Greetings from Amsterdam

This conference is being broadcast from the Science Park Amsterdam, the birthplace of the open internet in Europe.
Notations can affect the way we think, and how we operate; consider as a simple example the difference between Roman Numerals and Arabic Numerals, where Arabic Numerals allow us not only to more easily represent numbers, but also ease manipulations of numbers and calculations.
One of the innovations of the World Wide Web was the URL. In the last 30 years, URLs have become an ever-present element of everyday life, so present that we scarcely even grant them a second thought. And yet they are a designed artefact: there is nothing natural about their structure -- each part is there as part of a design.
This talk looks at the design issues behind the URL, what a URL is meant to represent, and how it relates to the resources it identifies, and its relationship with representational state transfer (REST) and the protocols that REST is predicated on. The talk considers, with hindsight, how the design, if at all, could have been improved.
While it is too late now to change the design of URLs, are there any the lessons that we can draw from their design, and if so, can they be used to direct the future designs of notations?
This conference is being broadcast from the Science Park Amsterdam, the birthplace of the open internet in Europe.
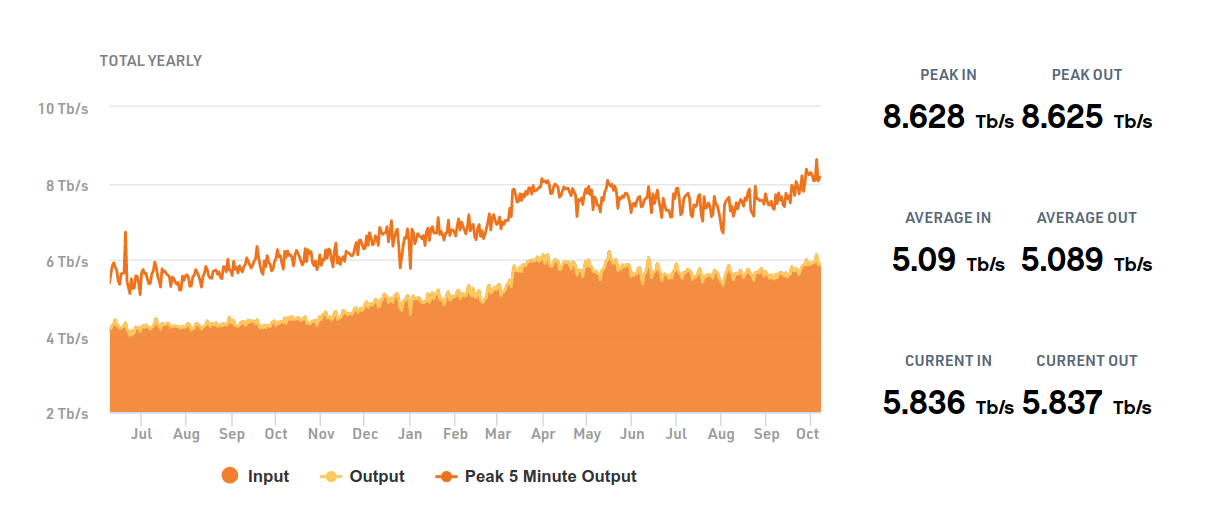
In November 1988 the first European open internet connection was established here, with the mind-boggling speed of 64kbps. Since then it has nearly doubled every year, and is currently peaking at nearly 8.4 Tbps. (Note how visible the lockdown is).
That is 27 doublings in 32 years.
The introduction of the internet in Europe was an impetus for the creation of the World Wide Web.
Tim Berners Lee wrote his proposal in March 1989, and the first web server was running in 1990, and announced in 1991.
It couldn't have been created in a more international environment: by a Brit and a Dutch-speaking Belgian with a French surname on designated international territory straddling the Swiss and French borders.
The World Wide Web cleverly combined several existing technologies such as hypertext, SGML, and the internet to create a successful global information system.
One of its innovations was the URL, allowing resources over the whole world to be identified for retrieval.
If you are interested you can read an early design document: Universal Document Identifiers on the Network (OSI-DS 29) (1992)
The first formal definition was: RFC 1738 (1994)
The most recent is RFC: RFC 3986 (2005)
Internationalised in: RFC 3987 (2005)
Updated for IPv6 in: RFC 6874 (2013)
See also: URI Design and Ownership (2014)
There are four terms used: URL, URN, URI, and IRI.
http://www.cwi.nl/~steven/Talks/2020/10-09-urls/
urn:isbn:0451450523
The umbrella name for URL and URN.
https://www.石川.日本/雅康#mimasa
A URL consists of several distinct parts, each with its own special character to demarcate either its start or end:
scheme: //authority /path ?query #fragment
where an authority for HTTP is
user:password@ host :port
A client uses a URL to retrieve a resource from a server.
