- A BLUE NOTE -
Author: Željko Obrenović
Created: 15/05/2007
Last change: 07/07/2007
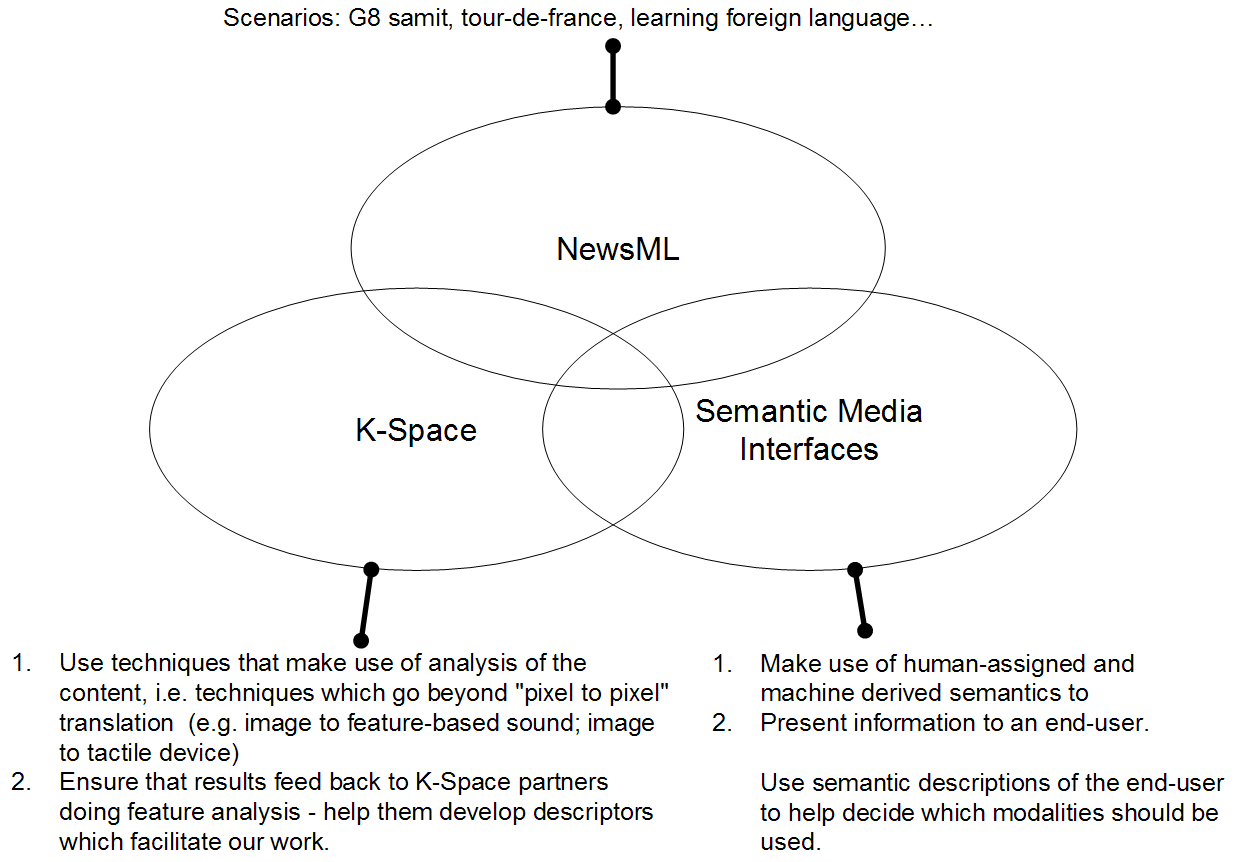
The main idea of this blue note is to try to create a synergic research proposal that combines my activities in INS2, with work in K-Space and NewsML.
Within the K-Space context, the idea is to:
Considering my work within the "Semantic Media Interfaces" group, the idea is to:
Considering the overlap with NewsML, the idea is to define common scenarios which we will address, but from different perspectives. In other words, while main activity may be interoperability of news data, or semantic search, I can add universal accessibility point of view, e.g. how to present the news having in mind situation devices and user abilities.
We present the three interaction scenarios that illustrate the requirements.
For example from real-world, see the appendix.
"Summarization" of story from diverse multimedia sources: providing coherent story within limited time, from a user point of view, with modalities appropriate for a give situation.
