Canonical Process of Media Production
Canonical Process of Media Production
Lynda Hardman, Frank Nack, Zeljko Obrenovic, Brigitte Kerherve, Kurt
Piersol
This is the current version of the model. You can also see
the previous version (26/07/2006).
Abstract
Creating compelling multimedia presentations is a complex task. It involves
the capture of media assets, then editing and authoring these into one or more
final presentations. Tools tend to concentrate on a single aspect of media
production to reduce the complexity of the interface and to simplify
implementation. Very often there is no consideration for input requirements of
the next tool down the line. While these tools are tailored to support a
specific task, they have the potential for adding semantic annotations to the
media asset, describing relevant aspects of the asset and why it is being used
for a particular purpose. These annotations need to be included in the
information handed on to the next tool.
In this paper, we identify several fundamental processes of media production,
and specify inputs and outputs to a number of these canonical processes. We do
not specify the intricate workings of the processes, but concentrate on the
information flow between them. By specifying the inputs and outputs required for
processes that occur in widely differing uses of media we can get a unified view
of the media production process and identify a small set of building blocks that
can be supported in semantically aware media production tools.
Introduction
There is substantial support within the multimedia research community for the collection of machine processable
semantics during established media workflow practices [3, 4, 7, 8, 10]. An essential aspect of
these approaches is that a media asset gains value by the inclusion of information about how or when it
is captured or used. For example, metadata captured from a camera on pan and zoom information can
be later used for the support of the editing process [2].
Though the suggested combination of description structures for data, metadata and work processes
is promising, the suggested approaches share an essential flaw, namely that the descriptions are not
sharable. The problem is that each approach provides an implicit model for exchanging information
that serves the particular functionality and process flow addressed by a particular environment. The
situation is similar to data formats with included metadata, such as the
mov or
XMP formats, where
the combination of features hinders general exchange when the application does not support the features
supported by the data format.
Our aim here is to establish clear interfaces for the information flow across processes among distinct
production phases so that compatibility across systems from different providers can be achieved. We
see this as a first step towards a longer term goal — namely, to provide agreed-upon descriptions for
exchanging semantically annotated media assets among applications.
The processes should not be viewed as prepackaged, ready to be implemented by a programmer. Our
goal is rather to analyse existing systems to identify and generalize functionality they provide and, on
the basis of the processes supported within the system, determine which outputs should be available
from the system. In this sense, we hope that system creators will be open to providing the outputs we
identify when the processes are supported within the system. We hope that in this way the multimedia
community will be able to strengthen itself by providing not just single process tools, but, in the same
way that the pipe was so important in the evolution of UNIX, allow these to belong to a (global) suite
of mix and match tool functionality.
In this paper we derive the requirements for describing a single process, then identify and describe a
number of processes we see as being canonical to media production.
Modeling Framework
An important requirement for the description of the processes is to
ensure that the description details only the process taking place and
is independent of whether the process can, or should, be carried out
by a human or a machine. This allows for a gradual shift of the
processing burden from human to machine as the technology develops.
In addition to a description of the process, we also need clear
specifications of the inputs and outputs to the process.
To formally describe processes of media production, we will use Unified Modeling Language (UML).
UML is a widely adopted standard,
familiar to many software practitioners, widely taught in undergraduate courses,
supported by many books, and training courses. In addition, many tools from different
vendors support UML. By using UML, we also wanted to make easier use of multimedia
knowledge for ordinary software engineers.
Firstly, we describe the metamodel that was used to define a vocabulary of modeling primitives used to describe media production processes. Then, we describe UML extension defined based on this metamodel, used to model canonical processes.
The Metamodel
In order to define models of multimodal user interface, we need a vocabulary of modeling primitives.
Here, we define a metamodel where we have formally described basic concepts of media production processes.
|

Figure 1. The metamodel of canonical processes of media production. |
In our metamodel media production processes can be complex or basic (Figure
1a). A complex media production process is composed of several basic or complex
processes. Each basic media production process is defined by (Figure 1b):
- Input that it receives from the real world, such as thoughts of the
authors, or user input,
- Input that it receives from other processes, such as metadata or
captured media,
- Process and real world artifacts it produces, and
- Actors that it involves, such as editor, or operator. Actor can
also be some other system or a piece of software.
