Amsterdam

XForms is a declarative XML-based programming language for writing applications for the web and elsewhere. One of the central aspects of XForms is invariants that describe relationships between values, such that if a value changes or is changed, its related values specified in the invariants get updated automatically. This is much like how spreadsheets work, though more general. A major advantage of this approach is that much administrative detail is taken out of the hands of the programmer, and done automatically: the programmer specifies the relationships, and the computer does the work.
However, XForms in its current incarnation only allows invariants to be placed between simple content values, even though there are important relationships that could be specified over data structures as a whole. This paper explores the possibilities for extending the mechanism to more general cases.
XForms: a declarative XML-based programming language for applications on the web and elsewhere.
A W3C standard
In worldwide use, for instance by the Dutch Weather Service, KNMI, national government websites, the BBC, the US Department of Motor Vehicles, the British National Health Service, and many others.
Experience shows you can produce applications in typically a tenth of the time compared with traditional procedural methods.
Aim: initiate discussion on generalising the XForms invariant mechanism to higher-level invariants, as input for a future version of XForms.
Essential mechanism within XForms.
Relationships are specified between values: if a value changes, for whatever reason, its dependent values are changed to match.
This may then generate a chain of changes along dependent values.
Similar to spreadsheets, but: much more general.
About 90 lines of XForms.
Not a single while statement.
Dijkstra in his seminal book A Discipline of Programming first pointed out that the principle purpose of a while statement in programming is to maintain invariants.
It is then less surprising that if you have a mechanism that automatically maintains invariants, you have no need for while statements.
High-level abstraction: there is a two-dimensional position of a location in the world, and a value for the magnification or zoom value required; a map is maintained centred at that location.
It uses a service that delivers (square) map tiles for a region covering a set of locations at a particular zoom level:
http://<site>/<zoom>/<x>/<y>.png
The coordinate system for the tiles is as a two-dimensional array.
At the outermost level, zoom 0, there is a single tile
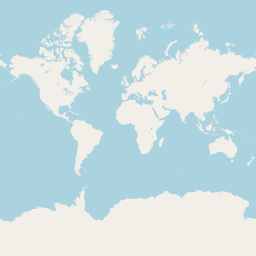
At the next level of zoom, 2×2 tiles,
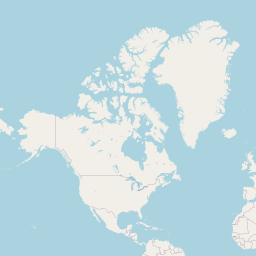
At the next level 4×4, then 8×8, and so on, up to zoom level 19.


For the tile for a location in world coordinates, calculate from the zoom how many locations are represented by each tile, and divide:
scale=226 - zoom
tilex=floor(worldx ÷ scale)
tiley=floor(worldy ÷ scale)
In XForms:
<bind ref="scale" calculate="power(2, 26 - ../zoom)"/> <bind ref="tileX" calculate="floor(../worldX div ../scale)"/> <bind ref="tileY" calculate="floor(../worldY div ../scale)"/>
These are not assignments, but invariants – statements of required
equality: if zoom changes then scale will be updated.
If scale or worldX changes, then tileX
will be updated, and so on.
It is equally easy to calculate the URL of the tile:
<bind ref="tile"
calculate="concat(../site, ../zoom, '/',
../tileX, '/', ../tileY,
'.png')"/>
and displaying it is as simple as
<output ref="tile" mediatype="image/*"/>
For a larger map, it is easy to calculate the indexes of adjacent tiles.
So displaying the map is clearly easy, and uses simple invariants.
Making the map pannable uses the ability of keeping the mouse coordinates and state of the mouse buttons as values.
When the mouse button is down, the location of the centre of the map is the sum of the current location and the mouse coordinates.
As this value changes, so the map display is (automatically) updated to match.
The advantages of the invariant approach:
It uses a straightforward ordered-graph based dependency algorithm, ordered since circular dependencies are disallowed.
