Invisible XML: the specification

A method for treating non-XML documents as if they were XML.
Almost everything can be treated as XML!
Extra information in the grammar controls details of the serialization:
Email type from XForms 2.0:
<xs:simpleType name="email">
<xs:restriction base="xs:string">
<xs:pattern value="([A-Za-z0-9!#-'\*\+\-/=\?\^_`\{-~]+)
(\.[A-Za-z0-9!#-'\*\+\-/=\?\^_`\{-~]+)*
@([A-Za-z0-9]([A-Za-z0-9-]*[A-Za-z0-9])?)
(\.[A-Za-z0-9]([A-Za-z0-9-]*[A-Za-z0-9])?)+"/>
</xs:restriction>
</xs:simpleType>
email: user, "@", host. {two parts separated by an @ sign}
user: atom+".". {one or more atoms, separated by dots}
atom: char+. {a string of one or more 'char'}
host: domain+".". {a series of domains, separated by dots}
domain: word+"-". {may contain a hyphen, but not start or end with one}
word: letgit+. {otherwise consists of letters and digits}
-letgit: ["A"-"Z"; "a"-"z"; "0"-"9"].
-char: letgit; ["!#$%&'*+-/=?^_`{|}~"].
{A letter, digit, or punctuation.}
Parsing the following email address with this
~my_mail+{nospam}$?@sub-domain.example.info
gives:
<email>
<user>
<atom>~my_mail+{nospam}$?</atom>
</user>@
<host>
<domain>
<word>sub</word>-
<word>domain</word>
</domain>.
<domain>
<word>example</word>
</domain>.
<domain>
<word>info</word>
</domain>
</host>
</email>
The rule for letgit
-letgit: ["A"-"Z"; "a"-"z"; "0"-"9"].
has a dash before it, otherwise instead of
<word>sub</word>you would have had:
<word><letgit>s</letgit><letgit>u</letgit><letgit>b</letgit></word>
<email>
<user>
<atom>~my_mail+{nospam}$?</atom>
</user>@
<host>
<domain>
<word>sub</word>-
<word>domain</word>
</domain>.
<domain>
<word>example</word>
</domain>.
<domain>
<word>info</word>
</domain>
</host>
</email>
Since the word part of a domain has no semantic meaning, exclude it from the serialisation:
word: letgit+. ⇒ -word: letgit+.
<email>
<user>
<atom>~my_mail+{nospam}$?</atom>
</user>@
<host>
<domain>sub-domain</domain>.
<domain>example</domain>.
<domain>info</domain>
</host>
</email>
Change the rule for atom and domain:
atom: char+. ⇒ -atom: char+. domain: word+"-". ⇒ -domain: word+"-".
<email>
<user>~my_mail+{nospam}$?</user>@
<host>sub-domain.example.info</host>
</email>
Change the rules for user and host:
user: atom+".". ⇒ @user: atom+".". host: domain+".". ⇒ @host: domain+".".
<email
user='~my_mail+{nospam}$?'
host='sub-domain.example.info'>@</email>
To get rid of the left-over "@", we can change the rule for
email:
email: atoms, "@", host. ⇒ email: atoms, -"@", host.
<email
user='~my_mail+{nospam}$?'
host='sub-domain.example.info'/>
Format known as 1VWG:
Expressing this in ixml:
ixml: rule+. rule: name, ":", alternatives, ".". alternatives: alternative+";". alternative: term*",".
A term is a factor, an optional factor, or a factor repeated
zero or more, or one or more times:
term: factor;
option;
repeat0;
repeat1.
option: factor, "?".
repeat0: factor, "*", separator?.
repeat1: factor, "+", separator?.
separator: factor.
A factor is a terminal, a nonterminal, or a bracketed series of alternatives:
factor: terminal;
nonterminal;
"(", alternatives, ")".
Terminals are the elements that actually match characters in the input.
Unicode characters are used.
There are two forms for terminals: literal strings, and character sets.
Strings may be delimited by either double quotes or single: ":"
and ':' are equivalent.
If you want to include the delimiting quote in a string, it should be
doubled: "don't" and 'don''t' are equivalent.
For characters with no explicit visible representation or with an ambiguous representation (or not representable with XML).
For instance #a0 represents a non-breaking space.
Encoded characters do not appear within strings, but are free-standing.