Output of each process can be the input for other processes, while some
processes, such as premeditation, receive input only from the real world. An
artifact produced by processes can be simple, or composite. Simple or basic
artifacts we classify as:
- Media assets, such as captured video or images, usually it contains
"raw" data recorded with some sensory technology, such as camera or
microphone, but it can also be a product of generation of programs such as 3D
studio, or result of transformation of some of the existing media assets
- Annotation, any semantic information that could be pertinent to the
media asset, whether denotative or connotative, such as, description of what
is represented in the media asset, or how the media asset is created. Subject
of metadata can be any process artifact (or part of artifact identified by an
anchor [5, 6]), including other metadata. Optionally, metadata can be based on
terms defined by some schema (e.g. in MPEG-7 [9] or OWL [13]). We make no
restrictions on the semantics.
- Structural assets, such as SMIL presentations that do not create
new media artifacts, but structurally organize existing material. Structural
asset usually contains links to other process artifacts.
Composite asset is created from other basic or composite artifacts.
UML Extensions
UML is a general-purpose modeling language, which includes built-in facilities that allow customizations
or profiles for a particular domain. A profile fully conforms to the semantics of general UML but specifies
additional constraints on selected general concepts to capture domain-specific forms and abstractions.
UML includes a formal extension mechanism to allow practitioners to extend the semantics of the UML.
The mechanism allows us to define stereotypes, tagged values and constraints that can be applied to
model elements. A stereotype is an adornment that allows us to define a new semantic meaning for a
modeling element. Tagged values are key value pairs that can be associated with a modeling element that
allow us to ”tag” any value onto a modeling element. Constraints are rules that define the well-formedness
of a model. They can be expressed as free-form text or with the more formal Object Constraint Language
OCL. In this paper, we describe only stereotypes we use.
We define a new UML profile where we introduce several UML extensions based on the proposed
metamodel. With these extensions, we can describe a processes of media production at di
erent levels of
abstraction, with various levels of details. Table 1 shows some of introduced UML class and association
stereotypes. In next section, we will use these stereotypes to describe each of identified media production
processes.
Table1. UML stereotypes used to describe processes of media production.
| Name | Type | Description |
| <<process>> | package stereotype | Package all elements of process description. |
| <<process>> | class stereotype | Describes a process. |
| <<complex process>> | class stereotype | Describes a complex process. |
| <<media asset>> | class stereotype | Described a media asset as a basic artifact. |
| <<structural asset>> | class stereotype | Describes a structural asset as a basic artifact. |
| <<annotation>> | class stereotype | Describes a metadata as a basic artifact. |
| <<composite artifact>> | class stereotype | Describes a composite artifact. |
| <<process actor>> | class stereotype | Describes a process actor. |
| <<external world artifact>> | class stereotype | Describe entities from external world. |
| <<input>> | association stereotype | Connects processes with input artifacts. |
| <<output>> | association stereotype | Connects process with output artifacts. |
| <<link>> | association stereotype | Connects structural asset with linked artifacts. |
Canonical Processes of Media Production
Our modeling framework defines a generic approach for modeling media production processes, where actual modalities are described
with UML models defined by extensions explained in the previous section. We identify nine processes based on examination of existing
multimedia systems:
- premeditate,
- create,
- annotate,
- package,
- query,
- construct message,
- organize,
- publish, and
- distribute.
We give an explanation of what they are and state their inputs and outputs. A preliminary, less formal, diagram can be found at the
Dagstuhl web site.
While we use single words to name each of the processes, these are meant to be used in a very broad sense.
The textual description of each one should give a flavour of the process we wish to express. We refer to the processes by means of the single name.
Premeditate
Any media capture occurs because someone has made a decision to embark
on the process of capturing - whether it be image capture with a
personal photo camera, professional news video, Hollywood film or
security video in a public transport system. In all cases there has
been premeditation and a decision as to when and for how long capture
should take place.
In all these cases what is recorded is not value-free. A decision has
been made to take a picture of this subject, conduct an interview with
this person, make this take of the chase scene or position the
security camera in this corner. Already there are many semantics that
are implicitly present. Who is the "owner'' of the media to be
captured? Why is the media being captured? Why has this
location/background been chosen?
Whatever this information is, it should be possible to collect it and
preserve it and be able to attach it to the media that is to be captured.
For this we need to preserve the appropriate information that can, at
some later stage, be associated with one or more corresponding media
assets.
