From Wikipedia, by Cmichel67 - Own work, CC BY-SA 4.0, Link
Now 83, he has had an amazing life. For instance,
Which is what I want to talk about now.
One of his books:

The argument behind How Buildings Learn is that buildings should be designed to anticipate change.
Architects can't know how a building will be used over its whole life, and so should design with the future in mind, as well as the present.

As reported in How Buildings Learn
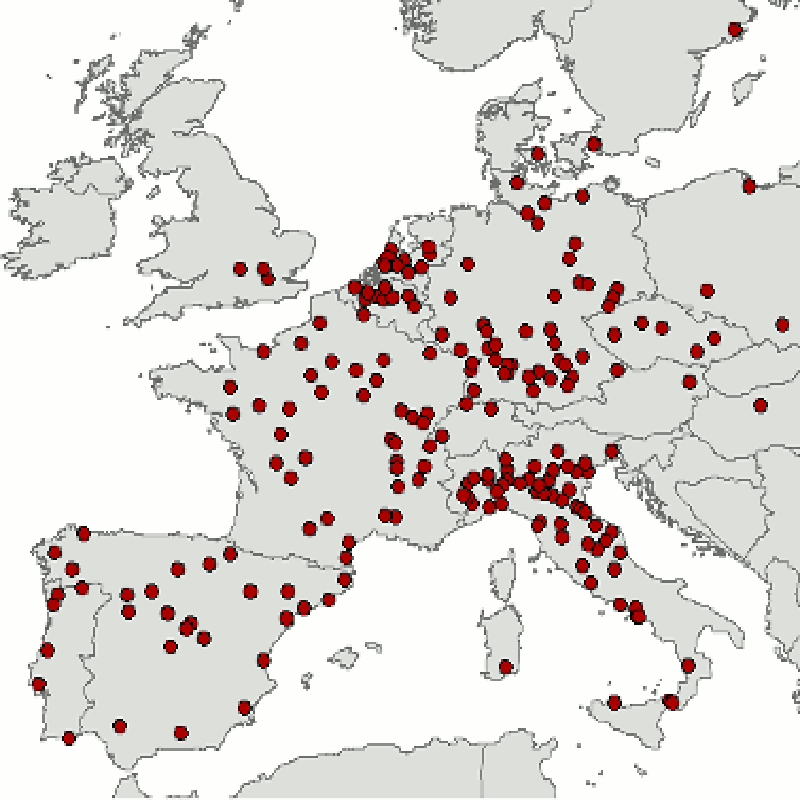
Built in 1379, New College has a dining hall with huge oak beams in the roof.
Eventually the beams needed replacing. But where do you find oak beams? They asked the University forester if he knew:
- "Which college are you from?"
- "New College."
- "Well, I've got your trees".
It turns out that around the time that New College was built, they planted new trees to be ready for when they would need them.
We don't see that sort of attitude much these days.
When New College was being built, all books were still hand-written, and very expensive.
In 1424 The University of Cambridge had one of the largest libraries in Europe: 122 books.


When Gutenberg introduced the printing press around 1450, it had several effects:
Before, producing a single copy of a book took several years. By 1500:
And bear in mind, you didn't just "set up a print shop". You had to:
It was a real revolution.
 Thanks to the high quality of the materials they
used, and to libraries, we can still read the books they printed, 500 years
ago.
Thanks to the high quality of the materials they
used, and to libraries, we can still read the books they printed, 500 years
ago.
Which is one of the points of books: to store information for later ages.
Before the printing press, because vellum was so expensive, books would occasionally be reused, by scraping off the ink, and rewriting over them.
With printed books you didn't need to do this any more.
 For the first 50 years, they made
books look as much like manuscripts as possible
For the first 50 years, they made
books look as much like manuscripts as possible
This was partly because that was what was expected of a book at the time.
It was where the money was.
But also, they didn't know any different.
After about 50 years, readable fonts were introduced, and the features we now expect from a book.
This was probably after the death of the first generation of printers.
