Abstract
Data is an abstraction. In order to transfer it or talk about it, the
abstraction has to be represented using some notation.
The design of notations is a neglected area of study, yet the designs affect
both what you can represent, and what you can do with what is being
represented.
XML is currently the most suitable and flexible of the available notations
for representing data abstractions, and yet it has restrictions and some
shortcomings that get in the way of properly representing abstractions.
This paper discusses the issues, and reflects on which aspects of XML
obstruct abstractions.
Keywords
Notation design, data abstractions, representation, XML
Cite: Steven Pemberton, On the Representation of Abstractions,
Proc. Declarative Amsterdam, 2022,
https://declarative.amsterdam/program-2022
Contents
Abstractions
This paper arises out of the design and implementation of Invisible XML
(ixml) [ixml], a notation and
process whose principle aim is the extraction of structured abstractions from
representations (where the structure is typically implied). Even though the
main use of ixml currently is to serialise those abstractions as XML [xml], once you have the abstractions, there are many things you
can do with them.
For example, the first stage of the ixampl implementation of ixml
[ixampl] serialises ixml
directly into memory in the form expected by the Earley parser. XML processors
could do something similar, and have ixml as a pre-processor that serialises
(non-XML) documents directly into an internal memory form, such as XDM [xpath].
Data as Abstraction
We are often obliged for different reasons to represent data in some way or
another, for storage, transport, or just to be able to talk about it. We can
represent data in many different ways, but in the end those representations are
all of the same abstraction; there is no essential difference between the
JSON
{"time": {"hours": 17; "minutes": 23; "seconds": 9}}
and an equivalent XML
<time hours="17" minutes="23" seconds="9"/>
or
<time>
<hours>17</hours>
<minutes>23</minutes>
<seconds>9</seconds>
</time>
or indeed
Time: 17:23:09
since the underlying abstractions being represented are the same.
To represent abstractions, we need notations, and notations need to be
designed. Currently XML is the best available standardised notation available
for generalised data representation. But what were the design decisions taken
when designing XML, and to what extent do they fully support the representation
of abstractions?
XML
The success of HTML in the 1990's, which had used SGML as its document
format, had focussed the world's attention on SGML. The first version of HTML
had used SGML somewhat sloppily, but later versions used it properly.
SGML is a complex language (it is rumoured that it has never been completely
implemented), and so as part of the ongoing HTML effort at the time, it was
decided to simplify SGML to produce a subset, which got named XML.
At the time I was tasked with leading the group required to produce the XML
representation of HTML [xhtml], and so that design was
going to be important for us, and we watched it with interest. They largely did
a good job: it is hard to avoid the second system effect [brooks].
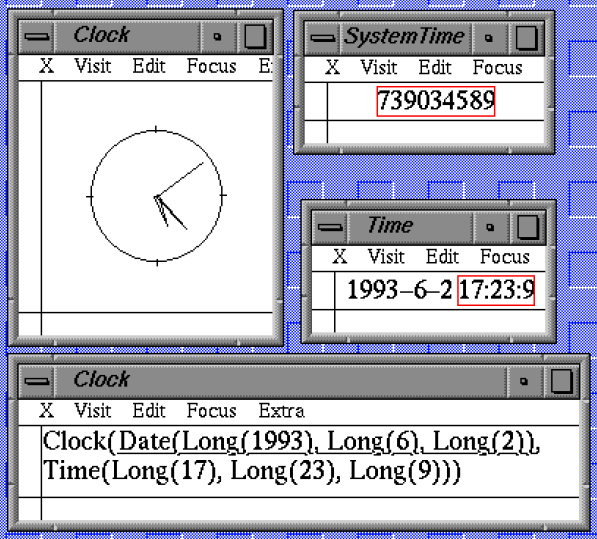
However, I had just come from a project designing an "environment" called
Views [views]. This was a system that amongst other things
had:
- hypertext,
- stylesheets,
- structured graphics,
- client-side scripting, and
- an extensible data model.