The input to this process is from without the system. The output is a set of
premeditate annotations (preID), with no
associated media asset. Figure 2 shows a UML class diagram of the premeditate
process described in the terms of the proposed metamodel.
|
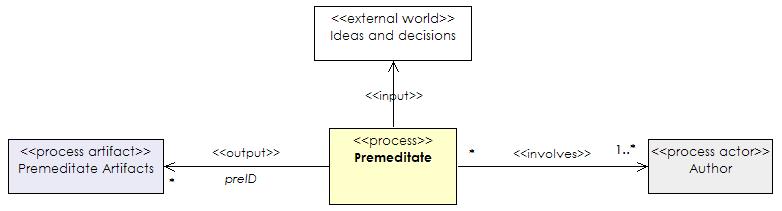
Figure 2. A class diagram describing a premeditation process. |
Create Media Asset
After a process of premeditation, however short or long, at some point there
is a moment of media asset creation. Some device is used to collect images
or sound for a period of time, be it photo or video camera, scanner, sound
recorder, heart-rate monitor etc.
Note that in this process, we do not restrict capture to only purely recorded
information. Media assets can also be created in other ways. For example, images
can be created with image editing programs or generated by computer programs.
What matters is that a media asset comes into existence, we are not interested
in the method of creation per se. If the method is considered as significant,
however, then this information should also be able to be recorded as part of the
metadata.
In summary, the input to the capture process is a collection of metadata, for
example information available from the premeditation process (preID),
and/or the message construction process (messID).
As a result of the capture process we have media assets (medID),
associated information about the capture and/or creation process (capID)
plus the associated information given as input (preID
and messID). This process usually involves one
or more capturing operators, and often an editor that overlooks capturing
process. Figure 3 shows a UML class diagram of the create media asset process
described in the terms of the proposed metamodel.
|

Figure 3. A class diagram describing a capturing process. |
Annotate
Once a media asset exists and has been included in an archive we still need
to be able to add extra information about it. This may include information that
could have been collected during the premeditation, message construction or
capture processes, but is added later. Any information added does not change the
original media asset.
We do not prescribe the form of annotations, but require that they can be
created and associated with one or more media assets. The structure of an
annotation often consists of a reference to a vocabulary being used, one of the
terms from the vocabulary plus a value describing the media asset (this may or
may not have an ID). The annotation can refer to the complete media asset, but
the annotation could be more specific. In this case, an anchor mechanism is
needed to refer to the part of the media asset to which the annotation applies
[5]. An anchor
is sometimes needed to give a media independent means of referring to the part of the
media asset and a media-dependent anchor value is required to specify the part
of the media asset. For example for an image this could be an area, for an
object in a film a time-dependent description of an area of the image. For
further discussion on anchor specifications see [6] p53.
We use the term annotation, but wish to emphasize the breadth of our intended
meaning. Annotation is often used to denote a single human user adding metadata
to enable search at some later date. Here we see annotation as the broader
process of adding partial (more easily machine-processable) descriptions of the
content of the media asset. The annotation process can never be complete, since
different aspects of the media asset may be made explicit in different contexts.
The description assigned to it, however, can be viewed as providing "potential
for organisation'', or as a step prior to a cataloguing step.
How the annotations are created is not of essence to the process description:
they may be human-created or automatically generated, for example, from feature
extraction processes. The meaning of the attribute can be obtained through its
association with the ontology (recorded in the attribute). The value of the
annotation may be one of those specified for the attribute. For example, for the
attribute "modality'' a value may be "spoken language'' or "sound effect''. The
value may also be numeric, for example for the attribute "colour'', in which
case the units need to be specified. (Note that specification methods already
exist [12].)
Note also that the annotations may not be explicitly assigned by a user, but may
be assigned by an underlying system through interaction by the user with the
media asset. The information gained in this way should be treated on an equal
footing with the information assigned by a human user --- the difference being
that different values for the "assigner'' (if this is deemed significant) would
indicate the difference. The "assigner'' would be one of the attributes from the
annotation ontology.
Note that we make an explicit distinction between the process of associating an
annotation with a media asset and archival of a media asset. The former
associates information with the media asset. The latter allows the media asset
(along with its associated annotations) to be located from a repository of
components.
The input to the annotation process is a set of media assets and annotations.
The output contains the same annotations plus the additional annotations.