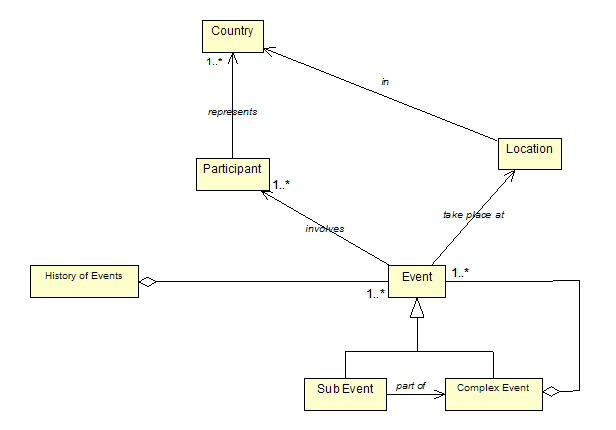
We are primarily interesting in this scenario as it would involve some of the common concepts (see the figure), that may be useful for a broader class of solutions. G8 is a complex event, composed of smaller events, including general meeting, as well as many formal and informal meeting with smaller number of participants. It involves participants from different countries, and it takes place at some location. G8 has history, and is related with other events. These concepts enables as to create different views and story lines that emphasis one of these dimensions. Someone may be interested in the event itself, other in particular participants, someone else in location and events that has take place there.
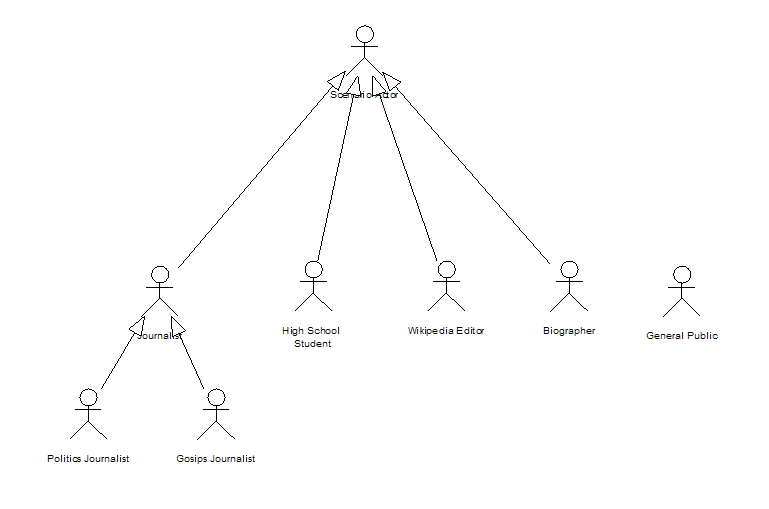
We identify several scenario actors, each one willing to get a different view on a same data about the G8 summit:
We want to support users that will use the information in different contexts:
Each of the usage context is characterized with situational and technical limitations it introduces, as well as with available interaction modalities.
This scenario illustrates how additional multimedia semantics can help users who want to follow several multimedia stream in parallel. (Relation with attention user interfaces). It illustrates the importance of annotation of high-level concepts within the streams, but also the importance of annotation of retorical structure (e.g. to identify appropriate moment to interrupt the user).
Patrick is watching the movie, but wants also to receive updates about events that are also going on, including a football match, tennis game, or bike race... He is primarily interested in watching the movie, but he would like to see the most important events from other three events (goals, break points, last part of the race or period updates about the race), and to be informed about the most important news (if any).
While watching the movie, his multimedia annotation system periodically stops the movie, enabling a user to easily change the "channel" and see the most important events in other events. His system is able to detect important events in the multimedia streams, and to present them in appropriate moments (i.e. not putting everything on one screen, with annoying animated bars). The system does it smoothly, i.e. opens a dialog space, optionally pausing the movie, asking a user about his decision (e.g. see other event, continue), and resumes the movie without to many question. The system can use different presents information visually and by speech. The updates about events are send at appropriate moments within the movie, i.e. low-level events are ignored or summarized for later presentation ignored, medium priority events are communicated between the scenes or chapters of the movie, high-priority events are communicated immediately. Information about the news are presented only if they are very important, or if they are related to the scene from the movie. For example, the scene in the movie can depict the restaurant in which Tony Blair had a meeting with the members of his party, and system can ask the usr "Did you now that at this place happened...". In the same way, other semantically rich information can be presented to the user, form other sources (Wikipedia, cultural heritage data...). As data are presented within the context and with minimal annoyance, Patrick learns many new facts with little effort.
Annotation about audio properties of the movies or audio recordings can be valuable in situations when user, due to situation, disability or device constraints cannot hear or understand spoken text or music. Typical examples include users with hard of hearing disabilities (deaf user, for example), or users in noisy situations (bar, public transport). In this section we will provide one additional scenario, where user need additional semantic about spoken text in movies due to its limited knowledge of the the language. All three types of users - deaf users, users in noisy environment, or foreign user - can profit from the same metadata. In this way we want to emphasis that metadata can have much broader scope than support for broader users.
Pierre is a French student who recently moved to the Netherlands. He has solid knowledge of English and has started to learn Dutch. To improve his Dutch learning process he thought that it would be a good idea to use his television as a media input.