In many ways, the development of the web has echoed that of the book:
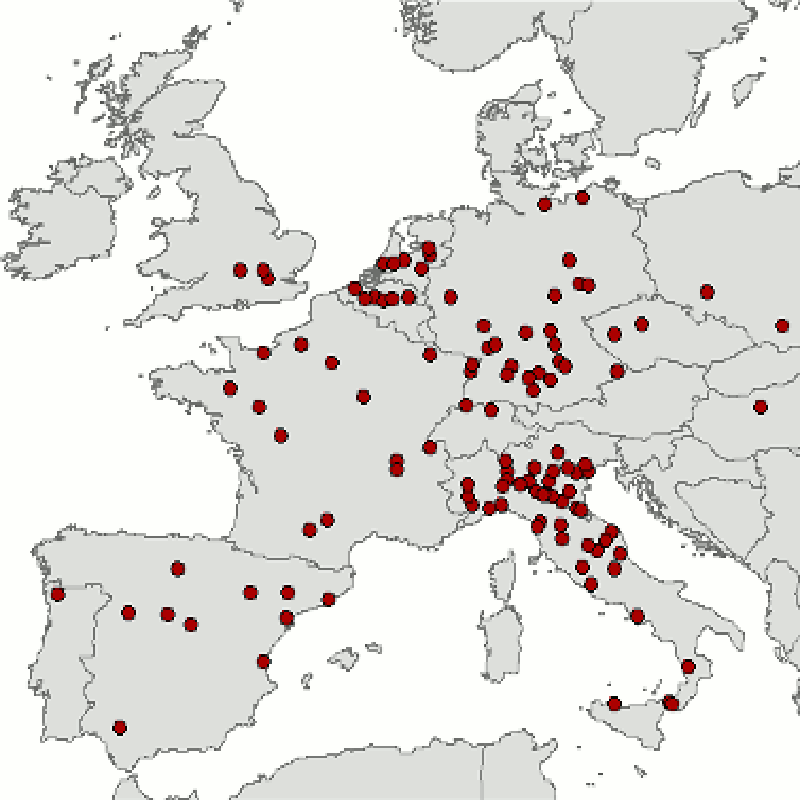
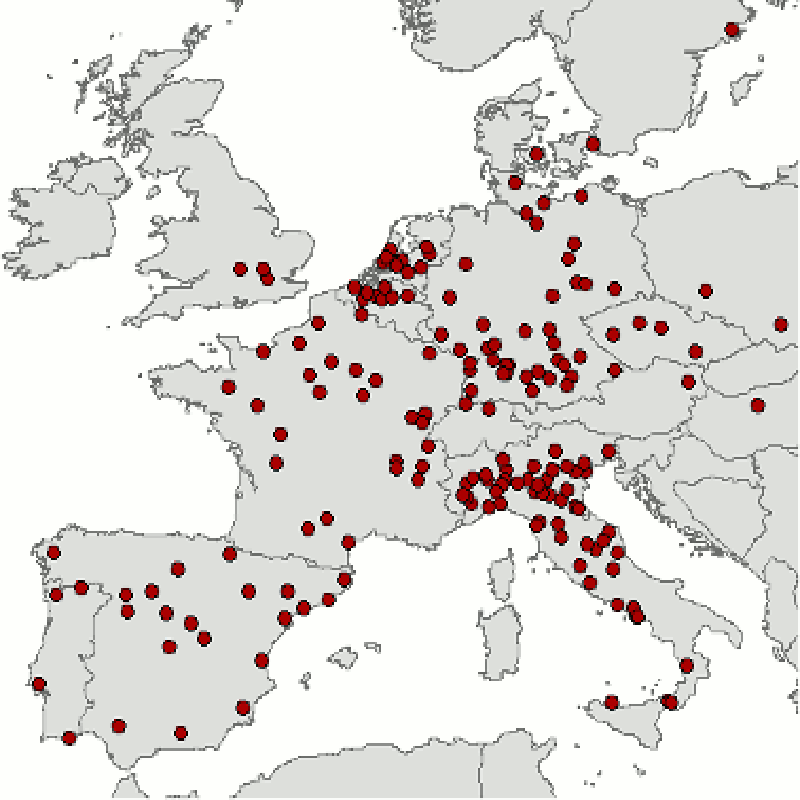
Interesting Amsterdam information-explosion factoids:
 Installing the
first municipal computer, in Norwich, 1957
Installing the
first municipal computer, in Norwich, 1957
This year is only sixty-five years since the start of public computing. Computing is still very young.
Last year was the 30th anniversary of the Web being released.
I consider us still to be in manuscript-imitation phase of the Web: we're
still driven by how it used to be.

Tim Berners-Lee and Steven discussing HTML
Many people think that Tim Berners-Lee must have been a genius to have invented the web, but in fact at the time there were several alternatives being developed.
Why did the Web succeed where the others didn't?
We learn in school what numbers are, and how to add, subtract, multiply and divide.
However, when we get to square roots, we are only told:
The square root of a number is a number that when you multiply it by itself, you get the original number.
This is a declarative definition. It tells you what something is, it tells you how to recognise it, but it doesn't tell you how to calculate it.
Most people know what a square root is, few people leave school knowing how to calculate one.