Annotation contains a reference to used schema (ontID)
and potentially a reference to a used value. It involves one or more human or
computing annotators. Figure 4 shows a UML class diagram of the annotate process
described in the terms of the proposed metamodel.
|

Figure 4. A class diagram describing an annotation process. |
Package
The process of packaging is that of grouping a media asset plus existing
associated annotations, and assigning this grouping an identity so that it can
be retrieved as a unit. The input to the packaging process is any process or
real world artifact, such as a set of media assets plus the associated set of
annotations. The output of the process is a multimedia package with identity
plus the identity.
The multimedia package is equivalent to the component
identity specified in hypertext literature [5, 6]. We distinguish two types of
package process: physical packaging, such as archiving a movie to a file, or
putting annotation in the database, and logical, such as associating media
assets with annotation. For example, SMIL presentation is one logical unit that
aggregates many media items, i.e. it presents one logical package, but
physically SMIL document and media items are packaged in separate files, often
in a distributed environment. Figure 5 shows a UML class
diagram of the package process described in the terms of the proposed metamodel.
|
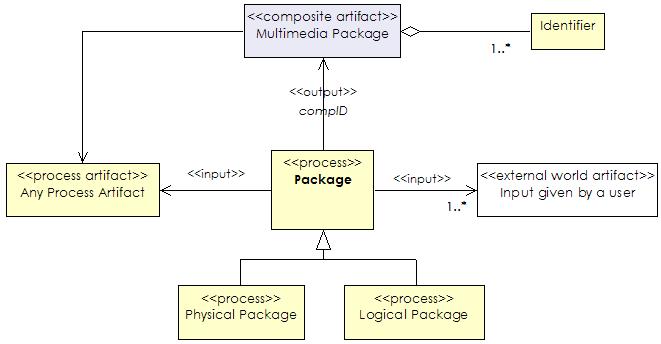
Figure 5. A class diagram describing a packaging process. |
Query
Up until now the processes we describe concentrate on capturing, storing and
describing media assets. These are needed for populating the media repository.
Once there is an archive of packages (but not before) it can be queried for
components whose associated media assets correspond to desired properties.
Again, we do not wish to use a narrow definition of the term “query”, but intend
to include any interface that allows the archive to be searched, using query
languages of choice or (generated) browsing interfaces that allow exploration of
the content of the archive.
Any query of the system may be in terms of media assets, or in terms of any
of the annotations
stored with the media assets. A query would need to specify (indirectly) the annotation(s) being used and include techniques such as query by
example themselves are not important for the identification of the process.
The input to the query process is an archive of media components plus a
specification of a subset of these. The output is a (possibly empty) set of
identified media components corresponding to the specification. Note that the
output is not a set of media assets, but a structural asset that include
references to the media components that contain links to media assets.
Figure 6 shows a UML class diagram of the query process described in the terms
of the proposed metamodel.
|

Figure 6. A class diagram describing a querying process. |
Construct Message
A query implicitly specifies a message, albeit a simple one, that an author
may want to convey (since otherwise the author would not have been interested in
finding those media assets). The query is, however, not itself the message that
the author wishes to convey. Just as capturing a media asset is input into the
system, so is the specification of the message an author wishes to convey. In
some sense, there is no input into the process. However, the real input is the
collection of knowledge and experience in the author her/himself. The output of
the process is a description of the intended message, whether implicit or
explicit, to either an author or the system. For example, a multimedia sketch
system such as described in [1] allows an author to gradually build up a
description of the message. For the message to be machine processable the
underlying semantics need to be expressed explicitly.
While we do not exclude this process as being carried out by a system, we
expect that, at least in the near future, it will predominantly be carried out
by a human user. In general, we give no recommendation in this paper for the
syntax of the message. We expect that it contains information regarding the
domain and how this is to be communicated to the user, but we do not assign
anything more than a means of identifying a particular message. The input to the
process is thus from outwith the system and the output is a a message (messID).
Figure 7 shows a UML class diagram of the construct message process described in
the terms of the proposed metamodel.
|
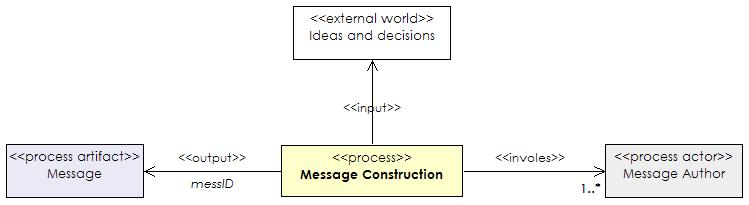
Figure 7. A class diagram describing a message construction process. |
Organise
While querying allows the selection of a subset of media assets, it imposes
no explicit structure on the results of one or more queries. The process of
organisation is to create some document structure for grouping and ordering the
selected media assets for presentation to a user. How this process occurs is,
again, not relevant, but includes the linear relevance orderings provided by
most information retrieval systems. It certainly includes the complex human
process of producing a linear collection of slides for a talk; creating
multimedia documents for the web; ordering shots in a film; or even producing a
static 2-dimensional poster.