In the beginning, while his Dutch was very basic, he watched the television programs using English or French subtitles. In addition, he can see the Dutch spelling of some phrases on his handheld device. His device does it by extraction phrases from the Dutch subtitles and showing that piece of content in the secondary rendering device. Pierre can also get more information about Dutch culture for selected concepts that his system gets from external services such as Wikipedia.
He can also stop the movie at particular scene, and get explanation of parts of the scene in desired language (i.e. labels associated with current elements of the scene). In this way he can associate foreign word with the context and visual images, make learning more effective.
After some time, Pierre's Dutch had improved. He still has problems to follow native speakers when they are talking, but he goes a step further and starts to watch Dutch movies with Dutch subtitles. His Dutch is still not good enough to understand everything, so from time to time he asks the system for translation of subtitles, and get it in text or speech. The system do this smoothly, e.g. it stops the playback for a few seconds, presents asked translation, and automatically continues the playback, sot that Pierre does not have to go through a sequence of actions such as pause the player, look at the dictionary, remove the dictionary, continue the playback each time he needs help. The system also memorizes selected phrases, so Pierre can later see the list of problematic phrases, and practice them again.
The system can also offer Pierre a short language test at the end of the movie, asking him phrases that were problematic for him during the movie presentation, combined with randomly selected phrases from the subtitles, and with phrases that Pierre found problematic in earlier performances.
Pierre's Dutch is getting better and better. Now he can understand lots of spoken Dutch. So his next step is to try to watch Dutch movies without subtitles. He again needs help from the system, but now his interaction with is mostly by speech. He again can get spoken translation of text, with all the benefits of the system mention earlier.
Pierre also sometimes watch Dutch movies with his friends who are also learning Dutch. Pierre's friends are from different countries, and all have different level of Dutch knowledge. The playback system also supports collaborative watching of movies with multilingual support. The movie is presented without subtitles or with Dutch subtitles (depending on who is in the room). Using their handheld devices, each of the viewers can receive original or translated subtitles, and ask for translation about present in the text. If there are more simultaneous requests for help, the system can automatically stop the playback, presenting the question on the screen, enabling viewers to shortly discuss the phrase or translation.
Other ideas:
Not sure if this can be useful, but here is the list of some scenarios from W3C's note on How People with Disabilities Use the Web:
Build on Stefano's work and look for higher level discourse that can be generated, e.g. in the news scenarios. Everyone will (soon) be able to select images related to a topic and put them together on a page (look at the Dublin CU work). Our group's added value is in the discourse generation work done by Joost, Stefano and Katya.
The link with K-Space is to use the features available from analysis to improve the building of the higher level structures. K-Space gives us the ability to "look inside" content. (how you can add extra text to an image, but not on top of faces, but in large uniform colour expanses:
Colour is another possibility. It should be fairly straightforward to convert style sheets and do colour mappings on images to make the same information easier to understand for different colour-deficits. (If these aren't available already and you can already incorporate them into a larger system.)
A (non-research) result could be a tool that, like HTML validators, validate your web page) can do two things:
The research side if finding the right colour representations and heuristics for doing the changing. Even better - use the same approach to take a news image and generate a version more appropriate for display by a tactile device. (Find a way of using K-Space work to determine the salient features to be described in semantics for
In this paper we wanted to identify key requirements for such system, proposing a more generic method for composing alternative presentation of multimedia content. Our method does not consider user disability as the only source of interaction problems, but also takes into account characteristics of task, environment and devices. Alternative presentation is presentation optimal for a situation where presenting original multimedia content is not possible, or less efficient.
Why is this important?
Number of people with disabilities is significant (about 20% of population).
Accessibility is not only about disabilities, but also about limitations imposed by context.
How can benefit?
Users (disabled, but also those that use system in suboptimal interaction conditions)
Motivation for feature extraction community (also feedback about what is needed)
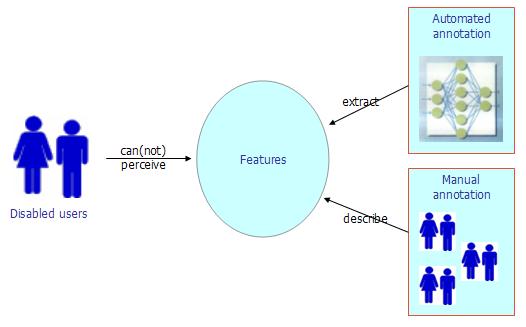
How to enable (disabled) users to understand the content of multimedia items they cannot perceive
Examples:
Feature extractors can “see” and “hear” what many people cannot
Simply listing detected features is not enough, we need to select and organize them - we need discourse structure.
It would also be really nice if you could build on Stefano's work and look for higher level discourse that can be generated, e.g. in the news scenarios. Everyone will (soon) be able to select images related to a topic and put them together on a page (look at the Dublin CU work). Our group's added value is in the discourse generation work done by Joost, Stefano and Katya (you even presented a paper last year on it!).