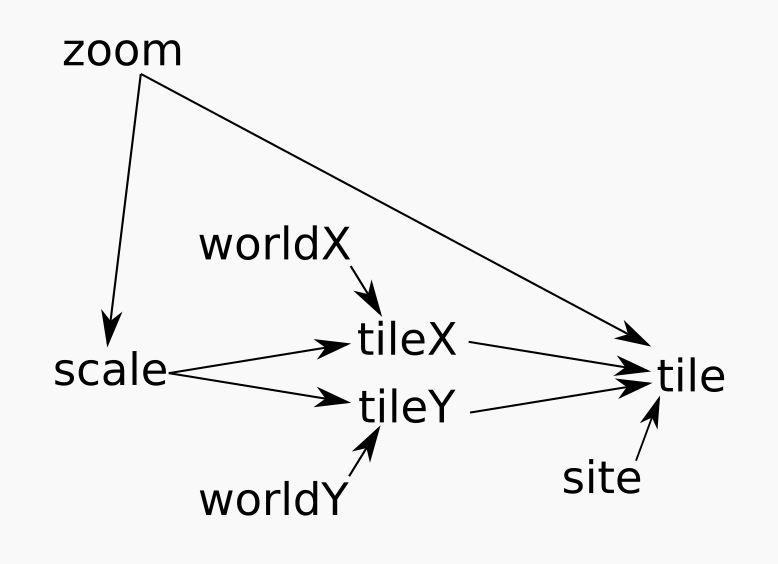
Updates are triggered by changes to values, and updates are then ordered along the dependency chain and applied.
Initially the system is at stasis: values are initialised, invariants up-to-date.
When a change occurs, whether caused by the user, or by the system, an update occurs, to return the system to stasis.
This has 4 stages:
The update mechanism is automatic, but there are opportunities to hook into it for special cases, such as setting up initial dynamic values.
<action ev:event="xforms-ready">
<setvalue ref="today" value="local-dateTime()"/>
</action>
This uses the event mechanism to catch and respond to processing events.
The invariant mechanism has one main limitation: it can only make changes to simple content, values that can be calculated with a simple expression.
To make structural changes, you use the event mechanism.
The events of interest are:
Handlers listen for events that report these changes and respond suitably.
An array has to be of a certain size, defined by an attribute on the root element.
<instance>
<data size="10" xmlns="">
<value/>
</data>
</instance>
The initialisation event is caught to ensure that there are the right number of elements:
<action ev:event="xforms-ready">
<insert ref="value" while="count(value) < @size"/>
</action>
(The <insert/> action by default duplicates the last
element in the nodeset referenced).
If size changes during processing, and the number of elements
has to be adjusted, value changed events are caught for that value:
<action ev:event="xforms-value-changed"> <insert ref="value" while="count(value) < @size"/> <delete ref="value[last()]" while="count(value) > @size"/> </action>
This inserts elements if there are less than the required number and deletes elements if there are more.
As a side note, an alternative to the deletes is relevance.
The elements remain in the instance, but are excluded from the user
interface, saving repeated insertions and deletions if size
changes often, and only requiring actual changes when the new value of
size becomes larger than any previous.
<bind ref="value" relevant="position() < @size"/>
A similar approach can be used for two-dimensional arrays, by first growing a row, and then duplicating that sufficiently:
<instance>
<game size="10" xmlns="">
<row><c clicked=""/></row>
</game>
</instance>
<action ev:event="xforms-ready">
<insert ref="row/c" while="count(//c) < /game/@size"/>
<insert ref="row" while="count(//row) < /game/@size"/>
</action>
These examples show that you can hook into the invariant mechanism in order to maintain your own invariants.
How can we introduce invariants that affect structure, without resorting to events?
The first thing to note is that the calculate attribute
contains both the signals that indicate that the invariant needs restoring, and
the method to restore it.
<bind ref="tileX" calculate="floor(../worldX div ../scale)"/>
On the other hand, in the structure examples above, the signal, the value changing, is separate from the restore mechanism, the inserts and deletes.
This is possibly a clue to how the mechanism could be integrated.
Here is a strawman suggestion:
<structure requires="count(value) = @size"> <insert ref="value" while="count(value) < @size"/> <delete ref="value[last()]" while="count(value) > @size"/> </structure>
The boolean requires attribute becomes part of the dependency
algorithm.
The body of the structure element becomes part of the
rebuild in the update mechanism.
This solves a simple case. There are more complex ones.
For instance, you can repeat over a filtered set of values:
<repeat ref="data[contains(., instance('search')/q)]">
but it would be useful to be able to say this structure contains the data that matches the search string. Again a strawman:
<structure ref="subset"
calculate="data[contains(., instance('search')/q)]"/>
or possibly
<bind ref="subset"
structure="data[contains(., instance('search')/q)]"/>
This looks at first like it would be horribly inefficient, but it is important not to throw the baby out with the bathwater: what we are asking with requirements analysis is "what would be useful to be able to do?".
We shouldn't prematurely optimise by saying it would be inefficient, thus not a good solution; we should ask what we want to do, and then later work out how to implement it efficiently.
Past examples of this: recursive functions; general assignment.
We can't cover all possible data structures and their invariants today.
But let us explore some general invariants over lists, since they are so useful.