The document structure is guided by the message, in the sense that if the
presentation is to convey the intended underlying message then the document
structure should emphasize this, not work against it. The document structure may
reflect the underlying domain semantics, for example a medical or cultural
heritage application, but is not required to. The structure may be colour-based
or rhythm based, if the main purpose of the message is, for example, aesthetic
rather than informative.
In the arena of text documents, the document structure resulting from
organisation is predominantly a hierarchical structure of headings and
subheadings. The document structure of a film is a hierarchical collection of
shots. For more interactive applications, the document structure includes links
from one “scene” to another. In a SMIL [11] document, for example,
par and seq
elements form the hierarchical backbone of the document structure we are
referring to here.
The input to the organise process is the message (messID)
plus one or more media components (compIDs). The
output is the document structure (docID) which
includes pointers to the media components associated with the substructures.
Figure 8 shows a UML class diagram of the organize process described in the
terms of the proposed metamodel.
|
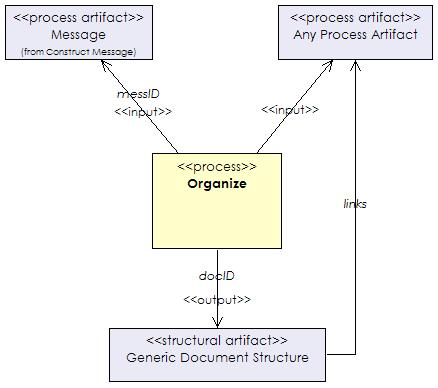
Figure 8. A class diagram describing an organization process. |
Publish
The output of the organise process is a prototypical presentation which can
be communicated to an end-user. This serves as input to the publication process
which selects appropriate parts of the document structure to present to the
end-user. The publication process takes a generic document structure and makes
refinements before sending the actual bits to the user. These may include
selecting preferred modalities for the user and displayable by the user’s
device.
Publication can be seen as taking the document structure from the internal
set of processes and converting it (with potential loss of information) for
external use. Annotations may be added to describe the published document. For
example, the device or bandwidth for which the publication is destined.
Annotations and alternative media assets may be removed to protect internal
information or just reduce the size of the data destined for the user.
Once a document structure is published it is no longer part of the process
set. All that can happen is that the publication itself can be distributed to
the end-user. If republication needs to take place, then this needs to start
from the document structure used as input to the process. The input to the
publication process is a generic document structure (docID),
including the references.
to the media assets and annotations, and the output is a published document (presID).
Figure 9 shows a UML class diagram of the publish process described in the
terms of the proposed metamodel.
|
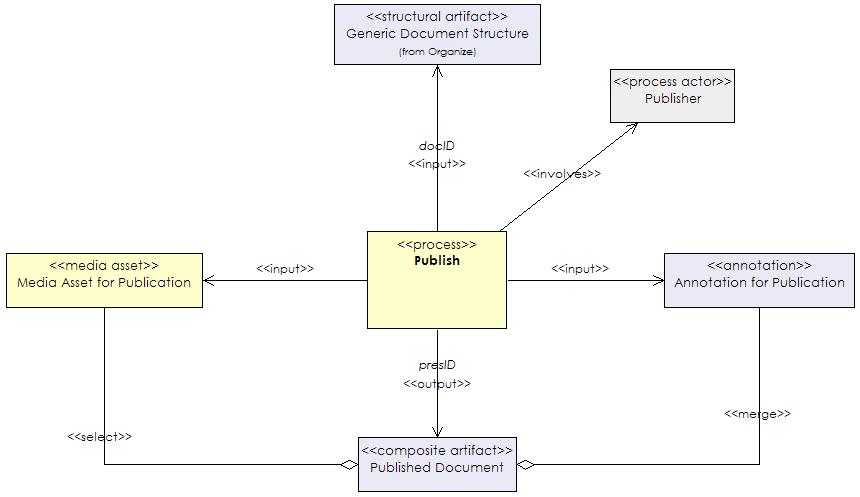
Figure 9. A class diagram describing a publishing process. |
Distribute
The final process is the, synchronous or asynchronous, transmission of the
presentation to the end-user. This can be through the internet, streamed or
file-based; via a non-networked medium such as a CD-ROM or DVD; or projected for
example during a film, performance or talk. The input to the process is a
published document (docID) plus appropriate
software/hardware for displaying/playing the media assets. The output is the
real-time display or projection of the media assets to the end-user. Figure 10
shows a UML class diagram of the distribute process described in the terms of
the proposed metamodel.