The client uses all parts except the fragment to retrieve the resource.
The server only sees and uses the path and the query parts.
The client uses the fragment once the resource has been retrieved.
The syntax of a URI is very general, and different parts may have different syntaxes. The URI specs only define the characters that may be used, but not the syntax of those parts.
Owners of other parts are:
It is a little vague who owns the syntax of a query.
Every single part of a URL is optional, though there are some combinations you never see in real life, such as leaving the scheme out but not the host:
//www.example.com/
Or retaining the scheme but not the host:
http:/file.txt
In fact even the empty string is a valid URL (meaning "the current resource"), and does even have a few uses.
scheme: //user:password@ host :port /path ?query #fragment
The scheme principally represents a couple of things:
Not all schemes have a formally defined protocol (or port for that matter),
for instance mailto: and file: which depend on native
properties of the client platform.
Some naughty applications specify schemes in order to identify document types for that application. This is wrong.
Schemes are used for defining how to retrieve resources.
The returned mediatype of the retrieved resource should be used for initiating an application.
The most important scheme is clearly http.
An obvious observation is that there is no reason for the name of the scheme to match the name of the protocol it identifies.
It is one of the
great missed chances not to have used web: as the name of the
main scheme, rather than the technical-looking http:
We will say something about the https: scheme at the end of the talk.
scheme: //user:password@ host :port /path ?query #fragment
The double slash announces the start of the authority, the name for everything up to the path, in other words user:password, hostname, and port.
If there is no authority part, you don't need to use the double slash; that notwithstanding, you still see a lot of file: URLs of the form
file:///home/user/documents/file.txt
when in fact
file:/home/user/documents/file.txt
means the same thing.
Any suitable character would have done to announce the start of the authority.
Berners-Lee reports that he took the double slash from the Apollo file system, where they needed a syntax to differentiate a local file
/folder/file
from a file over the network:
//machine/folder/file
As he said:
"When I was designing the Web, I tried to use forms which people would recognize from elsewhere."
In fact Berners-Lee has been reported as saying the double slash was the only thing he would change in his design because "it is unnecessary".
I tend to disagree, because it is useful to be able to distinguish between the machine (the authority) and the path. You need to be able to distinguish between
http:machine/file
and
http:directory/file
unless you dictate that a scheme always requires an authority.
scheme: //user:password@ host :port /path ?query #fragment
It may seem bizarre in the context of the modern web that there is a place in a URL for a username and password: they are both exposed in any document containing the URL, and exposed again as they are passed over the connection (there is no secure method of transmitting them in the protocol).
The reason they are there is almost certainly because ftp required them to retrieve documents, and so they had to be present in the URL. The username was almost always anonymous.
We will say more about passwords later.
scheme: //user:password@ host :port /path ?query #fragment
The host part was already a given fact, having been defined for the DNS system in the mid 1980s.
It can be either a hostname using DNS, or an IP address.
Interestingly, a hostname can also be a number, so you may not be able to tell them apart until the very last segment:
192.168.178.com
The host part of a URL originally indentified a unique machine.
It was only realised later that several hostnames could point to the same machine, and a single machine could easily host several servers.
It required an update to the HTTP protocol to support this properly though.
Because originally the host identified a single machine, many sites kept one machine specifically reserved as a Web server.
The first two URLs published in 1991 (as far as I can tell) were
http://cernvm.cern.ch/FIND
and
http://info.cern.ch/hypertext/WWW/TheProject.html
Notably neither server was called "www".
And yet within a short period, nearly all webserver hosts were called exactly that, so that many people thought that "www" somehow was an essential part of a URL.
Again, it is frankly weird that people didn't settle on 'web' instead of 'www', since www, with 9 syllables, is an acronym that is 3 times longer (in English) than the 3 syllable phrase it stands for.
scheme: //user:password@ host :port /path ?query #fragment
Each protocol has a default port. For instance, http uses 80. However it doesn't have to be at 80, and this is the place you can change it.
However, it is rather odd that it is here, since it is associated with the protocol, not the authority.
It should really have been something like
http-8080://example.com/doc.html
or similar.
If I write an address in the UK, it looks something like
Steven Pemberton
21, Sandridge Road,
St. Albans,
Herts,
UK
What you see is that it is almost entirely little-endian: from left to right and top to bottom the information gets more and more significant (except the 21, which is big-endian).