This data model had no 'standard' external representation: you used
stylesheets to display the data in any way you wanted. In other words, we
started with the abstractions -- the design of the data model -- and
representations followed. For instance, the image shows four different 'views'
of a single value, the system time.
This work revealed much about the requirements for data representation, and
as a result aspects of the design of XML during its development raised several
questions on the reason behind the decisions made.
It was only years later this quote from Tim Bray, one of the developers of
XML made everything clear:
"You know, the people who invented XML were a bunch of publishing
technology geeks, and we really thought we were doing the smart document
format for the future. Little did we know that it was going to be used for
syndicated news feeds and purchase orders." [queue]
Reading that explained a lot: in other words, they were designing using a
different set of requirements than I had imagined.
XML has been a standard now for more than twenty years, and it has survived
the test of time. That notwithstanding, there have in that time been many
proposals to redesign XML, or design alternatives. For instance, Tim Bray
himself has said:
Just drop the <!DOCTYPE>. Immense numbers of
problems vanish. Mind you, the MathML crowd will come over to your house and
strangle your kittens. But really, in the whole world they're the only ones
who care; if I were XML dictator, I'd drop it in a microsecond. [doctype]
That was in a comment to a proposal called XML5 [xml5] to redesign XML (apparently only in order to 'improve'
its error recovery). Others include:
- Microxml: Proposed by James Clark as smaller and 'dramatically' simpler,
and allowing error-recovery. [microxml]
- Ftanml: Michael Kay's exercise at designing something better. Good at
data and structured documents; concise; human-readable; with a data-model
applicable to programming languages, and deals with the whitespace problem.
[ftanml]
- Binary XML: In several versions described as "compacter". [binaryxml]
- XML 1.1: Which changed the definition of names and allowable characters.
[xml11]
Error recovery
A couple of the redesigns specifically mentioned error recovery.
Information representation is a type of contract between the producer and
the consumer: both want the consumer to consume exactly what was produced. If
the consumer silently tries to guess what was really meant, that contract has
been broken.
Error recovery is an example of the application of the robustness principle
(also known as Postel's Law) which states [postel]:
"Be conservative in what you produce,
be liberal in what you accept from others"
The Robustness Principle was proposed in order to improve interoperability
between programs [robustness], which has been
expressed by one wag [notforyou] as:
"you’ll have to interoperate with the implementations of others with
lower standards. Do you really want to deal with those fools? Better to
silently fix up their mistakes and move on."
The robustness principle can be useful, but despite its alternative name,
it's not a law! Care should be taken when you applying it, because of the
problem of contract-breaking.
Robustness and programming languages
Luckily, the robustness principle is not applied in general to programming
languages: it is not helpful if the compiler tries to guess what you really
meant when it comes across an error!
Nevertheless, it was tried in PL/I, and the result was terrible. The only
way you could find mistakes was to run tests, and as Dijkstra famously observed
[Dijkstra]:
“Program testing can be used to show the presence of bugs, but never
to show their absence!”
It is much better for the compiler to tell you about the problems before
they occur: studies have shown that 90% of the cost of software comes from
debugging, so reducing the need for debugging is really important.
Unfortunately the robustness principle has also been applied in Javascript.
For instance, because of it, the expression ++[[]][+[]]+[+[]]
evaluates to the string "10" [javascript]. Javascript
is for this reason very hard to debug, since it silently accepts certain
classes of errors, that then don't show up until much later.
As an example, I literally spent an afternoon solving a problem in someone
else's code. The Javascript was calculating the number of seconds from a number
of hours and minutes. The essence of the code was this:
seconds = 60 * (hours * 60 + minutes)
I knew that hours was 1, and minutes was 0. So the
answer should be 3600, but it was returning 10 times that: 36000.
It turned out that hours and minutes (which were
set very far away from this bit of code), were actually strings, not
numbers.
So hours*60 converted hours to a number, and
multiplied it by 60, giving 60.
That 60 was then converted to a string, and concatenated with
minutes, which was "0", giving "600". This was then converted to a
number, and multiplied by 60, giving 36000.
