A Pilot Implementation of ixml
Steven Pemberton, CWI, Amsterdam

 Numbers
are abstractions: you can't point to the number three, just three bicycles, or
three sheep, or three self-referential examples.
Numbers
are abstractions: you can't point to the number three, just three bicycles, or
three sheep, or three self-referential examples.
Three is what those bicycles and sheep and examples have in common.
You can represent a number in different ways:
3, III, 0011, ㆔, ३, ፫, ૩, ੩, 〣, ೩, ៣, ໓, Ⅲ, ൩, ၃, ႓, trois, drie.
You can concretise numbers as a length, a weight, a speed, a temperature.
But in the end, they all represent the same three.
Data is an abstraction too!
We are often obliged for different reasons to represent it in some way or another.
But in the end those representations are all of the same abstraction.
(http recognises this too: a URL represents a single resource; content negotiation allows the selection of a particular representation of that resource)
Takes a representation of data (typically with implicit structure)
Uses a description of the format of that data to recognise the data's structure
Creates a representation with explicit structure
Some representations are weaker than others: they may not be able to faithfully represent all of the abstraction, and are therefore not reversible.
XML is probably the best available general notation for generating the representation of any abstraction.
The intention behind ixml is to allow extracting abstractions from representations; of converting weaker representations of abstractions into more explicit representations, with XML therefore an excellent target for that.
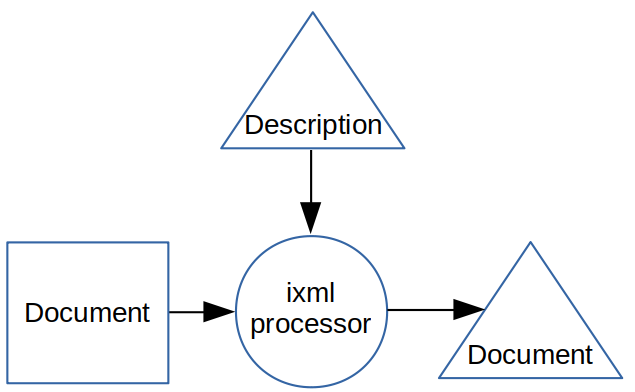 An ixml processor takes a document in a particular
(textual) format, along with a description of that format, in the form of a
grammar, and uses it to parse the document.
An ixml processor takes a document in a particular
(textual) format, along with a description of that format, in the form of a
grammar, and uses it to parse the document.
This produces a structured parse tree, which can then be processed in a number of ways, such as serialization as XML.
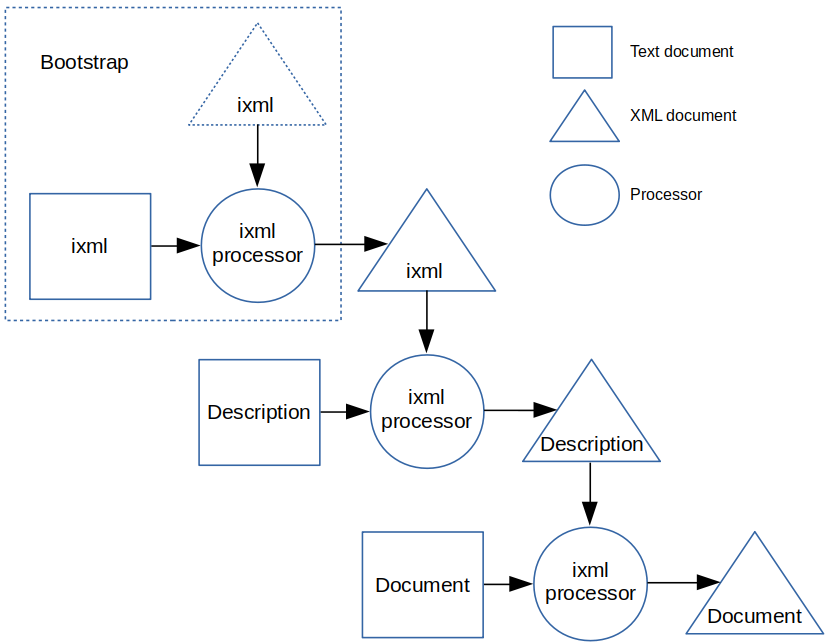
The
format description is drawn as a structured document.