|
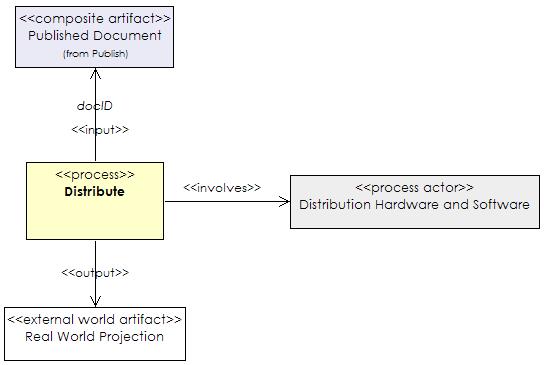
Figure 10. A class diagram describing a distribution process. |
Discussion
Even though based on a small set of applications our investigation on the
applicability of our canonical processes provided relevant insights for our
hypothesis that real parity between tools for the various tools in multimedia
production environments can only be achieved if we get a better understanding of
the connection between processes.
The main outcome of our investigation is that, despite the large amount of
instantiated annotations as well as media document structures during a
production, our canonical processes can provide the means for easing the access
to potentially relevant information. As the defined artifact types are related
to processes that in turn are associated with particular stages within a
production workflow it is these types that facilitate, if known, the entry
points or interfaces to purpose driven exploration or manipulation of the
material.
Another interesting finding is that the identified data types not only work
on this global level of workflows but also help to access more detail areas of
content description, as being exemplified by the schemas (ontIDs),
vocabulary terms (attIDs) and annotations (annIDs).
These provide a particular view on the material, without being able to clearly
determine the full semantic meaning of the media asset. For that the associated
annotation structure needs to be investigated. Their advantage is, however, that
they act like a messenger in cell communication and thus trigger decisions about
the path through the knowledge space that is generated in a production. This
works because there is a relation between production tasks and the complexity
level of the annotation system, which the defined types exploit. Making those
generally available will improve the compatibility across systems from different
providers which supports the tendency of users to make use of tools that are
crafted to give high quality support for the tasks they need to perform without
loosing the capability to access media assets from various sources.
While describing the processes we have tried to keep the descriptions as
simple as possible. In a number of cases, the results of a process can feedback
into a different process in a different role. We do not wish to exclude these
“loops” in anyway, nor do we seek to present a complete list but rather give two
illustrative examples. The document structure (docID)
resulting from the organise process can be treated as a media asset (medID)
and fed back into any of the processes that accept a media asset (medID)
as input. Similarly, a film script is the result of a long premeditation process
in film whose semantics can only be captured with difficulty. The complete
script, however, can be treated as a media asset. Similarly, an annotation can
be treated as a “media asset”, that is an object of an undefined data format
that does not change.
The current stage of our investigation is just a first step towards this
aimed for process fluidity. There are still a number of obstacles that need to
be investigated.
In the processes described in the previous section we do not address the
issue of manipulating a media asset in the form of changing the intrinsic
content of it - as tools like Photoshop allow to do on images. The intention is
rather that the descriptions be independent of data format and editing/authoring
system. If an editing action on a media asset (medID),
does take place then a new media asset is created. The author and/or authoring
system/editing suite may choose to select large numbers of the previously
associated annotations and include these in a new artifact. The problem here is,
that some aspects of the established annotations up to that stage might still be
valid and thus could be kept even for the new media asset. How this detection of
static and changeable media semantics can be detected within annotations and
hence be exploited remains to be investigated.
Outside the scope of the current discussion is the notion of interaction. For
a film or a book there is no (system-processed) interaction. However, for an
interactive media artwork or an informative hypermedia presentation (e.g. blood
flow in the body) interaction is part of the expression of the message and needs
to be incorporated in the presentation distributed to the end user. Further work
is needed to integrate the processes relating to interaction in the model.