The link with K-Space is to use the features available from analysis to
improve the building of the higher level structures. K-Space gives us the
ability to "look inside" content. (I discussed some of this with Alia ages
ago - how you can add extra text to an image, but not on top of faces, but
in large uniform colour expanses. If you haven't read these already, then I
suggest you at least go through them quickly:
http://www.cwi.nl/~media/blue_book/alia_sd01.html
http://www.cwi.nl/~media/blue_book/sd02_formalizingdesignrules.html
Colour is another possibility. It should be fairly straightforward to
convert style sheets and do colour mappings on images to make the same
information easier to understand for different colour-deficits. (If these
aren't available already and you can already incorporate them into a larger
system.) A (non-research) result could be a tool that, like HTML validators,
validate your web page) can do two things: say for which types of colour-blindness
your web page would work and a style sheet "munger" that spits out a new
style sheet (and processes images) which are suitable for different color
deficits. The research side if finding the right colour representations and
heuristics for doing the changing.
Even better - use the same approach to take a news image and generate a
version more appropriate for display by a tactile device. (Find a way of
using K-Space work to determine the salient features to be described in
semantics for (a) translation to alternative text (b) creating a way of
describing the image to blind people (do blind
people explore tactile images in a similar way to sighted people want
semantic descriptions of images?).
The main question that we are asking is how can automated feature extraction be used to satisfy our requirements?
We need:
In this section we discuss these three issues and present some of our solutions and activities in these three directions.
Reused from the CACM paper.
Mapping to canonical processes of media production
Creating alternative presentation:
Multimedia Metadata “Guide Dog”
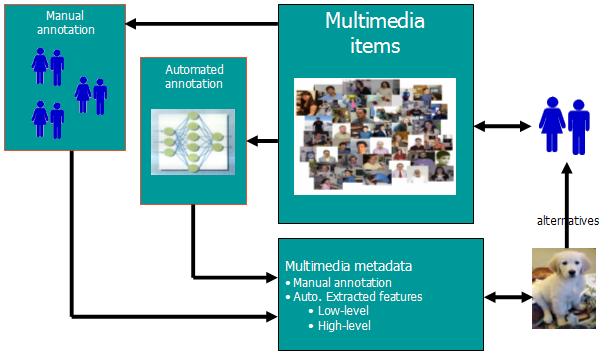
AMICO
Usage of automated feature extraction in two ways:
| Sports | Shots depicting any sport in action | |
| Entertainment | Shots depicting any entertainment segment in action | |
| Weather | Shots depicting any weather related news or bulletin | |
| Court | Shots of the interior of a court-room location | |
| Office | Shots of the interior of an office setting | |
| Meeting | Shots of a Meeting taking place indoors | |
| Studio | Shots of the studio setting including anchors, interviews and all events that happen in a news room | |
| Outdoor | Shots of Outdoor locations | |
| Building | Shots of an exterior of a building | |
| Desert | Shots with the desert in the background | |
| Vegetation | Shots depicting natural or artificial greenery, vegetation woods, etc. | |
| Mountain | Shots depicting a mountain or mountain range with the slopes visible | |
| Road | Shots depicting a road | |
| Sky | Shots depicting sky | |
| Snow | Shots depicting snow | |
| Urban | Shots depicting an urban or suburban setting | |
| Waterscape, Waterfront | Shots depicting a waterscape or waterfront | |
| Crowd | Shots depicting a crowd | |
| Face | Shots depicting a face | |
| Person | Shots depicting a person (the face may or may not be visible) | |
| Government-Leader | Shots of a person who is a governing leader, e.g., president, prime-minister, chancellor of the exchequer, etc. | |
| Corporate-Leader | Shots of a person who is a corporate leader, e.g., CEO, CFO, Managing Director, Media Manager, etc. | |
| Police,security | Shots depicting law enforcement or private security agency personnel | |
| Military | Shots depicting the military personnel | |
| Prisoner | Shots depicting a captive person, e.g., imprisoned, behind bars, in jail or in handcuffs, etc. | |
| Animal | Shots depicting an animal, not counting a human as an animal | |
| Computer,TV-screen | Shots depicting a television or computer screen | |
| Flag-US | Shots depicting a US flag | |
| Airplane | Shots of an airplane | |
| Car | Shots of a car | |
| Bus | Shots of a bus | |
| Truck | Shots of a truck | |
| Boat,Ship | Shots of a boat or ship | |
| Walking,Running | Shots depicting a person walking or running | |
| People-Marching | Shots depicting many people marching as in a parade or a protest | |
| Explosion,Fire | Shots of an explosion or a fire | |
| Natural-Disaster | Shots depicting the happening or aftermath of a natural disaster such as earthquake, food, hurricane, tornado, tsunami | |
| Maps | Shots depicting regional territory graphically as a geographical or political map | |
| Charts | Shots depicting any graphics that is artificially generated such as bar graphs, line charts, etc. (maps should not be included) |
Using WordNet and ConceptNet to get more concepts.