Error correction in data notations
When building the Views system, we decided against error correction,
observing that when programmers work, they repeatedly compile, correct and
recompile, until they get no syntax errors, and seem to have no objection to
that process. In a similar way, in the Views system, if you displayed a
document that didn't match its style-sheet, it displayed as much as it could,
and a big red blob where it went wrong. (There were plans to do type-checking
on style sheets, so that you would even get the warning beforehand.)
With data representations too, you can fix the errors until they display
correctly; only then you send them to others. Without error
correction, all documents are correct, and you know when one isn't; with error
correction, if it looks right it gets sent on, and everyone has to fix it up
separately.
Usability
A widely overlooked aspect of the design of notations is usability. A
generally accepted definition of usability is
- an optimal reduction of the time needed to achieve a task,
- the reduction of errors while doing it, and
- the maximisation of pleasure in the process.
(Some definitions add learnability to this.)
As an example of how usability can affect notations, consider Roman
numerals. Here is the representation of 2022:
MMXXII
These are mostly fine for representing numbers, just about acceptable for
addition, but terrible for multiplication, (which was consequently a university
subject until the introduction of indo-arabic numerals), and disastrous for
division.
Indo-arabic numerals reduce the time needed for performing these operations,
reduce the errors made while doing them, and consequently are more pleasurable
to use. Nowadays even schoolchildren can do multiplication and division.
Another example is the two-letter abbreviations for state names in postal
addresses in the USA.
For example, is "NE" the code for Nevada or Nebraska? It is Nebraska, but if
NB had been used instead, there would be no need to ask. Similarly for MI:
Mississippi, Missouri, Michigan, or Minnesota? It's Michigan, but MG would have
been a better choice.
But this only solves the problem for reading. To write an abbreviation, you
would still have to look it up, or memorise it.
On the other hand, a straightforward rule like
"For states with a two word name, use the initials of those words,
otherwise use the first and fourth letter of the state name, unless there is
a repeated letter in the first four, and then use the first and the fifth"
generates a unique set of two-letter abbreviations that you don't have to
memorise, and are easy to back-translate to the original state name.
Usability in XML
An example of good usability in XML is the requirement that attribute values
should always be quoted:
<time seconds="739034589"/>
HTML for instance doesn't have this as a requirement: the quotes are
optional, but only in certain circumstances. The problem is that you have to
know and memorise the conditions under which they can be omitted. To make
matters worse, HTML processors don't tell you when you get it wrong, but try to
guess what you meant and fix it up. Needless to say this causes other errors,
and slows you down trying to find the source of the error. To make matters even
worse, CSS and Javascript, that can be embedded in HTML, have different rules
for when quotes are optional.
Another example of good usability in XML is the requirement that the closing
tag of an element be the same as the starting tag. This helps you narrow down
far faster and more directly to the problem when there is an error in the
bracketing, whilst languages that use a single generic closing bracket only
reveal the error very far away from its source, and each individual nesting has
to be checked for the source of the error.
Redesign
Despite the good design of XML, there are nevertheless places where it gets
in the way of properly representing abstractions, and the following discussion
will attempt to identify issues that could be resolved, with, however, the aim
that existing documents should remain valid, and with the same meaning.
Algebra
One of the desiderata for the Views system mentioned above was that in order
to facilitate the combining of documents, that there should be a simple algebra
of documents. For instance, if you have two documents A and B, then A+B should
also a document. Furthermore there should be a null document ∅ such that
A+∅ = ∅+A = A. We also wanted composability, so that documents could be
embedded in others.
Text files have these properties, for instance, and XML has none of them.
