Now consider a procedural definition of square root:
function f a:
{
x ← a
x' ← (a + 1) ÷ 2
eps ← 1.19209290e-07
while abs(x − x') > eps × x:
{
x ← x'
x' ← ((a ÷ x') + x') ÷ 2
}
return x'
}
This definition raises many questions, not least of which is What does it even do? But other questions include: Under what conditions does it work? How does it do it? What is the theory behind it? Is it correct? Can I prove it? Under what conditions may I replace it, or parts of it with something else?
In fact, even if you know the theory, it is hard to determine how it is used in this code, because the code has been optimised by unrolling the loop once, and pre-evaluating some constant expressions. The issue is that the solution is very far from the problem statement; this is one of the reasons that documentation is so important in programming. In a nutshell, the advantages of the declarative approach are that it is:
- (Much) shorter
- Easier to understand
- Independent of implementation
- Less likely to contain errors
- Easier to see it is correct
- Tractable.
Declarative Markup
One of the strengths of the original web was its declarative markup:
although there were some mistakes, the markup largely specified the role of the
elements, rather than how they should appear. For instance, an h1
was a top-level heading with no a priori requirement that it be
displayed in any particular way, larger or in bold. It just stated its
purpose.
Mistakes included hr (horizontal rule), and elements like
b and i for bold and italic, which
specify a visual property rather than a purpose, but most of the structure was
purely declarative.
This has a number of advantages, including machine and modality independence: you can just as easily 'display' such a document with a voice-reader as on a screen, without having to use heuristics to guess what is intended.
The poster-child of HTML declarative markup is the <a> element:
<a href="talk.html" title="…" target="…" class="…">My Talk</a>
This single line compactly encapsulates a lot of behaviour including
- what the link looks like
- what to do when you hover over the link
- activating the link in several ways
- what to do with the result
- hooks for presentation changes.
Doing this procedurally in program code would be a lot of work.
Style Sheets
Another advantage of declarative markup is that since display properties are not baked in to the language, you can use style sheets to control the display properties of a document, without altering the document itself.
In fact one of the first activities of the newly-created W3C was to add
style-sheets as quickly as possible to undo the damage being done by the
browser manufacturers, who were unilaterally adding visually-oriented elements
to HTML, such as font, and blink.
The result, CSS, is another example of a successful declarative approach [CSS].
When W3C started the CSS activity, Netscape, at the time the leading browser, declined to join, saying that they had a better solution, JSSS, based on Javascript – in other words a procedural rather than declarative approach. Instead of the declarative CSS
h1 { font-size: 20pt }
you would use script to say
document.tags.H1.fontSize = "20pt";
The entry on Wikipedia remarks:
"JSSS lacked the various CSS selector features, supporting only simple tag name, class and id selectors. On the other hand, since it is written using a complete programming language, stylesheets can include highly complex dynamic calculations and conditional processing." [JSSS]
Implementers as Designers
Implementers tend in general not to be great designers, because of their tendency to focus on the implementation needs rather than the user needs. For example, the original HTML surprisingly did not have facilities for embedding images into documents, so they were added by the implementers of the first really successful browser, Mosaic.
Unfortunately, they didn't do a great job. They added a single element
<img src="…"> to embed an image at that location in the
code. This has two regrettable, related, disadvantages: firstly, there is no
failure fallback, and secondly there is no alternative for non-visual
environments.
A better design would have allowed the element to have content to be used in fallback cases. For instance
<img src="cat.png">
<img src="cat.jpg">
A <em>cat</em>, sitting on a mat.
</img>
</img>
If the outer img should fail for whatever reason (the resource
unavailable, the browser not supporting png images, or it being a
non-visual browser), the nested img would be tried, and if that failed, the
text would be used. The advantage of such a design to visually impaired users
of the web should be obvious. When png images were introduced on
the web, their usage was held back for a long time because of the lack of such
a mechanism: authors had to wait until a critical mass of browsers were
available that could display the new image type before they could start using
them, creating the conditions for a potential vicious circle of them not being
used because there were no implementations, and not being implemented because
there were no users.
We have already mentioned the unfortunate blink and
font elements that were introduced by the implementers, and we
should not let that excrescence the frameset, with its security
and usability problems, go unmentioned either.
HTML 4
One of the early tasks of the nascent W3C was to try and undo the damage being inflicted on the web by the implementors. By then there were two warring browsers both adding new things, often incompatible, and without consulting the community. The W3C result was HTML4, a compromise between the different browsers, but with a clear development path [HTML4].
Examples of compromises that had to be made are HTML events which have have
both a capture and bubble phase, since the two main browsers did it
differently, and that the meta element not having content, but a
content attribute instead, because one of the browsers incorrectly
displayed content in the head.
HTML4 came in three versions:
- Strict, indicating the future direction, and disallowing many of the inappropriate elements;
- Transitional, in which the deprecated elements were allowed;
- Frameset, where frame elements were allowed.