This doesn't restrict expressiveness, since a rule like
end: "the", #a0, "end".
represents the seven characters with a non-breaking space in the middle.
Character sets match a character from a set of characters. E.g.
["A"-"Z"; "a"-"z"; "0"-"9"]
Elements of a character set can be
operator: ["+-×÷"]
(which in this case is equivalent to
operator: "+"; "-"; "×"; "÷".
)
["a"-"z"]
[Ll]
Unicode defines 30 character classes, such as lower case letter and upper case letter, encoded with two-letter abbreviations, such as Ll and Lu.
These abbreviations save the work of having to define those classes yourself.
And encourage people to use them, hopefully making formats more international, since you no longer need to know which characters are letters.
These allow you to say "any character but these". For instance you can say:
comment: "{", cchar*, "}".
cchar: ~["}"].
A nonterminal is just a name, referring to the rule of that name.
Is this allowed?
<µ>Mu</µ>
Is this allowed?
<µ>Mu</µ>
Answer: it depends whether that character is #B5 or #3BC.
This is allowed:
<μ>Mu</μ>
This is not:
<µ>Mu</µ>
NameStartChar ::=
":" |
[A-Z] |
"_" |
[a-z] |
[#xC0-#xD6] |
[#xD8-#xF6] |
[#xF8-#x2FF] |
[#x370-#x37D] |
[#x37F-#x1FFF] |
[#x200C-#x200D] |
[#x2070-#x218F] |
[#x2C00-#x2FEF] |
[#x3001-#xD7FF] |
[#xF900-#xFDCF] |
[#xFDF0-#xFFFD] |
[#x10000-#xEFFFF]
NameChar ::=
NameStartChar |
"-" |
"." |
[0-9] |
#xB7 |
[#x0300-#x036F] |
[#x203F-#x2040]
Unicode has 30 character classes:
| Name | Description | Number | Examples |
|---|---|---|---|
| Cc | Control | 65 | Ack, Bell, Backspace, Tab, LF, CR, etc |
| Cf | Format | 151 | Soft hyphen, Arabic Number Sign, Zero-width space, left-to-right mark, invisible times, etc. |
| Co | Private Use | #E000-#F8FF | |
| Cs | Surrogate | #D800-#DFFF | |
| Ll | Lowercase Letter | 2,063 | a, µ, ß, à, æ, ð, ñ, π, Latin, Greek, Coptic, Cyrillic, Armenian, Georgian, Cherokee, Glagolitic, many more |
| Lm | Modifier Letter | 250 | letter or symbol typically written next to another letter that it modifies in some way. |
| Lo | Other Letter | 121,047 | ª, º, ƻ, dental click, glottal stop, etc., and letters from languages that don't have cased letters, such as Hebrew, Arabic, Syriac, ... |
| Lt | Titlecase Letter | 31 | Mostly ligatures that have to be treated specially when starting a word. |
| Lu | Uppercase Letter | 1,702 | A, Á, etc |
| Mc | Spacing Mark | 401 | Spacing combining marks, Devengari, Bengali, etc. |
| Me | Enclosing Mark | 13 | Combining enclosing characters such as "Enclosing circle" |
| Mn | Nonspacing Mark | 1763 | Combining marks, such as combining grave accent. |
| Nd | Decimal Number | 590 | 0-9, in many languages, mathematical variants, |
| Nl | Letter Number | 236 | Ⅰ, Ⅱ, Ⅲ, Ⅳ,... |
| No | Other Number | 676 | subscripts, superscripts, fractions, circled and bracketed numbers, many languages |
| Pc | Connector Punctuation | 10 | _, ‿, ⁀, ... |
| Pd | Dash Punctuation | 24 | -, –, —, ... |
| Pe | Close Punctuation | 73 | ), ], }, ... |
| Pf | Final Punctuation | 10 | », ’, ”, ... |
| Pi | Initial Punctuation | 12 | «, ‘, “, ... |
| Po | Other Punctuation | 566 | !@#"%&'*,./:;?¶ ... |
| Ps | Open Punctuation | 75 | (, [, {, ... |
| Sc | Currency Symbol | 54 | $, £, €, ¢, ¥, ¤, ... |
| Sk | Modifier Symbol | 121 | ^, ´, `, ¨, ˚, ... |
| Sm | Math Symbol | 948 | +, <, =, >, |, ~, ±, ×, ÷, ... |
| So | Other Symbol | 5855 | ©, ®, °, various arrows, much more. |
| Zl | Line Separator | 1 | (Not cr, lf) |
| Zp | Paragraph Separator | 1 | |
| Zs | Space Separator | 17 | space, nbsp, en quad, em quad, thin space, etc. (Not tab, cr, lf etc.) |
Names in ixml are defined using Unicode character classes, while keeping as close as possible to the spirit of what is allowed in XML:
name: namestart, namefollower*. namestart: ["_"; Ll; Lu; Lm; Lt; Lo]. namefollower: namestart; ["-.·‿⁀"; Nd; Mn].