However, it is normally supplied in textual form, and is processed in exactly the same way, by the ixml processor, but using a description of the ixml format.
This results in the structured version of the description.
An ixml description is a grammar consisting of a series of rules.
A rule consists of a name, and a number of alternatives separated by semicolons:
statement: assign; call; if; while.
Alternatives consist of a sequence of zero or more terminals and nonterminals separated by commas:
assign: id, ":=", expr.
Input that matches the grammar is parsed into a parse tree, which is then serialised as XML.
assign: id, ":=", expr. expr: id; number. (etc)
So for input "i:=0", you would get
<statement>
<assign>
<id>i</id>:=<expr><number>0</number></expr>
</assign>
</statement>
By default, all input characters end up in the output. Only tags are added, expressing the structure.
So-called marks can be added to rules to affect the serialization.
Rules can be marked to be serialised as attributes:
assign: @id, ":=", expr.
would give
<assign id="i">:=<expr><number>0</number></expr></assign>
Terminals can be marked to be deleted from the serialisation:
assign: @id, -":=", expr.
would give
<assign id="i"><expr><number>0</number></expr></assign>
Deleting nonterminals only removes the surrounding tags, not the content:
assign: @id, -":=", -expr.
would give:
<assign id="i"><number>0</number></assign>
A recent addition to ixml are insertions which allow characters to appear in the serialisation that weren't in the input:
assign: @id, -":=", -expr, +";".
which would give
<assign id="i"><number>0</number>;</assign>
You have now seen the essence.
For full details read the specification, or see the tutorial.
The hardest part of getting an article into Docbook format (the format used by this conference) is getting the bibliography right.
The bibliography for the paper was produced with the help of ixml. For instance, the text
[spec] Steven Pemberton (ed.), Invisible XML Specification, invisiblexml.org,
2022, https://invisiblexml.org/ixml-specification.html
was processed by an ixml grammar whose top-level rules were
bibliography: biblioentry+. biblioentry: abbrev, (author; editor), -", ", title, -", ", publisher, -", ",
pubdate, -", ", (artpagenums, -", ")?, (bibliomisc; biblioid)**-", ", -#a.
<biblioentry>
<abbrev>spec</abbrev>
<editor>
<personname>
<firstname>Steven</firstname>
<surname>Pemberton</surname>
</personname>
</editor>
<title>Invisible XML Specification</title>
<publisher>invisiblexml.org</publisher>
<pubdate>2022</pubdate>
<bibliomisc>
<link xl-href='https://invisiblexml.org/ixml-specification.html'/>
</bibliomisc>
</biblioentry>
There are many known parsing algorithms, and most have restrictions on what can be processed.
ixml requires implementations to use a general parsing algorithm, without extra restrictions.
The pilot implementation of ixml uses Earley as one of the earliest and best-known of the general parsing algorithms.
Earley can be seen as a pseudo-parallel parsing algorithm.
When parsing with a rule like
sentence: a; b; c.
it splits into three parallel sub-parsers one for each alternative.
If a sub-parser fails at any point, it terminates without further ado; if it succeeds, it records its sub-parsetree(s), and terminates.
After parsing, what remains is a so called parse-forest: a collection of linked sub-parse-trees.
The first action is to see if the parse has been successful, by looking if there is a successful parse node for the root symbol that starts at the first character position and ends at the last.
If so then serialisation can begin.
Serialisation is a question of doing a tree walk:
Attributes come before element content, and so for non-deleted nonterminals you do one sub-walk for the attributes, and then one for the content.
Because of element deletions such as
assign: -target, -":=", expr. target: @id.
since the element that the id attribute is ostensibly on is deleted, the attribute has to move up to the nearest non-deleted element:
<assign id="i"><expr>...</expr></assign>
so the tree walk for attributes has to look not only at the level of the (undeleted) element, but also recursively within deleted sub-elements.