The problem of finding alternative ways to present "multimedia" content for users who are not able to perceive some parts of it have been subject to research for many years. Most of the existing solutions aims at creating textual representation of images, that can be read or rendered in Braille alphabet to visually impaired users. There are also alternative approach that try to create non-textual representations, and in this section we will only review these solutions.
Most of the solutions tried to solve the problem of presenting visual item for blind and visually impaired users through speech, sound (music), touch, or even smell. In this section we will review some of these solutions, starting with some real-world paper based examples, and then giving more elaborate overview of solutions for this problem in human-computer interaction field.
In this section we present some of the real-world (non-computing) examples of alternative presentation of "multimedia" items. In this overview we focus on approaches to providing alternative access to non-textual items, e.g. images , video or music, and not on text-based solutions such as audio books or screen readers, or sign language to present textual content (speech) to deaf users. We show two examples, one describing tactile images for blind users, and other usage of vibrations to present music for blind users.
Most of the real world solutions focused on providing help for blind users, mostly in form of haptic presentation of images [Kennedy91]. These solutions tried to follow the success of Braille system for haptic presentation of textual content. The most widely used form of presentation is tactile graphics. Tactile graphics are images that use raised surfaces so that a visually impaired person can feel them. They are used to convey non-textual information such as maps, paintings, graphs and diagrams. Figure 1 illustrates one such tactile graphics. It is important to note that a tactile graphic is not a straight reproduction of the print graphic, or a tactile “photocopy” of the original. A tactile graphic does not include the symbols expected by visual readers, such as color, embellishment, and artistic additions. In other words, creating tactile graphics requires lots of work, and cannot be directly created from "ordinary" image. There are many specialized organizations that publish this kind of material. Tactile graphics cannot be directly reproduced on computers, primarily due to lack of equipment such as Braille embosser that currently support only rendering of text. What makes this approach interesting is the lots of empirical evaluations and experiences about this kind of perception [Kennedy96, D'Angiulli98, Kennedy81, Keneddy96], suggesting that this kind of images give users many ability to perceive aspects of image that are primarily properties of visual perception. If computing equipment for these images appears, it could present valuable help for human-computer interaction for visually impaired users. With appropriate feedback, blind users have good ability not only to perceive but also to draw images (Figure 2).
 |
 |
| Figure 1. Example of tactile graphic, in this case a geographic map. Tactile graphics are images that are designed to be touched rather than looked at. When information in a print graphic is important to a tactual reader, a tactile graphic may be developed. The concept and content of the graphic are represented by a set of tactile symbols selected to be easily read and understood. | Figure 3. In one of Kennedy’s early studies a woman, blind from birth, drew this picture of a horse. |
Presentation of other media, such as music for deaf persons has been less explored. There are, however, some researches that suggest that deaf users can use vibrations to perceive music, in similar way how non-deaf users hear music. This technique was also used by Beethoven as he lost his hearing. Some of these studies suggest that deaf people sense vibration in the part of the brain that other people use for hearing which helps explain how deaf musicians can sense music, and how deaf people can enjoy concerts and other musical events. Users can perceive music even through ordinary speakers, but there are also experimental devices that try to render vibrations more appropriate to tactile perception, such as "Vibrato" shown in Figure 3.
|
|
|
Figure 3. Different instruments, rhythms and notes can be felt through five finger pads attached to the "Vibrato" speaker. This device is still in development. |
Although presented solution still cannot be (re)used in human-computer interaction, the main purpose of this section is to illustrate that providing alternative non-textual interaction with "multimedia" content can enable disabled users to be much more efficient and creative, and also to illustrate some of the problems that creation of such alternative content introduces.
For multimedia solutions, some of the movie theaters offer open or closed captioning and descriptive narration for blind users. Movie accessibility for persons who are blind or have low vision, or who are deaf or hard of hearing is generally provided by a system called MoPix, which has two components:
There is an alternative system called DTS Access, which provides open captions plus audio description fully compatible with the MoPix system.
Here is an article from Canada entitled Studio Gives the Blind Audio-Enhanced TV and one from the Matilda Ziegler Magazine for the Blind entitled Lights, Camera, Description! You can read a review of a reporter's experience with these two components in a Toronto Star article from last year entitled, Have You Read Any Good Movies Lately? And here's a great story on how one man convinced a local movie theater to install MoPix: Roadmap to Movie Access -- One Advocate's Journey. And Sony has even created a movie trailer with both audio description and captioning.