On the other hand, an address in Soviet Russia looked like this:
РОССИЯ
г.Москва 125252
ул.Куусинена 21-Б
Междунродный Центр Научной и Технической Информации
Чичикову П.И.
which is entirely big-endian, even down to the person's name with family name first.
We're confronted with clashes in endianism all the time:
Times: 12:15:45 - big endian
Dates: 31/12/1999 - little-endian
Dates (in USA) - 12/31/1999 - confused endian
We inherited our number system from Arabic.
The interesting thing is if you look at a piece of Arabic writing, such as this from the Wikipedia page on the Second World War:
الحرب العالمية الثانية: هي نزاع دولي مدمر بدأ في الأول من سبتمبر 1939 في أوروبا وانتهى في الثاني من سبتمبر 1945، شاركت فيه الغالبية العظمى من دول العالم، في حلفين رئيسيين هما: قوات الحلفاء ودول المحور. وقد وضعت الدول الرئيسية كافة قدراتها العسكرية والاقتصادية والصناعية والعلمية في خدمة المجهود الحربي، وتعد الحرب العالمية الثانية من الحروب الشمولية، وأكثرها كلفة في تاريخ البشرية لاتساع بقعة الحرب وتعدد مسارح المعارك والجبهات فيها، حيث شارك فيها أكثر من 100 مليون جندي، وتسببت بمقتل ما بين 50 إلى 85 مليون شخص ما بين مدنيين وعسكريين، أي ما يعادل 2.5% من سكان العالم في تلك الفترة.
what is notable is that even though the text is read right-to-left, the numbers are still what an English-language reader would consider "the right way round".
In other words, in the original Arabic form, numerals were little-endian (which has some slight arithmetical advantages by the way), but were imported into Western languages back-to-front, and so became big-endian.
It is interesting to note that historically, before the introduction of Arabic numerals, we spoke numbers (at least under one hundred) little endian:
Arabic numerals started being introduced during the enlightenment, which may have affected how we spoke numbers, since in English at least we now speak numbers big-endian, with the exception of the numbers between 13 and 19 inclusive.
Shakespeare used both styles of numbering.
I did a bit of research and discovered that he used little-endian numbers (four and twenty) about twice as often as big endian (twenty four), which may show that the style of speaking numbers was changing at that time (though you need to take into account the requirements of the metre).
At the point where the authority ends, and the path begins, a URL shifts from little-endian, to big-endian.
www.example.com - little-endian
/Talks/2020/09/slides.html - big endian.
Berners-Lee has in the past suggested that he would have preferred
http:com/example/www/Talks/2020/10/slides.html
but this does have a problem that it is hard to locate where the authority ends, and where the path begins, and could even be ambiguous.
scheme: //user:password@ host :port /path ?query #fragment
The path suggests a file path, and indeed on the first implementations, and many current ones, is indeed so; but it isn't a requirement.
In fact, officially, the path is opaque: you cannot necessarily conclude anything from it.
For instance, there is no a priori reason why
/2020/Talks/
and
/Talks/2020/
shouldn't refer to the same thing.
At the end of a vast number of URLs is a file type
http://www.example.com/index.html
and
http://example.org/logo.gif
and this reflects that many implementations map a URL directly onto the filestore.
This is a great pity, because it means we lose out on a great under-used property of http.
HTTP has a number of headers that allow you to characterise properties of the resource that you are interested in. This is called content negotiation, though there is no actual negotation going on:
The latter two are more for machines, but the first two are definitely useful for people.
If a page specified an image as
<img src="logo"/>
(rather than logo.gif) then the client program could include an
accept header that specified which image types it preferred, and
the site could include more alternatives.
If a site had a document available in several different types, a client program could list them in preference order, or a machine could check if a particular type was available by saying it only accepted that one type.
http://example.org/documents/declaration
Many sites offer their content in a variety of languages, and allow you to click to select a different one.
And yet, the HTTP protocol says which languages you prefer. They don't need to ask.
google.com in particular is really bad at this. If you take your laptop to another country, their interface suddenly switches to the/a language of that country, even if your browser is telling them which language you want.
In the international train between Amsterdam and London I get the Swedish interface!
One of the shortcomings of HTTP is that you can't specify these features in the URL.
For instance it would be useful if you could say you wanted the Dutch version of a PDF document with
http://example.com/doc[type=pdf;lang=nl]
Or that you preferred it, but were willing to accept something else:
http://example.com/doc[type=pdf,*;lang=nl,en]
Another shortcoming of many servers is that while they do use the
Accept: headers to decide what to give you, they don't return the
correct response code when they fail to supply what you asked for. Typically
you get a 200, as if all were well.