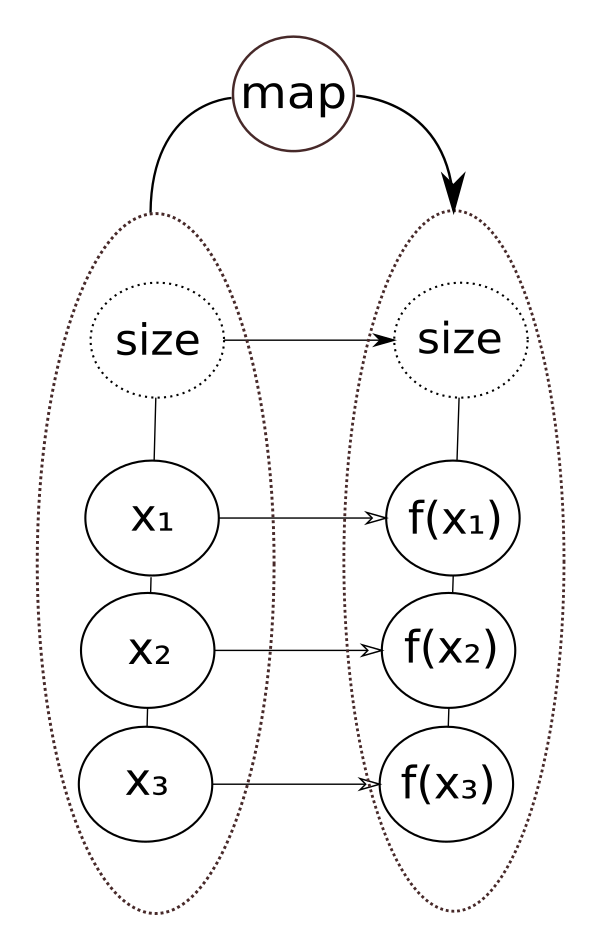
Useful structural invariance functions apart from filter, include map, reduce (or fold), and sorting.
These specify very high-level relationships between structures, thus allowing the easy specification of computational intent.
General computing terminology uses "filter, map, reduce".
Although XPath uses for-each for map and fold for reduce, I will largely stick to the older terminology.
XForms already has an inherent map ability, though not expressed as such, since an invariant like
<bind ref="y" calculate="f(...)"/>
does the calculate for every element matched by the nodeset in the
ref.
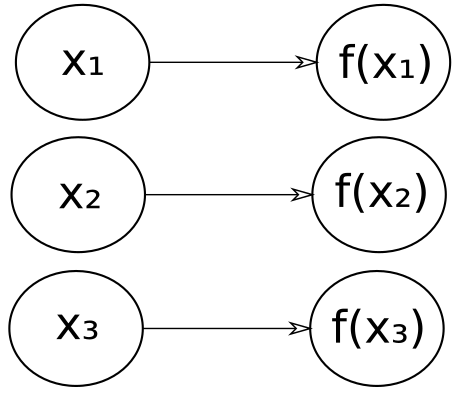
XForms also has some specific versions of reduce, such as
sum(), but not a generalised one.
However, the most-recent version of XPath has added these higher-level functions, which allows them to be used in new versions of XForms.
The update mechanism sees the collection of invariants as a tree of dependent calculations only some of which fire at each iteration.
If you compare that with high-level functions like filter, map, and reduce, and regard them not as atomic calculations, but as an assemblage of sub-calculations, then in fact they fit very well into the recalculation mechanism.
One of the reasons that the XForms dependency graph is so useful is that if a value changes, only dependent values need be recalculated.
Initially (at least in principle), all values are calculated, but after that, changes only cause a subset of the values to be updated.
The update efficiency indicates how much work has to be done to restore the invariant.
For instance, a map is just a sequence of sub-expressions each calculating one function application for each element of the sequence of input values (along with a structural guard on the size).
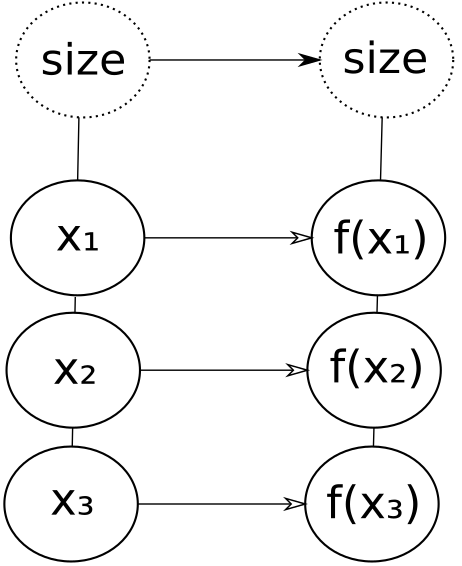
So this has an update efficiency of O(1).
Similarly, a reduce can be seen as a graph of sub-reductions.