Following ideas from real-world solutions, researchers have been exploring approaches to design human-computer interaction solutions for interaction with multimedia content for disabled users. Existing solutions differentiate according to the type of multimedia content they present, how they use this content, and how what form of alternative interaction they offer to the users (Figure 4).
|
|
|
Figure 4. The model that we use to describe existing solutions. Existing solutions differentiate according to multimedia content they present, input they use, and what form of alternative interaction they offer to the users. |
We will present four group of these solutions:
The most widely used for of creating alternative content to multimedia content for disabled uses is HTML ALT tag. According to Web Content Accessibility Guidelines 1.0 designers should "provide a text equivalent for every non-text element (e.g., via "alt", "longdesc", or in element content). This includes: images, graphical representations of text (including symbols), image map regions, animations (e.g., animated GIFs), applets and programmatic objects, ASCII art, frames, scripts, images used as list bullets, spacers, graphical buttons, sounds (played with or without user interaction), stand-alone audio files, audio tracks of video, and video". This approach requires manual annotation of non-textual HTML content by a designer. Result of this annotation is usually one sentence describing the content of the content.
Although simple and supported by all mainstream browsers, ALT tag approach has lots of limitations, primarily rooted in the high price of maintenance of descriptions, which in the end results in the situation that most of HTML pages do not provide ALT tag for non-textual content [ref.]. To address this issues, some alternative approaches has been proposed. One of the most interesting is that taken by von Ahn et al. [von Ahn06, von Ahn04] where they introduce an enjoyable computer game that collects explanatory descriptions of images. Their idea is that people will play the game because it is fun, and as a side effect of game play we collect valuable information used to create proper explanation of the images on the Web. Given any image from the World Wide Web, their system Phetch can output a correct annotation for it. The collected data can be applied towards significantly improving Web accessibility. In addition to improving accessibility, Phetch is an example of a new class of games that provide entertainment in exchange for human processing power. In essence, they solve a typical computer vision problem with HCI tools alone.
There where some work to create ALT tag text (semi)automatically. Bigham et al. proposed a WebInSight, a system that automatically creates and inserts alternative text into web pages on-the-fly. To formulate alternative text for images, they use three labeling modules based on web context analysis, enhanced optical character recognition (OCR) and human labeling. The system caches alternative text in a local database and can add new labels seamlessly after a web page is downloaded, trying to minimize impact to the browsing experience.
Regardless of how it is created, alternative text is used primarily for visually impaired user usually through text-to-speech engines that read the text when user opens a page, or when it jumps from one elements to the other using keyboard tab interaction. Alternative text can also be useful for non-disabled users, when, for example, due to low-bandwidth or limitation of the device, they cannot see the image. In that case the browser can render the ALT text in the box where usually the image would be shown.
For deaf users, the most common form of annotation are subtitles for movies and lyrics for music [ref.].
Content such as images and video are hard to use directly as they are represented at too low level, such as pixel, and usually it is hard to get any meaning of this content without annotation or sophisticated computing processing. Content that is described at higher-level of abstraction, such as vector graphics, however, provides much more information as they use primitives at much higher level of abstraction. New vector graphics formats also enable adding explicit semantic about the graphics. Herman and Dardailler, for example, proposed an approach to linearization of Scalable Vector Graphics (SVG) content. SVG is a language for describing two-dimensional vector and mixed vector/raster graphics in XML. They introduce a metadata vocabulary to describe the information content of an SVG file geared towards accessibility. When used with a suitable tool, this metadata description can help in generating a textual (“linear”) version of the content, which can be used for users with disabilities or with non-visual devices. Although they concentrate on SVG, i.e. on graphics on the Web, the metadata approach and vocabulary presented below can be applied in relation to other technologies, too. Indeed, accessibility issues have a much wider significance, and have an effect on areas like CAD, cartography, or information visualization. Hence, the experiences of the work presented below may also be useful for practitioners in other areas.
W3C also created a note about the accessibility features of Scalable Vector Graphics (SVG).
