
The Web has turned into a programming environment, turning its back on its earlier roots of simplicity and ease-of-use. And in the process many properties of the early web have been lost. This talk will examine some of the desirable properties of a future web, such as accessibility, usability, semantics, decentralisation, privacy, aggregation and even what to do about the password problem.
Researcher at CWI in Amsterdam (first non-military internet site in Europe - 1988, whole of Europe connected to USA with 64kb link!)
Co-designed the programming language ABC, that was later used as the basis for Python.
Wrote part of GCC.
At the end of the 80's built a system that you would now call a browser.
Organised 2 workshops at the first Web conference in 1994.
Chaired HTML WG for the best part of a decade.
Co-author of HTML4, CSS, XHTML, XForms, RDFa, etc.
Syntax and abstraction
Functionality
Identity
Decentralisation
HTML was originally designed as a pure structure language: It only described the structure of the document, and not how it should look.
This has some advantages, for instance
The browser-manufacturers at the time, not understanding this principle,
started adding elements to influence presentation (such as
<font> not to mention <blink>...).
This was one of the motivating factors behind creating W3C, and why CSS was the first W3C product.
Style sheets abstract the idea of presentation out into a separate layer, and doing this adds a whole new layer of advantages:
But it still took a long time for the world to get it.
Getting style-sheets accepted took a lot of work and a long time.
It took a while for people to understand that you could separate the presentation from the content.
Separation of concerns makes content more manageable.
Problems with HTML include that it is
If you had a programming language that didn't allow you to create functions and libraries you would be very upset, and yet we seem to accept this from HTML.
What is it that makes a <p> a paragraph?
Certainly not the combination of characters "<", "p", ">".
HTML elements and attributes reflect a small number of semantic properties that we could just as well abstract out:
para: p para@link: a@href image: img image@source: img@src image/content: img@alt
This could allow
<para link="document.pdf">
Here is an image:
<image source="fig.jpg">
Figure 1: The larch
</image>
</para>
This would allow you to easily add new more meaningful elements, for
instance <book> or <person> or
<city>.
But we're not only interested in what markup means as markup, but also as concepts.
Luckily we have RDF to supply meaning as concepts, that can be layered in a
similar way, so that if we make an element <city>, it would
be possible for a browser (or search engine) to know what that means.
<affiliation>
<person>Steven Pemberton</person>
<employer>CWI</employer>
<city>Amsterdam</city>
<country>The Netherlands</country>
</affiliation>
But actually, we don't even need to be tied down to the encoding of markup. Invisible XML frees you even from that. For instance
body {color: blue}
gives you
<css>
<rule>
<simple-selector name="body"/>
<block>
<property name="color" value="blue"/>
</block>
</rule>
</css>
a×(3+b)
gives
<expr>
<prod>
<letter>a</letter>
<sum>
<digit>3</digit>
<letter>b</letter>
</sum>
</prod>
</expr>
HTML5 has turned HTML into a programming environment.
However, the key term for describing the original web (and I would claim, its initial success) is the word "declarative".
A declarative definition is where you describe what you want, rather than how to get it: it describes the solution space, and not a recipe to get to one solution.
Declarative definitions are typically short, and easy to understand.
A classic example is when you learn in school that
The square root of a number n is the number r such that r × r = n
This tells us how to recognise a square root, but not how to calculate one; but no problem, because we have machines to do that for us.
function f a: {
x ← a
x' ← (a + 1) ÷ 2
epsilon ← 1.19209290e-07
while abs(x − x') > epsilon × x: {
x ← x'
x' ← ((a ÷ x') + x') ÷ 2
}
return x'
}
The poster-child of HTML declarative markup is the hyperlink:
<a href="talk.html" title="My talk" target="_blank" class="overt">Web n+1</a>
This compactly encapsulates a lot of behaviour including:
Doing this with programming would be a lot of work.
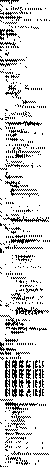
1000 lines, almost all of it administrative. Only 2 or 3 lines have anything to do with telling the time.
And this was the smallest example I could find. The largest was more than 4000 lines.
type clock = (h, m, s) displayed as circled(combined(hhand; mhand; shand; decor)) shand = line(slength) rotated (s × 6) mhand = line(mlength) rotated (m × 6) hhand = line(hlength) rotated (h × 30 + m ÷ 2) decor = ... slength = ... ... clock c c.s = system:seconds mod 60 c.m = (system:seconds div 60) mod 60 c.h = (system:seconds div 3600) mod 24
For instance XForms, a W3C standard in use throughout the world.
A certain company makes BIG machines (walk in): user interface is very demanding — traditionally needed 5 years, 30 people.
With XForms this became: 1 year, 10 people.
Do the sums. Assume one person costs 100k a year. Then this has gone from a 15M cost to a 1M cost. They have saved 14 million! (And 4 years)
The British National Health Service started a project for a health records system.
One person then created a system using XForms.
XForms Day planned in Amsterdam in May.
All those passwords!
It's all about identity.
Your computer knows it is you (you've used a password or whatever to get in).
Use public key cryptography at a low level to log you in.
Two matched keys: you can lock with either key, but if you lock with one, only the other can open it.
So everyone has two keys, one public and one private.
Identity: If I lock a message with my private key, you can open it with my public key and read it, and know it was really from me. (No more spam!)
Privacy: If you send me a message locked with my public key, you know that only I can open it to read it.
Secure messaging: if I send you a message locked with my private key, and your public key, then only you can read it, and you know it's really from me.