XPath has two reduction functions, fold-left and fold-right. Unfortunately (for XForms), these are computational very specific: you start the reduction either from the left or the right.
However, many typical reductions, such as sum, product, and concatenate, are directionally neutral, since their underlying dyadic operators (namely +, ×, and ++) are associative:
a + (b + c) = (a + b) + c
and we can take advantage of this.
For instance, regarding a fold-left as a graph of dependent calculations, it would need to be implemented like this:
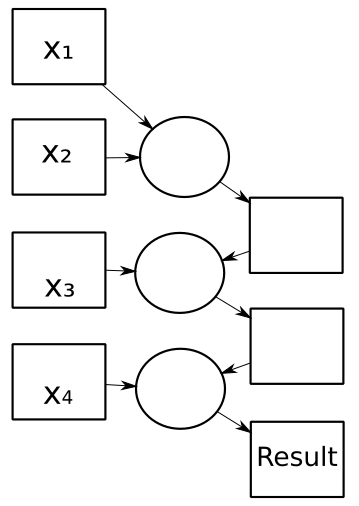
with an update complexity of O(n).
On the other hand, a directionally-impartial fold could be implemented like this:
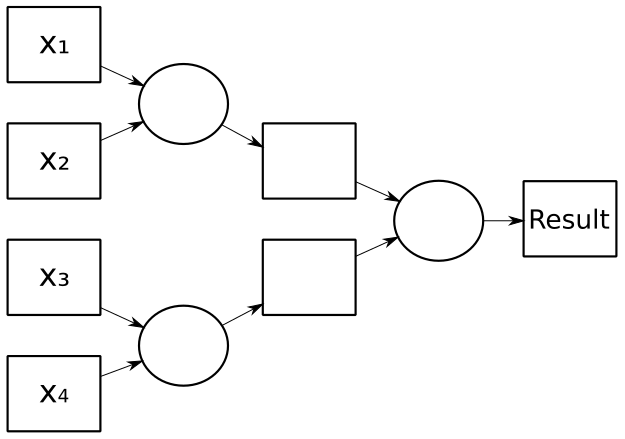
with an update complexity of only O(log(n)).
O(n) vs O(log(n)) is a big difference for large lists.
If you double the size of the list:
Put another way,
This is because if a value changes in the middle of the tree or sequence, the other parts of the assemblage don't have to be recalculated.
The upshot is that you can regard structural invariants as just a higher-level form of invariant, ones whose purpose is to manage the collection of lower-level simple invariants.
The rebuild phase of the XForms update mechanism can then be considered a higher-level version of recalculate.
The advantage of invariants for the programmer is that they state at a high level the intent of the computations, and leave a lot of the administrative detail to the computer.
This is how it should be, and is part of a historical movement in computing, handing off more of the work to the computer.
Structural invariants can be seen as a higher-level version of the simple invariants, where the work of the invariant is rebuilding networks of lower-level simple invariants.
In such a way, structural invariants can be merged into the existing invariant recalculation mechanism.
Advert: Declarative Amsterdam, November 4/5 (Hybrid)
[xf1] John M. Boyer (ed.), XForms 1.1, W3C, 2009, https://www.w3.org/TR/xforms11/
[xf2] Erik Bruchez, et al. (eds.), XForms 2.0, W3C, 2021, https://www.w3.org/community/xformsusers/wiki/XForms_2.0
[xf3] Steven Pemberton, An Introduction to XForms, XML.com, 2018, https://www.xml.com/articles/2018/11/27/introduction-xforms/ .
[update1] Model Processing, in [xf2] https://www.w3.org/community/xformsusers/wiki/XForms_2.0#Model_Processing
[update2] Recalculation Sequence Algorithm, in https://www.w3.org/community/xformsusers/wiki/XForms_2.0#Recalculation_Sequence_Algorithm
[dijkstra] EW Dijkstra, A Discipline of Programming,
Prentice Hall, 1976, ISBN 0-13-215871-X
[map] Steven Pemberton, Live XML Data, in Proc. XML London 2014, pp 96-102, ISBN 978-0-9926471-1-7, https://xmllondon.com/2014/xmllondon-2014-proceedings.pdf#page=96
[events] Shane McCarron et al., XML Events, W3C, 2003, http://www.w3.org/TR/xml-events
[refcounts] P.G. Hibbard, P. Knueven, and B.W. Leverett, A Stackless Run-time Implementation Scheme, Proc. 4th International Conference on the Description and Implementation of Algorithmic Languages, pp.176-192 (1976).
[views] J. Ganzevoort. Maintaining presentation invariants in the Views system, Report CS-R9262, CWI Amsterdam, 1992, https://ir.cwi.nl/pub/5342/05342D.pdf