Related to the problem of interactivity is the problem of perception. If we
assume here that a piece, be it an interactive art performance or a film, is
consumed and interpreted often over time, then we have to cope with ongoing
circles of applying the canonical processes on the material, including the mix
of it with other media sources. At the moment we have some vague ideas about the
semantic side effects here - not only with respect to the naming of our
processes but also on the flexibility that is demanded by combining content
descriptions. What we would like to mention, though, is our understanding that
the differences between media assets with associated annotations (medIDs+annIDs)
and messages (messIDs) as described during the
postproduction phase of film production will play an essential role here. We
assume that a large amount of additional annotation on an interpretation level
will favour dominant relations of a message types where occasionally references
need to be established to specify particular parts of an audio-visual product.
Moreover, at this stage of interpretation, as well as for reuse processes we see
the need for including additional information structures of relations, a point
that is not at all addressed in this paper.
Conclusion
We see this paper as an initial step towards the definition of data
structures which can be used and accessed by different members of the multimedia
community. In this paper we identify processes that we see as being fundamental
to different applications of multimedia.
Acknowledgments
This paper was inspired by Dagstuhl meeting 05091 “Multimedia Research -
where do we need to go tomorrow” organised by Susanne Boll, Ramesh Jain, Tat-Seng
Chua and Navenka Dimitrova. Members of the ”Multimedia for Human Communication”
working group were: Lynda Hardman, Brigitte Kerherve, Stephen Kimani, Frank Nack,
Kurt Piersol, Nicu Sebe, and Freddy Snijder.
Parts of this research were funded by the Dutch national BSIK MultimediaN
e-Culture, ToKeN2000, CHIME, K-Space and European ITEA Passepartout projects.
References
- B. P. Bailey, J. A. Konstan, and J. V. Carlis. Supporting Multimedia
Designers: Towards More Effective Design Tools. In Proc. Multimedia Modeling:
Modeling Mutlimedia Information and Systems (MMM2001), pages 267–286. Centrum
voor Wiskunde en Informatica (CWI), 2001.
- S. Bocconi, F. Nack, and L. Hardman. Using Rhetorical Annotations for
Generating Video Documentaries. In Proceedings of the IEEE International
Conference on Multimedia and Expo (ICME) 2005, July 2005.
- M. Davis. Active Capture: Integrating Human-Computer Interaction and
Computer Vision/Audition to Automate Media Capture. In ICME ’03, Proceedings,
pages 185–188, July 2003.
- C. Dorai and S. Venkatesh. Bridging the Semantic Gap in Content Management
Systems - Computational Media Aesthetics. In C. Dorai and S. Venkatesh,
editors, Media computing - Computational media aesthetics, pages 1–9. Kluwer
Academic Publishers, June 2002.
- F. Halasz and M. Schwartz. The Dexter Hypertext Reference Model.
Communications of the ACM, 37(2):30–39, February 1994. Edited by K. Grønbæck
and R. Trigg.
- L. Hardman. Modelling and Authoring Hypermedia Documents. PhD thesis,
University of Amsterdam, 1998. ISBN: 90-74795-93-5, also available at
http://www.cwi.nl/~lynda/thesis/.
- R. Jain. Experiential Computing. Communications of the ACM, 46(7):48–55,
July 2003.
- H. Kosch, L. B¨osz¨orm´enyi, M. D¨oller, M. Libsie, P. Schojer, and A.
Kofler. The Life Cycle of Multimedia Metadata. IEEE Multimedia,
(January-March):80–86, 2005.
- F. Nack and A. T. Lindsay. Everything You Wanted to Know About MPEG-7:
Part 1. IEEE MultiMedia, pages 65–77, July - September 1999.
- F. Nack and W. Putz. Designing Annotation Before It’s Needed. In
Proceedings of the 9th ACM International Conference on Multimedia, pages
251–260, Ottawa, Ontario, Canada, September 30 - October 5, 2001.
- W3C. Synchronized Multimedia Integration Language (SMIL 2.0)
Specification. W3C Recommendation, August 7, 2001. Edited by Aaron Cohen.
- W3C. XML Schema Part 2: Datatypes. W3C Recommendation, May 2, 2001. Edited
by Paul V. Biron and Ashok Malhotra.
- W3C. Web Ontology Language (OWL) - Overview. W3C Recommendation, 10
February 2004.
Validation Logos