In comparison with visual media, which have been extensively explored, non-speech use of the auditory medium has been largely ignored. The use of audio in human computer interfaces was first reported by Bly. Gaver has proposed the idea of Auditory Icons [3] and used them in the SonicFinder [4] to assist visually impaired users with editing. Such auditory icons are short bursts of familiar sounds. Edwards has developed the Soundtrack system [5] to assist blind users in editing. Blattner an co-workers has proposed the use of musical phrases called Earcons [6] - short musical melodies which shared a common structure such as rhythm. However, apart from suggesting the idea of sharing a common rhythm, no other musical techniques were suggested. Blattner has also used some properties of musical structures to communicate the flow in a turbulent liquid. During the last few years, some research workers have attempted to use music in interfaces. Brown and Hershberger [7] employed music and sound in supporting the visualization of sorting algorithms but carried out no experimentation to see how valid their approach was. Alty IS] has developed purely musical mappings for the Bubble Sort and the Minimum Path Algorithms. Recently some progress has been made in assisting program debugging using music, for example, the work of Bock [9] , and Vickers and Alty [IO] There are very few recorded experiments which systematically evaluate the use of music in human computer interaction. Brewster [l l] has used music to a limited extent in designing Earcons for Telephone based interfaces and has combined Earcons with graphical output to assist users when making slips in using menus [ 121. In both cases some empirical investigations were carried out. Mynatt has investigated the 1133 mapping of visual icons into auditory Earcons. She comments on the importance of metaphorical qualities of everyday sounds and how these can be used in designing good Earcons. Alty et al. shown that the highly structured nature of music can used successfully to convey graphical information diagrams to visually challenged users [Alty98]. They developed AUDIOGRAPH - a tool for investigating the use of music in the communication of graphical information to blind and partially sighted users. Their experiments also reported that context does indeed seem to play an important role in assisting meaningful understanding of the diagrams communicated.
Schneider, J. and Strothotte, T. 2000. Constructive exploration of spatial information by blind users. In Proceedings of the Fourth international ACM Conference on Assistive Technologies (Arlington, Virginia, United States, November 13 - 15, 2000). Assets '00. ACM Press, New York, NY, 188-193. DOI= http://doi.acm.org/10.1145/354324.354375
Some approaches use the content directly at pixel level, exploiting low-level features of the content. We will describe some two of these solutions in context of sonification of images and visualization of music. Pun et al. proposed an image-capable audio Internet browser for facilitating blind user access to digital libraries [Pui98]. Their browser enable user to explore the image where they create a composite waveform as a function of the attributes of the touched pixel. In their prototype, sound is function of the pixel luminance. They also map the pixel position (x, y) to map the image to the virtual sound space.
Kamel, H. M. and Landay, J. A. 2000. A study of blind drawing practice: creating graphical information without the visual channel. In Proceedings of the Fourth international ACM Conference on Assistive Technologies (Arlington, Virginia, United States, November 13 - 15, 2000). Assets '00. ACM Press, New York, NY, 34-41. DOI= http://doi.acm.org/10.1145/354324.354334
Kamel, H. M. and Landay, J. A. 2003. Sketching images eyes-free: a grid-based dynamic drawing tool for the blind. In Proceedings of the Fifth international ACM Conference on Assistive Technologies (Edinburgh, Scotland, July 08 - 10, 2002). Assets '03. ACM Press, New York, NY, 33-40. DOI= http://doi.acm.org/10.1145/638249.638258
Solutions for deaf users have been less explored. Music visualization was, however, explored as an approach to making music accessible to deaf users. Music visualization is a feature found in some media player software, generates animated imagery based on a piece of recorded music. The imagery is usually generated and rendered in real time and synchronized with the music as it is played. In this case, music visualization system translates directly low level features of music content into animated and mostly abstract scene.
In general, we can identify three cases where the computer can use tactile support for blind people when they interact with representational graphics [Kurze]:
Currently, three major computing technologies for tactile image presentation exist: Pin-matrix devices display the actual image rasterized with a more or less low resolution (and at an extremely high price)[9, 10]; 2D-force-feedback devices can present a virtual line drawing for one finger [8]; various off-line displays can produce raised line drawings which can then be put on a touch tablet and explored. The raised line drawings give the most detailed tactile perception of line drawings. Unfortunately they are "hard copies" and thus cannot be changed online. Exploration can be supported, if a database has information about the objects in the image: The image is put on a touch tablet, and the database "knows" which object is displayed at each place of the image. When the user wants to get details about a certain object he or she can press on it and gets the information via speech output from the computer [4, 6]. Currently the database is used only to present information about the object at the current finger position. It is not possible to "highlight" random areas. Thus a user can not be guided to a specific position. Some experiments with spoken hints ("go left, go up, ...") have been carried out but were not very successful.
Kurze develop TGuide - a guidance system for blind people exploring tactile graphics. The system is composed of a new device using 8 vibrating elements to output directional information and a guidance software controlling the device. Wall and Brewster developed Tac-tiles [Wall06] - an accessible interface that allows visually impaired users to browse graphical information using tactile and audio feedback. The system uses a graphics tablet which is augmented with a tangible overlay tile to guide user exploration (Figure #). Dynamic feedback is provided by a tactile pin-array at the fingertips, and through speech/non-speech audio cues. In designing the system, they wanted to preserve the affordances and metaphors of traditional, low-tech teaching media for the blind, and combine this with the benefits of a digital representation. Traditional tangible media allow rapid, non-sequential access to data, promote easy and unambiguous access to resources such as axes and gridlines, allow the use of external memory, and preserve visual conventions, thus promoting collaboration with sighted colleagues.