Here is a procedural definition of square root:
function f a:
{
x ← a
x' ← (a + 1) ÷ 2
eps ← 1.19209290e-07
while abs(x − x') > eps × x:
{
x ← x'
x' ← ((a ÷ x') + x') ÷ 2
}
return x'
}
HTML, the language underlying the web, was largely declarative.
In the early days of HTML, there were very few browsers, and only one or two of importance.
Browser makers were very tempted to add to HTML. We still live with the bad design decisions of Netscape...
W3C was partly created in order to protect HTML, so that everyone used the same HTML, and everyone agreed on new features.
Unfortunately, recently the browser makers, led by Google, have taken over HTML, and are now changing it radically, and badly, to create HTML5, largely forgetting its declarative foundation.
number: optional sign, digit+. optional sign: "-"?. digit: "0"; "1"; "2"; "3"; "4"; "5"; "6"; "7"; "8"; "9". A number has its normal everyday meaning.
This is:
2.4.4 Numbers
2.4.4.1 Signed integers
A string is a valid integer if it consists of one or more ASCII digits, optionally prefixed with a "-" (U+002D) character.
A valid integer without a "-" (U+002D) prefix represents the number that is represented in base ten by that string of digits. A valid integer with a "-" (U+002D) prefix represents the number represented in base ten by the string of digits that follows the U+002D HYPHEN-MINUS, subtracted from zero.
The rules for parsing integers are as given in the following algorithm. When invoked, the steps must be followed in the order given, aborting at the first step that returns a value. This algorithm will return either an integer or an error.
Otherwise, if the character indicated by position (the first character) is a "+" (U+002B) character:
2.4.4.2 Non-negative integers
A string is a valid non-negative integer if it consists of one or more ASCII digits.
A valid non-negative integer represents the number that is represented in base ten by that string of digits.
The rules for parsing non-negative integers are as given in the following algorithm. When invoked, the steps must be followed in the order given, aborting at the first step that returns a value. This algorithm will return either zero, a positive integer, or an error.
So the HTML5 definition of signed numbers is 16 times longer and has internal inconsistencies.
It will not surprise you to learn as a result that the HTML5 spec is very large.

One of the advantages of the web is that you can read its specification without
having to print it out
Declarative methods are not only for specification.
For instance, in HTML, elements like <h1> just announce
that this is the top-level heading, without requiring anything about how it
looks, such as in a large bold font.
<h1>The 100 year web</h1>
Or the <a> element:
<a href="talk.html" title="..." target="..." class="..." >My Talk</a>
This compactly encapsulates a lot of behaviour including
Doing this in programming would be a lot of work.
CSS, the web styling language, is another example of a successful declarative approach.
When W3C started the CSS activity, Netscape, at the time the leading browser, declined to join, saying that they had a better solution, JSSS, based on Javascript.
Instead of
h1 { font-size: 20pt; }
you could use script to say
document.tags.H1.fontSize = "20pt";
Which brings us to Javascript.



The HTML5 designers, rather than designing new declarative ways of dealing with new use cases, instead turned HTML into a programming environment.
"You know... I feel like I blinked and then all of the sudden what I thought was my job was suddenly not my job but now I'm being told that I need to do this other stuff that I don't even like and people wonder why I'm wielding a stiletto like a weapon and screaming, "I HATE JAVASCRIPT! YOU CAN'T MAKE ME! NO MEANS NO!" and considering a second career in comedy writing." -- Nicole Henninger
Without going into detail about why Javascript is such a bad language, and therefore barely fit for purpose, let's look at the consequences of dropping a declarative approach for programming.
One of the problems with using programming for functionality is that standardisation disappears.
Example: CSS presentation mode (which I am using here). This allows you to specify how any document can be formatted when doing a presentation.
Alas, HTML5 has taken the approach that you can do this better in Javascript. No one supports Presentation Mode any more. And there are now lots of Javascript packages to do presentation.
ALL DIFFERENT!
You can no longer switch in a different presentation package, and use that, because you have to CHANGE THE DOCUMENT.
The programmers are doing the document design, so all the documents become proprietary, and there is no interoperability, which is the whole point of standards.
Javascript is why there are so few new elements in HTML5: they haven't done any design, and instead said "if you need anything new, you can always do it in Javascript".
And many have.
Wikipedia lists 26 packages of Javascript (such as Angular, Dojo, and Bootstrap) that you can use to build your webpages.
They are not interchangable, thus effectively creating 26 different versions of HTML.
So which framework do you use? And what happens when:
YOU HAVE TO CHANGE ALL YOUR DOCUMENTS.