You still need to register with sites, but instead of picking a password, you exchange public keys (or your browser does).
Then when you click on "log in", the site says (to your browser): decrypt this for me.
You know it's really them asking, and when your browser decrypts the message, they know it's really you.
And you're in, without typing in a password.
BUT
Use existing technologies.
Peer-to-peer:
Saying not where to get it, but what you want
Fall-back to single source for long-tail content.
magnet:?xt=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C ?as=http%3A%2F%2Fexample.com%2Fulysses.html
If someone already has the document you are downloading in their cache, they can serve it to you.
If several people have it, they can share the task by sharing different parts.
You get it even faster.
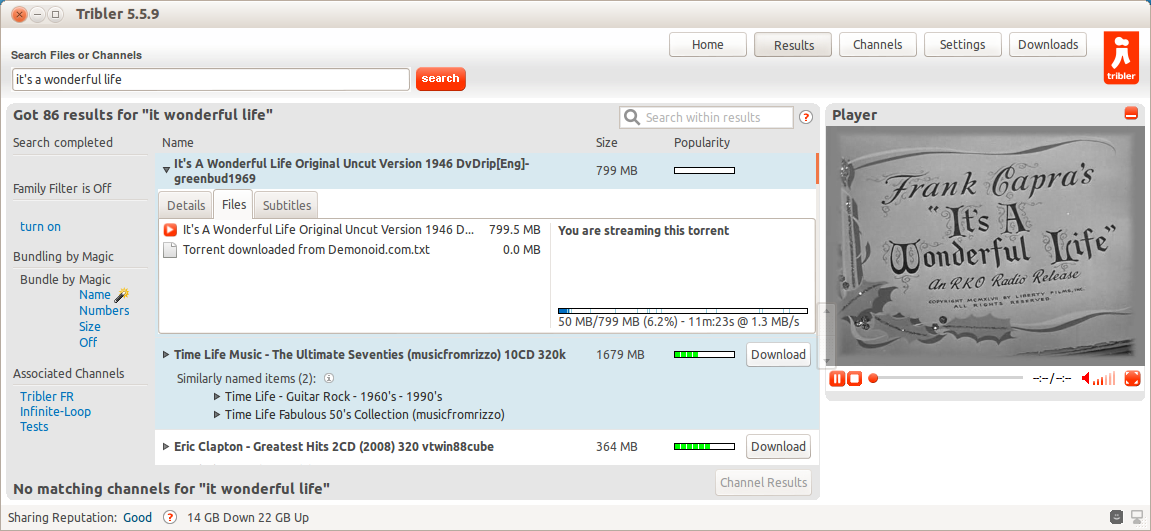
Note (in blue progress bar) how the file is loading in bits, but priority has been given to the start of the file so you can immediately start streaming.
Personalised pages are a possible example of long-tail content.
But even these are applicable, since personalised pages can be represented in very many cases as a merge of the main content and the personalisation data (which for instance XForms is particularly good at).
Although you still need HTTP for long-tail, and single-use content, replacing HTTP with peer-to-peer+magnet links makes the most of the web:
Metcalf proposes that the value of a network is proportional to the square of the number of nodes.
v(n)=n2
Simple maths shows that if you split a network into two, it halves the total value:
(n/2)2 + (n/2)2 = n2/4 + n2/4 = n2/2
This is why it is good that there is only one email network, and bad that there are so many Instant Messenger networks. It is why it is good that there is only one World Wide Web.
The term Web 2.0 was invented by a book publisher (O'Reilly) as a term to build a series of conferences around.
It conceptualises the idea of Web sites that gain value by their users adding data to them, such as Wikipedia, Facebook, Flickr, ...
By putting a lot of work into a website, you commit yourself to it, and lock yourself into their data formats too.
This is similar to data lock-in with software: when you use a proprietary program you commit yourself and lock yourself in. Moving comes at great cost.
As an example, if you commit to a particular photo-sharing website, you upload thousands of photos, tagging extensively, and then a better site comes along. What do you do?
How do you decide which social networking site to join? Do you join several and repeat the work? I am bombarded by emails from networking sites (LinkedIn, Dopplr, Plaxo, Facebook, MySpace, ...) telling me that someone wants to be my friend, or business contact.
How about geneology sites? You choose one and spend months creating your
family tree. The site then spots similar people in your tree on other trees,
and suggests you get together. But suppose a really important tree is on
another site?
How about if the site you have chosen closes down: all your work is lost.
This happened with MP3.com for instance. And Stage6.
How about if your account gets closed down? There was someone whose Google account got hacked, and so the account got closed down. Four years of email lost, no calendar, no Orkut.
Here is someone whose Facebook account got closed. Why? Because he was trying to download all the email addresses of his friends into Outlook.
These are all examples of Metcalf's law.
Web 2.0 partitions the Web into a number of topical sub-Webs, and locks you in, thereby reducing the value of the network as a whole.
What should really happen is that you have a personal Website, with your photos, your family tree, your business details, and aggregators then turn this into added value by finding the links across the whole web.
Firstly and principally, machine readable Web pages.
When an aggregator comes to your Website, it should be able to see that this page represents (a part of) your family tree, and so on.
One of the technologies that can make this happen has the catchy name of RDFa.
You could describe it as a CSS for meaning: it allows you to add a small layer of markup to your page that adds machine-readable semantics.
It allows you to say "This is a date", "This is a place", "This is a person", and uniquely identify them on your web page.
If a page has machine-understandable semantics, you can do lots more with it.
I've picked a few topics to discuss.
The Web is young.
There is still a long way to go!