|
|
|
Figure #:
Prototype Tac-tiles system. Graphics tablet
augmented with a tangible pie chart relief, |
Most of the work for making multimedia accessible focused on helping creating captions and audio descriptions for multimedia content. The Carl and Ruth Shapiro Family National Center for Accessible Media (NCAM) developed several tools to help developers of Web and CD-ROM based multimedia making their materials accessible to persons with disabilities. They experimented with Apple's QuickTime (TM) software, Microsoft's Synchronized Accessible Media Interchange (SAMI) format, the World Wide Web Consortium's (W3C) Synchronized Multimedia Integration Language (SMIL), and WGBH's MAGpie authoring software. Their Media Access Generator (MAGpie), for instance, is an authoring tool for creating captions and audio descriptions for rich media.
Most of interaction with alternative content is passive or use very simple interaction. For example, screen readers read the Web page linearly when the user follows the link, read ALT tags when the image or other element is in focus, for example, when user jumps ion it with tab key. For communicating more complex information, especially if they convey spatial data, more interactive and explorative interfaces have been proposed. Most widely used interaction modalities include text-to-speech synthesis, Braille printers, different forms of visualization. There are, however, experimental systems that explore other possibilities. Researchers at the University of WisconsinMadison are developing the tongue-stimulating system, which translates images detected by a camera into a pattern of electric pulses that trigger touch receptors (Figure 5). The scientists say that volunteers testing the prototype soon lose awareness of on-the-tongue sensations. They then perceive the stimulation as shapes and features in space. Their tongue becomes a surrogate eye. Earlier research had used the skin as a route for images to reach the nervous system. That people can decode nerve pulses as visual information when they come from sources other than the eyes shows how adaptable, or plastic, the brain is. This research is still very experimental, and under development.

 |
 |
|
Figure5a. At the end of a flexible cable pressed against the tongue, an array of dotlike metal electrodes (right) stimulates touch-sensitive nerves with electric pulses. Patterns of pulses represent images from a video camera (not shown). |
Figure5b. Blindfolded but tongue-tuned to a video camera (white box beside laptop), Alyssa Koehler mimics hand gestures by Sara Lindaas. These sighted, occupational-therapy students are part of a team devising a curriculum to train blind children to use the image-translating system. |
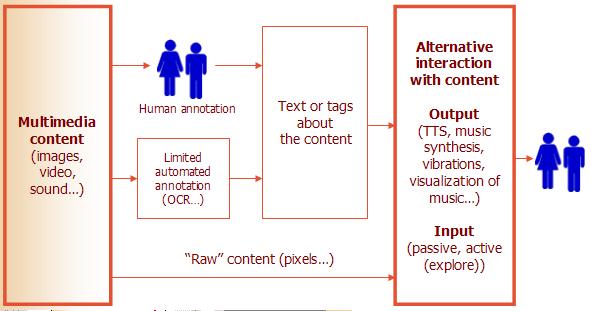
Most of existing solutions addressed providing alternative presentation for images, with limited work for videos and sound. Some of the solutions used content directly, for example, sonifying pixels, other solutions used annotation created by users or through limited automated recognition, such as optical character recognition (OCR). In most cases, this annotation is simple text, or list of tags about the content. For creating alternative output, existing solutions used different output modalities, such as speech synthesis, music synthesis, and vibrations for blind users, or different visualization techniques for deaf users. User input can be classified as passive or active. In active mode users where able to explore the content to perceive it, while passive input present the content linearly, with limited user interaction.
Critiques:
In all these cases, semantic information (e.g. object names) supports the drawing. This semantic information is in most cases added to the drawing by (sighted or blind) people. Attempts have been made to automatically extract this semantic information from the image or from the underlying spatial model. The semantic information is then used to passively support the blind person perceiving the image: Whenever she or he wants to know what is under her or his finger, this information can be made available. However this functionality is limited in a number of aspects: It is not sure whether all relevant objects in the drawing are found by the blind person, since the tactile image perception is more or less limited to the area covered by the fingertips sequentially. There is no such thing like a "tactile overview" which would be comparable to the sighted persons' capability to see the whole picture at once. Thus the blind person could miss important Features of the drawing while he sequentially explores it. People often search objects in the image. This is for example the case when the image is referenced in a surrounding text. While sighted people can scan an image quite fast and find the object they are looking for, blind people need much more time to do this. They often would like to ask "where is ..." and then explore the object independently. Since tactile image perception is a sequential process, the order in which the objects are explored might be important to support recognition. If the blind person explores an image alone he or she might choose an inappropriate exploration path and come to incorrect hypotheses about the image or might even end up completely confused. This enumeration shows that a navigation aid for tactile images for blind people is needed. This aid should propose a direction for the exploring finger(s) to move to and it should guide the blind person during the exploration.