This is why standards are needed, not proprietary formats like frameworks.
"The U.K.’s GDS (Government Digital Service) ran an experiment to determine how many of its users did not receive JavaScript-based enhancements, and it discovered that number to be 1.1 percent, or 1 in every 93 users. For an ecommerce site like Amazon, that’s 1.75 million people a month, which is a huge number." -- alistapart
To look at the webpage of one single tweet of 140 characters, you have to download just under a megabyte. It's 5200 lines of HTML before you even get to the five Javascript packages.
The whole of James Joyce's Ulysses is only half as long again.
"An article from 2012 titled "The Growing Epidemic of Page Bloat" warns that the average web page is over a megabyte in size.
The article itself is 1.8 megabytes long.
An article two years later, called “The Overweight Web" warns that average page size is approaching 2 megabytes.
That article is 3 megabytes long.
If present trends continue, there is the real chance that articles warning about page bloat could exceed 5 megabytes by 2020." -- The Website Obesity Crisis
"Because of #GDPR, USA Today decided to run a separate version of their website for EU users, which has all the tracking scripts and ads removed. The site seemed very fast, so I did a performance audit. How fast the internet could be without all the junk!
5.2MB → 500KB
They went from a load time of more than 45 seconds to 3 seconds, from 124 (!) JavaScript files to 0, and from a total of more than 500 requests to 34." -- Marcel Freinbichler
One day we will all be 80, and still need to be able to use the web.
"Many developers who have grown up only using frameworks have a total lack of understanding about the fundamentals of HTML, such as valid and semantic markup ... This is of great concern as semantic markup is one of the core principles of an accessible web." -- Russ Weakley
The web is the way now that we distribute information. We will need the web pages we create now to be readable in 100 years time, just as we can still read 100-year-old books.
Requiring a webpage to depend on a particular 100-year-old implementation of Javascript is not exactly evidence of future-thinking.
Declarative markup is easier to keep alive because it is independent of the implementation!
 Einstein: 14 March 1879 – 18
April 1955
Einstein: 14 March 1879 – 18
April 1955
CWI is in possession of a couple of letters from him to a colleague (and the replies)
 CWI
also has a letter from MC Escher thanking the CWI in 1954
for helping his work to achieve recognition.
CWI
also has a letter from MC Escher thanking the CWI in 1954
for helping his work to achieve recognition.
That such letters still exist is a piece of lucky.
Usually such pieces of ephemera are not appreciated for their value until much later, often long after they have been thrown away.
 In the 80's I was working on
the programming language ABC (the
forerunner of Python), and we had amongst other computers an Apple Lisa (the
forerunner of the Apple Macintosh).
In the 80's I was working on
the programming language ABC (the
forerunner of Python), and we had amongst other computers an Apple Lisa (the
forerunner of the Apple Macintosh).
It was a big thing, and after the project it sat on a desk unused and getting in the way, until the point that it was just a worthless slow lump, with the result that it was unceremoniously thrown away.
Big mistake: an Apple Lisa is now a historic computer, and would be worth way more than what it cost when we bought it; just the mouse would fetch more than $500 now... It is one of a few computers that has increased in value over the years.
But at the time, no one considered that this heap of junk would actually ever be valuable.
 Before 1978 the BBC had no
archiving policy.
Before 1978 the BBC had no
archiving policy.
So many seminal events were erased (for economic reasons!):
See "Wiping" on Wikipedia for more.
One of the unfortunate side-effects of digitisation is that in the future we probably won't have any paper artefacts like letters to find in library archives:
And what do many organisations do when the information is no longer needed? Delete the lot!
Gone:
You can't argue it from a cost perspective: 1 gigabyte of diskspace costs 3 or 4 cents now (and dropping), and spread over the lifetime of a disk is negligable.
Don't just back up the data and delete everything.
Webpages should be preserved. I recently found some important data on the homepage of someone at MIT who had left in 1996!
And webpages should be preserved at the same URL they always had. As Tim Berners-Lee says: Cool URLs don't change!
Of course that means a lot of cruft will be kept.
But who cares? It is almost free to keep.
I still have all my email from the 90's: there's a lot there that's not of interest (at least, not yet), but thanks to it we now know when CWI first had a website, and I know how much filestore I was using in 1992 (117MB if you're interested, much of it binaries).
The only way to find out which data will be valuable is to wait and see, and that means we have to keep it around long enough to let it accrue its value.
The Web has become too important as infrastructure to be treated lightly.
The Web itself must return to declarative foundations to make it durable and persistent.
But attitude by web creators is also important: design with the future in mind, as well as the present.