Consequently there are small differences in what a name is.
For instance, Unicode classes the characters ª and º as letters, and does class both mu characters as letters, while XML doesn't
It is the responsibility of the ixml author to ensure that names that are serialised adhere to the XML rules.
Allowed after any token, and before the very first token. All rules indicate this. For instance:
ixml: S, rule+.
rule: name, S, ":", S, alternatives, ".", S.
alternatives: alternative+(";", S).
S defines what a space is:
S: (whitespace; comment)*.
whitespace: [Zs; #9 {tab}; #a {lf}; #d {cr}].
comment: "{", (cchar; comment)*, "}".
cchar: ~["{}"].
The Zs character class is all characters classified in Unicode as a space character.
(Tab, line feed, and carriage return are classified as control characters in Unicode).
Wherever whitespace is permitted in ixml, so is a comment.
Comments may be nested so that you can comment out sections of a grammar.
It is not specified which parse algorithm should be used.
It must however:
By default, a parse tree is serialised as XML elements:
The parse tree is traversed in document order (depth first, left to right)
For instance, for this small grammar for simple expressions:
expr: operand+operator. operand: id; number. id: letter+. number: digit+. letter: ["a"-"z"]. digit: ["0"-"9"]. operator: ["+-×÷"].
parsing the following string:
pi×10
would produce
<expr>
<operand>
<id>
<letter>p</letter>
<letter>i</letter>
</id>
</operand>
<operator>×</operator>
<operand>
<number>
<digit>1</digit>
<digit>0</digit>
</number>
</operand>
</expr>
To control serialisation, marks are added to grammars.
There are three options for serialising a nonterminal:
For serialising a terminal the only option is between serialising it ("^", the default) and not ("-").
The only unusual case for serialisation is for attribute children of a partially serialised node:
-number: @value.
There is no element for the value attribute, so it is moved up to the nearest parent element.
expr: operand+operator. operand: id; number. -id: @name. name: letter+. -number: @value. value: digit+. -letter: ["a"-"z"]. -digit: ["0"-"9"]. operator: ["+-×÷"].
on
pi×10
gives
<expr> <operand name='pi'/> <operator>×</operator> <operand value='10'/> </expr>
A grammar may be ambiguous, so that a given input may have more than one possible parse.
In that case:
The ixml grammar is itself an application of ixml.
That means that the grammar can be parsed with itself, and then serialised to XML.
This has consequences for the design of the grammar: where to use attributes.
The decision taken was to put all semantic terminals (such as names) in attributes, and otherwise to use elements.
So as an example, the serialisation for the rule for rule,
rule: (mark, S)?, name, S, ["=:"], S, -alts, ".", S.
is:
<rule name='rule'>:
<alt>
<option>(
<alts>
<alt>
<nonterminal name='mark'/>,
<nonterminal name='S'/>
</alt>
</alts>)?</option>,
<nonterminal name='name'/>,
<nonterminal name='S'/>,
<inclusion>[
<literal dstring='=:'/>]</inclusion>,
<nonterminal name='S'/>,
<nonterminal mark='-' name='alts'/>,
<literal dstring='.'/>,
<nonterminal name='S'/>
</alt>.</rule>
Although all terminal symbols are preserved in the serialisation, the only ones of import are in attribute values.