Characters
XML bans certain characters; from a print document perspective, this is
reasonable. From a content perspective, it is not, and means there are
documents you would like to represent, that you cannot. For instance, for a
table of keybindings, you are forced to invent an encoding for the control
characters that are disallowed, which you then have to process separately, for
instance:
<bind char="^A" name="SOH" rep="␁" funct="beginning-of-line"/>
<bind char="^B" name="STX" rep="␂" funct="back"/>
<bind char="^G" name="Bell" rep="␇" funct="cancel"/>
A solution, also used by XML 1.1, would be to allow character entities for
any character, though not the character itself:
<bind char="" name="SOH" rep="␁" funct="beginning-of-line"/>
<bind char="" name="STX" rep="␂" funct="back"/>
<bind char="" name="Bell" rep="␇" funct="cancel"/>
There might still remain the problem of � .
Attributes
What are attributes meant to represent in XML? There seems to be no
definitive answer to this question. They may be metadata about an element, or
just an impoverished form of child: they seem to be special cases of element
children, but with different properties:
- their content is unstructured,
- they are unordered,
- you may only have one of each name.
It is difficult to understand the functional reason for the unorderedness,
but the last restriction is surprising. You can have
<p>
<class>block</class>
<class>important</class>
<class>frame</class>
...
</p>
but not
<p class="block" class="important" class="frame"> ... </p>
The result is that you get languages where attributes have (hidden) internal
structure in order to overcome this restriction:
<p class="block important frame"> ... </p>
Whitespace
Whitespace is a recurring problem with XML, the main problem being
identifying whether whitespace in content is meant as content or is there for
readability purposes.
For opaque reasons, the XML specification only allows for two values of
whitespace treatment: preserve, and default. In
XHTML, it was fortunate that only preserve was needed, since CSS
provides values for how whitespace affects display. In ixml (the language) the
problem was solved by putting all content into attributes, so that the question
didn't arise.
In XForms [xforms] a value can be assigned a
whitespace property, with the following possible values:
- preserve - keep all whitespace (e.g. program code)
- remove - remove all of it (e.g. a credit card number)
- trim - remove whitespace at the beginning and end (e.g. an email
address)
- collapse - replace multiple whitespace with a single space
- normalize - trim+collapse (e.g. someone's name).
These seem like reasonable values for the xml:space attribute,
should you wish to use XML to represent abstractions, and not want to worry
about pretty printing routines adding superfluous whitespace.
Rootedness
XML has a rule that a document must have a single root element. This would
be comparable to a filestore that only allowed a single directory at the
top-level.
XPath [xpath] lets you select a group of elements, such
as
/html/body/*
which would give you all the top-level elements in an HTML document.
In XForms when you wish to deal with a document of unknown structure, you
can use
ref="/*"
to give the topmost element, whatever it's called. What this shows
is, just like filestores, XML actually already has a top-level root, namely
"/", and it doesn't really need to restrict it further.
As an example of where it would have been useful to relax this restriction
was in the construction of an XML server using REST protocol [xcontent], where every 'resource' was an XML document. The
mapping of the HTTP REST methods to XML documents was mostly obvious:
- PUT - create an XML document
- GET - retrieve an existing XML document
- DELETE - delete an existing XML document
But the mapping of the POST method was less obvious. What was needed was for
POST to append the incoming document at the end of another one. For instance,
if you had
<register>
<member>abc@cwi.nl</member>
<member>steven@w3.org</member>
<member>person@example.com</member>
</register>
then POSTing another <member> element would just add it
to the end:
<register>
<member>abc@cwi.nl</member>
<member>steven@w3.org</member>
<member>person@example.com</member>
<member>name@example.net</member>
</register>
This however is inconveniently hard. If the following were an allowable XML
document:
<member>abc@cwi.nl</member>
<member>steven@w3.org</member>
<member>person@example.com</member>
then appending a new <member> would be trivially easy,
and you could just use the XPath
ref="/*"
to get the set of top-level elements.
Similarly the empty document would then also be a valid XML document, the
combination of which would give you the simple algebra mentioned earlier.
If you still want a single-rooted document, that's fine: relaxing this
restriction wouldn't invalidate existing XML documents in any way.
Conclusion
XML was designed as "the smart document format for the future", and we are
now using it for purposes outside of those design criteria, so the need for
change shouldn't be seen as a criticism of the original design, just a
recognition that the design closely enough matches the new purposes that it can
be adapted for them. But those new purposes really do need those changes.
