to provide for border space. Finally, each FO defines the composition rules that apply to its children (e.g. "The direct children of an fo:multi-switch object are fo:multi-case objects").
Note that in DSSSL, the ISO standard for style sheet that predates XSL, this model is called a "flow object tree", or FOT (see, for example, the figure on page 33 of my thesis). Historical anecdote: years ago, in drafts of never published papers, Jacco nicknamed the hypermedia counterpart of the FOT the "HOT", or hypermedia object tree.
The current implementation is based on ad-hoc created formatting objects that basically form a tree (elements of one box are not part of another box) of 3D (x,y,t) bounding boxes, in which each atomic media item and each composite group is represented by its bounding box. At this moment, qualitative relations on three dimensions are asserted between the boxes without considering their inner structure (black boxes). The only thing we know (implicitly from the constraints set) about a box are its dimensions. The formatting objects in themselves are only used to guide the SMIL generation, but the constraint process is only based on the bounding boxes.
The boxes are created bottom-up in this way:
The set of qualitative relations asserted at every stage is determined by:
The impermeability of the boxes leads to some problems:
This is intended to become an informal list of requirements that come up during various discussions.
From Oscar's thesis draft:
We propose to make the hypermedia formating objects (HFOs) responsible for all decisions about the final format: the HFOs will define all the constraints between their children, and will also be in control of the labeling. This way, we strive for an intelligent labeling process, where the labeling algorithm can change depending on the behavior of the HFO. It will hide the constraint handling from the rest of the system.
If the HFOs describe the formatting, the designer can describe the layout of the presentation by defining the the rules that map communicative devices to HFOs and their properties. No constraints are asserted in the process.
It would be good if HFOs were able of asserting the qualitative constraints when they are related with another (sibling) HFO. This way, the object who makes the relation knows his inner state, know his children, and can transform the relation upon him in relation(s) upon his children. This should be the way to overcome the holes problem to a certain extent.
After the first set of qual. constraints are asserted, the HFOs can modify their inner configuration as long as they don't modify the size of their own bounding box.