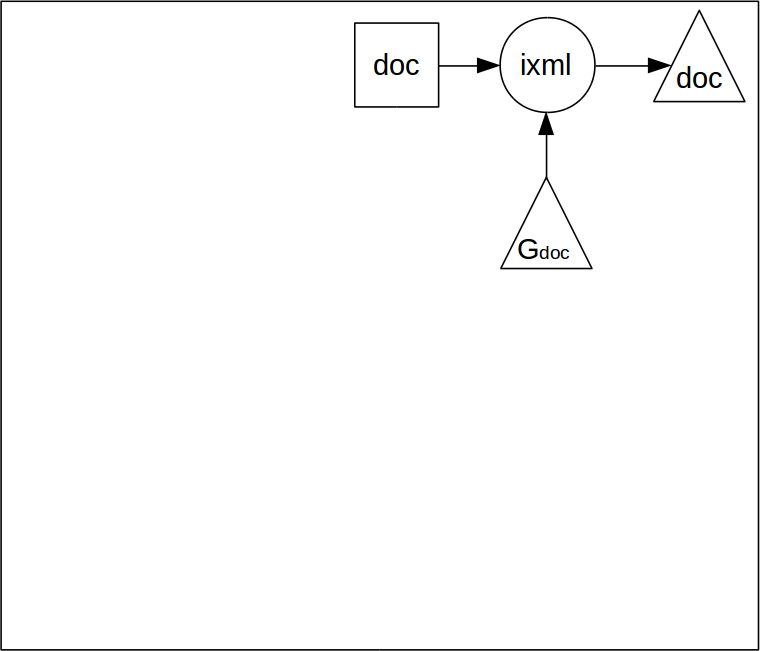
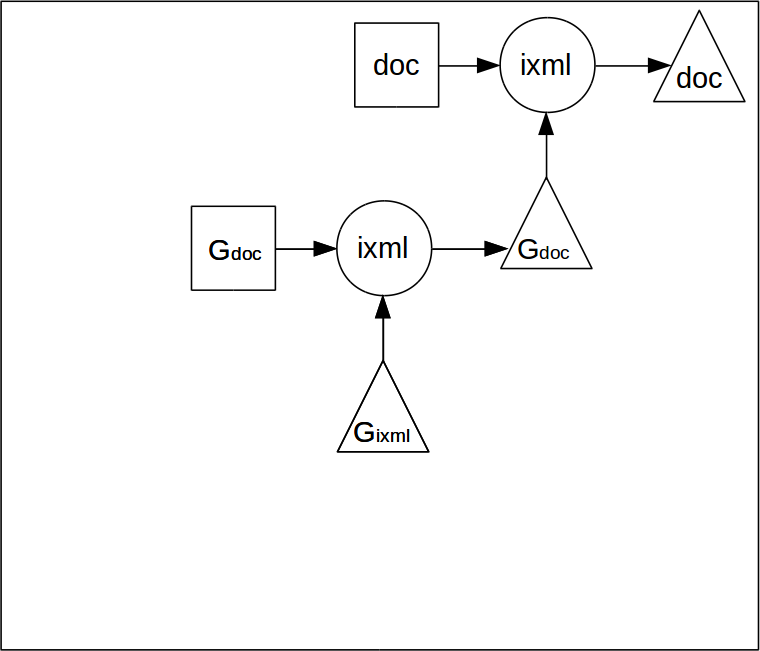
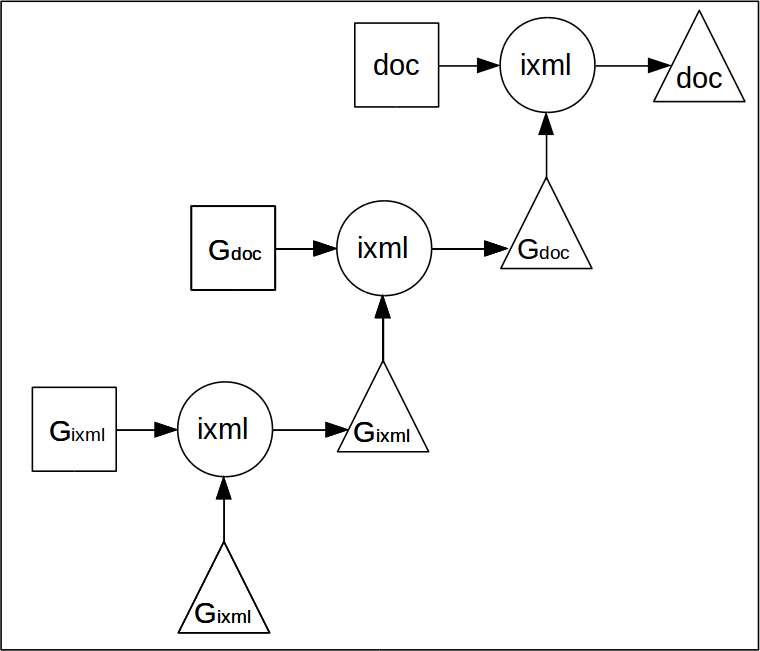
It is the XML serialisation of the grammar that is used as input to the parser.