The advantage of the changes suggested here are that existing XML documents
remain XML documents, with the same meaning, in the new definition, while
allowing greater expressibility for the representation of abstractions.
References
[binaryxml] Anonymous, Binary XML, Wikipedia,
https://en.wikipedia.org/wiki/Binary_XML
[brooks] Frederick P. Brooks Jr., The Mythical Man
Month, 1975, 1995, Addison Wesley, ISBN 0-201-83595-9)
[Dijkstra] Edsger W. Dijkstra, Notes on Structured
Programming, ACM, https://dl.acm.org/doi/pdf/10.5555/1243380.1243381
[doctype] Tim Bray, Comment "Drop the doctype", 3007,
https://annevankesteren.nl/2007/10/xml5#comment-6280
[ftanml] Kay, Michael. “The FtanML Markup Language.”
Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6
- 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage
Series on Markup Technologies, vol. 10 (2013).
https://doi.org/10.4242/BalisageVol10.Kay01.
[ixampl] Steven Pemberton, ixample, A Pilot Implementation
of ixml, Proc. XML Prague, 2022, pp 41-50,
https://archive.xmlprague.cz/2022/files/xmlprague-2022-proceedings.pdf#page=51
[ixml] Steven Pemberton (ed.), Invisible XML
Specification, InvisibleXML.org, 2022,
https://invisiblexml.org/ixml-specification.html
[javascript] Dave Addey, Why ++[[]][+[]]+[+[]] evaluates
to “10″ in JavaScript, 2011,
https://web.archive.org/web/20160617112448/http://tmik.co.uk/?p=672
[microxml] James Clark, MicroXML, 2010,
https://blog.jclark.com/2010/12/microxml.html
[notforyou] Trevor Jim, Postel’s Law is not for
you, 2011, http://trevorjim.com/postels-law-is-not-for-you/
[postel] Anonymous, Robustness Principle, Wikipedia,
https://en.wikipedia.org/wiki/Robustness_principle
[queue] Jim Gray, A Conversation with Tim Bray, Searching for
ways to tame the world's vast stores of information. ACM Queue vol. 3, no. 1,
February 2005, Pages 20-25, http://queue.acm.org/detail.cfm?id=1046941
[robustness] Eric Allman, The Robustness Principle
Reconsidered, Communications of the ACM, August 2011, Vol. 54 No. 8, Pages
40-45, 10.1145/1978542.1978557,
https://cacm.acm.org/magazines/2011/8/114933-the-robustness-principle-reconsidered/fulltext
[views] L.G.L.T. Meertens, S. Pemberton The ergonomics of
computer interfaces. Designing a system for human use, 1992, CWI, Amsterdam,
CS-R925, https://ir.cwi.nl/pub/5346/05346D.pdf
[xcontent] Steven Pemberton, On the Design of a
Self-Referential Tutorial,
https://homepages.cwi.nl/~steven/Talks/2021/05-22-markupuk/tutorial-design.html#server
[xforms] Erik Bruchez et al. (eds), XForms
2.0, W3C, 2022,
https://www.w3.org/community/xformsusers/wiki/XForms_2.0
[xhtml] Steven Pemberton et al., XHTML™ 1.0 The
Extensible HyperText Markup Language, W3C, 2000,
https://www.w3.org/TR/xhtml1/
[xml] Tim Bray et al., Extensible Markup Language
(XML) 1.0 (Fifth Edition), W3C, 2008, https://www.w3.org/TR/xml/
[xml11] Tim Bray et al. (eds), Extensible Markup
Language (XML) 1.1, W3C, 2006, http://www.w3.org/TR/xml11
[xml5] Anne van Kesteren, XML5, 2007,
https://annevankesteren.nl/2007/10/xml5
[xpath] Norm Walsh et al. (eds), XQuery and XPath Data Model
3.1, 2017, W3C, https://www.w3.org/TR/xpath-datamodel-31/