This is nearly as bad as returning a 200 when a 404 should have been returned, and it means that even if you wanted to, you couldn't write a program to discover what a site offered.
scheme: //user:password@ host :port /path ?query #fragment
The query allows you to send a small amount of data with the URL, rather than in the body of the HTTP request.
The major design blunder of the URL for HTML was using an ampersand to separate the values, since it is a special character in HTML, meaning that you can't just paste a URL into HTML, but have to replace every occurrence of & with &
There was later a rear-guard action to try and replace it with semicolon, but too late.
Another weirdness of the HTML query is that spaces should officially be replaced with a "+", and therefore "+" should be replaced with %2B.
scheme: //user:password@ host :port /path ?query #fragment
As mentioned earlier, the fragment is for use after the resource is retrieved. Its syntax and how it is used is up to the specification for the media type of the resource returned.
Even though they are sometimes called 'fragment identifiers', and for HTML must be identifiers, there is no syntactic requirement in general that they be identifiers.
Berners-Lee reports that he chose the # sign, because of its similar use in postal addresses in the USA, indicating a sub-location in an address.
As we have seen, a URL uses a number of special characters for its syntax. They are, in order,
The general rule is that to the left of the last use of the character in the URL syntax, the character must be encoded, and to the right, it doesn't have to be. For instance:
One mistake: this doesn't count for #. They still have to be encoded in a fragment.
The web (and URLs) were defined pre-Unicode, and used Latin-1.
This was already better than the rest of the internet, which used pure ASCII (for instance DNS is ASCII).
Unfortunately, when encoding a character, there is no terminator. It is just two hex digits: a space is %20
This meant that when Unicode came along there was no way to encode its characters; you would want to just use the codepoint of a character; unfortunately you have to know how to encode it into UTF-8, and encode those bytes.
So for
search?q=♥
while ideally you might want to write
search?q=%2665;
you have to write
search?q=%E2%99%A5
This is a shame.
A URL may not contain an (unencoded) space.
The use of white space characters has been avoided in UDIs: spaces are not legal characters. This was done because of the frequent introduction of extraneous white space when lines are wrapped by systems such as mail, or sheer necessity of narrow column width, and because of the inter-conversion of various forms of white space which occurs during character code conversion and the transfer of text between applications.
However, there is the weirdness that spaces everywhere but in a query should be encoded with %20, but in a query with +, therefore meaning that + has to be encoded only in a query.
https is a mistake, one of a number of mistakes introduced by Netscape, such as <blink>, <img>, and <frame>.
The URLs
http://www.example.com/doc.html
and
https://www.example.com/doc.html
locate the same document in every way. The only difference is in details of the protocol being used to retrieve the document.
In other words, whether the connection is encrypted or not should be part of the protocol; we as users shouldn't have to care about, nor be confronted by, the negotation between the machines about how they are going to transport the data.
Now we are being forced to change all our documents to use https links. That shouldn't have been necessary.
The password situation on the web is a disaster.
Basic authentication in the URL must be ignored of course.
The way it is done now is that every site has its own password system (and rules for passwords), and requires every site builder to understand the finer points of passwords (which they don't), and protect the passwords sufficiently (which they don't).
The combination is a royal security mess.
Everyone has two matched keys:
('Keys' are very large numbers, 300 digits or more; 'locking' means scrambling the message using those large numbers)
I lock a message with my private key (so it can only be opened with my public key).
I send the locked message to you.
You get a copy of my public key: if it opens the message, you know it was really from me.
No more phishing!
I lock a message with your public key (so it can only be opened with your private key).
I send you the locked message: I know that only you can open it to read it.
Combine those two things:
I lock a message:
I send it to you:
We can use the same process instead of passwords when logging in to websites. This could just be added to the protocol.
You want to create an account at an online shop. You click on the "Create an account" button.
The site asks you to for a username, which you provide, and click OK.
The site checks the user name is free, and returns a message to your browser that you want to register.
The browser asks if you want to register.
If you click yes, the browser and the site exchange public keys.
You fill in your username, and click on Log in.
The site generates a one-time password, locks it with your public key, and its own private key, and returns it to the browser.
Your browser knows it is really from the site (and not someone pretending).
The browser asks if you really want to log in with that username.
If you say yes, it decodes the password and sends it back, this time locked with your private key and the site's public key.
The site therefore knows it is really you and lets you in, without you having to type in a password!
The password situation is a disaster; it can still be fixed in the protocol!
URLs are useful, and have been durable.
They exhibit some design faults, which is easy to say in hindsight.
Those faults are lessons we can take on board for future designs of notations.