This means that a different ixml grammar may be used, as long as the serialisation is the same.
So if the grammar looks like this:
<expr> ::= <id> | <number> | <expr> <op> <expr>
that is fine, as long as it produces the same serialisation structure.
A pilot implementation of an ixml processor has been created (and used for the examples here).
The next step is to turn this into a full-strength implementation.
If you look at an ixml grammar in the right way, you can also see it as a type of schema for an XML format.
Future work will look at the possibilities of using ixml to define XML formats, and methods for round-tripping.
The bind element in XForms 1.1 in XSL:
<element name="bind">
<complexType>
<sequence minOccurs="0" maxOccurs="unbounded">
<element ref="xforms:bind"/>
</sequence>
<attributeGroup ref="xforms:Common.Attributes"/>
<attribute name="nodeset" type="xforms:XPathExpression" use="optional"/>
<attribute name="calculate" type="xforms:XPathExpression" use="optional"/>
<attribute name="type" type="QName" use="optional"/>
<attribute name="required" type="xforms:XPathExpression" use="optional"/>
<attribute name="constraint" type="xforms:XPathExpression" use="optional"/>
<attribute name="relevant" type="xforms:XPathExpression" use="optional"/>
<attribute name="readonly" type="xforms:XPathExpression" use="optional"/>
<attribute name="p3ptype" type="xsd:string" use="optional"/>
</complexType>
</element>
You could express this in ixml as follows:
bind: -Common, @nodeset?, -MIP*, bind*.
MIP: @calculate; @type; @required; @constraint;
@relevant; @readonly; @p3ptype.
nodeset: xpath.
calculate: xpath.
type: QName.
constraint: xpath.
relevant: xpath.
readonly: xpath.
p3ptype: string.
The main hurdle is that a rule name must be unique in a grammar, and in XML attributes and elements with the same name may have different content models.
For instance, there is also a bind attribute on other elements
in XForms.
The input element in XForms:
<element name="input">
<complexType>
<sequence>
<element ref="xforms:label"/>
<group ref="xforms:UI.Common" minOccurs="0" maxOccurs="unbounded"/>
</sequence>
<attributeGroup ref="xforms:Common.Attributes"/>
<attributeGroup ref="xforms:Single.Node.Binding.Attributes"/>
<attribute name="inputmode" type="xsd:string" use="optional"/>
<attributeGroup ref="xforms:UI.Common.Attrs"/>
<attribute name="incremental" type="xsd:boolean" use="optional" default="false"/>
</complexType>
</element>
<attributeGroup name="Single.Node.Binding.Attributes">
<attribute name="model" type="xsd:IDREF" use="optional"/>
<attribute name="ref" type="xforms:XPathExpression" use="optional"/>
<attribute name="bind" type="xsd:IDREF" use="optional"/>
</attributeGroup>
which becomes:
input: -Common, -UICommonAtts, -Binding?,
@inputmode?, @incremental?, label, UICommon*.
Binding: (@model?, @ref; @ref, @model); @bind.
model: IDREF.
bind: IDREF.
ref: xpath.
You could even design 'compact' versions of XML formats, eg for XForms:
bind //@open type boolean input age "How old are you?"
by altering the rules above to
bind: -"bind" -Common, @ref?, -MIP*, bind*.
MIP: @nodeset; @calculate; @type; @required; @constraint; @relevant; @readonly; @p3ptype.
nodeset: xpath.
calculate: -"calculate", xpath.
type: -"type", QName.
etc., and
input: -"input", -Common, -UICommonAtts, -Binding?, @inputmode?, @incremental?, label, UICommon*.
etc.
A host of new non-XML documents are opened to the XML process pipeline by ixml.
In some senses it also mitigates the loss of SGML minimisation in XML.ng
By defining ixml in ixml, it becomes the first large application of ixml.
Future work will be to allow designers to create formats in a compact version and an equivalent XML version in parallel.
Please comment on the specification, which you can find on my homepage.