The parse may have been ambiguous, satisfying the rules of the grammar in more than one way.
The serialisation tree-walk doesn't care: as long as the parse has been successful it will just serialise one of the parses.
However, the consumer of the serialisation should know that the serialisation is only one of the possible cases.
Therefore, ixml requires ixml:state="ambiguous" to be added to
the root element of the serialisation of ambiguous parses.
This involves a simple initial tree-walk to discover if any route from the top node is ambiguous.
The primary aim:
Written in an interpreted language with very-high-level data types, (ABC)
About 500 lines of code for the bootstrap parser, 700 for the full processor.
The processing diagram suggests that ixml always serialises to XML.
But since the description document is input in the next step to parse the final document, it is better to serialise straight to memory, into the form required by the parser.
This allows for some simplifications, and speeds up processing, since it eliminates one whole parsing phase.
An ixml grammar can be seen as a function mapping one representation to another. Round tripping is just reversing that process.
For a grammar with no deletions and no attributes, it is trivial, since it just involves concatenating the element contents.
<statement>
<assign>
<id>i</id>:=<expr><number>0</number></expr>
</assign>
</statement>
=>
i:=0
Deletions complicate matters.
If there are only element deletions, then it remains trivial, because all input characters are still in the output; only some element tags have been omitted.
However, with terminal deletions, characters are lost that have to be restored.
assign: id, -":=", expr.
would give
<assign><id>i</id><expr><number>0</number></expr></assign>
To deal with this in the general case, we have to parse the serialisation using the grammar that produced it, with a similar parser to Earley, in order to discover which characters have been deleted.
To parse a (non-deleted) nonterminal, you must expect the start tag for that rule. For instance, for
statement: assign; call; if; while.
you expect
<statement>
and then initiate four parallel sub-parsers, one for each of the
alternatives, which to succeed must also be followed by the terminating tag
</statement>.
To parse a deleted nonterminal, you just initiate the sub-parsers.
To parse a (non-deleted) terminal, you must just expect the same string in the element content at the current point.
To parse a deleted terminal, you match zero characters, and insert the string in the parse.
To parse an insertion, you have to expect the characters in the string in the same way as a non-deleted terminal, but insert nothing in the parse.
One other challenge is dealing with attributes.
Attribute content appears earlier in the parse-tree than element content.
Therefore attributes have to be held in abeyance, as separate input streams, until the point in the parse where they appear in the grammar.
Then the input comes from the serialisation of the attribute, and all sub-rules are treated as if deleted, until the end of the rule forming the attribute.
The result of this process will be a (potentially ambiguous) parse tree.
For a serialisation like
<assign id="i"><number>0</number>;</assign>
being parsed against
assign: @id, -":=", -expr, +";".
you will get a parse tree like
<assign><id>i</id>:=<expr><number>0</number></expr></assign>
from which you can concatenate the element content to give
"i:=0".
However, for a grammar that includes a rule like:
term: id; number;
-"{", expr, -"}";
-"(", expr, -")".
where expressions may be bracketed with either {} style or () style brackets, the deletions mean that both of these latter two alternatives will produce exactly the same serialisation, namely:
<term><expr>...</expr></term>
Parsing the serialisation back will give two successful parses:
<term>{<expr>...</expr>}</term>
<term>(<expr>...</expr>)</term>
in other words, an ambiguous parse.
Just as with serialisation, we have to choose one.
In other words, because the serialisation deletes the information about which brackets were used, we can't always round-trip perfectly.
Similarly, if a serialisation deletes all spaces or comments in the input, there is no way to recreate them. They are lost in the round-tripping.
Designing a notation requires many aspects to be taken into account simultaneously, such as usability, functionality, and ambiguity. Having an implementation that is easily modifiable during design of the notation is almost essential for good progress.
The current pilot implementation has served well, and while other implementations are now emerging, it will nevertheless be retained for future design research.
This is the formal announcement of the release of version 1.0 of ixml!
Nip over to invisiblexml.org in order to see:
And come to the tutorial on Saturday!