HTML4 also properly used SGML, so that HTML documents could be read and produced by existing SGML processors. However, it was observed in that SGML was overly complex for the task, and an activity was started to define a simpler version of SGML, a subset, which became XML [XML].
XML
XML had a big advantage as markup language, namely that it would be possible to create documents that combined markup languages from different domains. This meant that domain experts could design (sub-)languages for their domain, that with proper design would be combinable with other markup languages. Examples of these domains included graphics (SVG), Mathematics (MathML), Multimedia (SMIL), and Forms (XForms), although there were other domains including semantics, and interaction events.
The advantages of such modularity should be obvious to anyone who has programmed: they allow you to specify a thin interface between the modules, and then design the modules independently. It also implied the need for an XML version of HTML, so that it could be part of this combinatorial activity, which became XHTML [XHTML1].
XHTML
The first version of XHTML was produced surprisingly quickly. There was wide-scale agreement on a need, and there were few decisions to be made, given that it was just to be a different serialization of the same structures from HTML4. There were similarly three versions as with HTML4, but with a clear indication that only strict would be further developed.
The fact that using XML allowed the mixing of namespaces in a single document was widely misunderstood, and there were complaints that XHTML added no elements, but it in fact added enormous amounts of functionality.
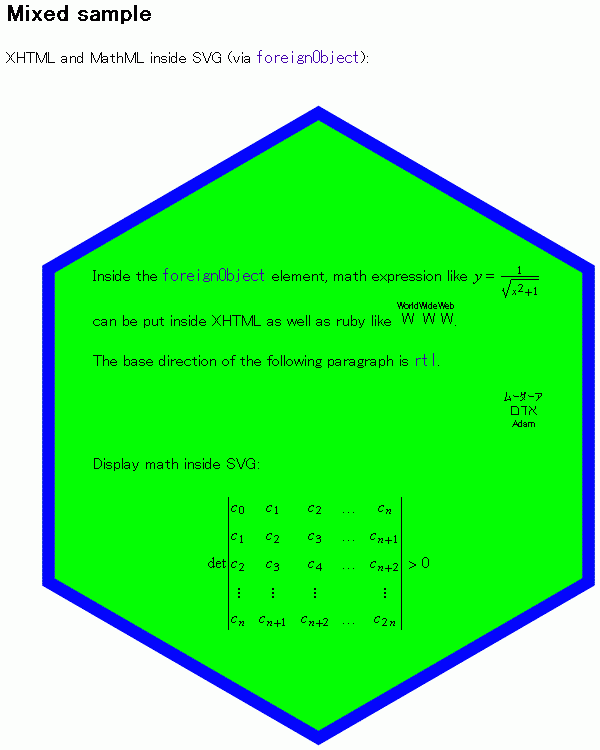 For
instance, the image is an example from 2002 of a single document (that ran in
browsers already) combining XHTML, SVG and MathML [XMS].
For
instance, the image is an example from 2002 of a single document (that ran in
browsers already) combining XHTML, SVG and MathML [XMS].
Also at this time there came a demand for variants of XHTML to serve particular needs. Notable examples are XHTML Basic [Basic], a smaller version for small devices such as mobile phones, and XHTML Print [Print] for use with printers specifically for devices that were unable to load device drivers for printers.
To avoid problems of divergence, a modularisation mechanism for XHTML was devised [M12N], with corresponding modules, so that to define a new variant of XHTML, you only needed to specify which modules you needed, and you had your language, with guaranteed consistency across the variants, and if an error was later corrected in a module, all the variants that used that module would automatically be updated.
Consequently, a modularised version of XHTML was created, XHTML 1.1 [XHTML11], but only in a strict version, with only slight differences with XHTML 1.0 strict. This approach meant that when a version of XHTML was required with RDFa added, it was a simple matter of creating a module for RDFa, and publishing.
XHTML2
After XHTML 1.1, a new effort was started to make XHTML more consistent,
clear up some historical glitches (such as the empty meta element,
and no fall-back for images), and address new required functionality, such as
better metadata and forms. This was to be XHTML2 [XHTML2].
Unfortunately, before it was ready, the group was closed by W3C management, despite the membership having voted for it to be retained.
The modules that the group were working on were moved to other groups to continue development, such as ARIA [ARIA], RDFa [RDFa], and XForms [XForms].
HTML5: A New Web, by Programmers, for Programmers
At that point HTML was taken on a completely different path, driven entirely by implementers, with little reference to users, predicated on procedural methods, disregarding the fundamental design principles of the web, and eschewing modularity, essentially turning HTML into a monolithic programming environment, namely HTML5 [HTML5].
Design
Much of HTML5 is not designed in the normal sense of the word, although a design principles document was published[Design].
One of the design principles quoted was "Pave the Cowpaths", "Cowpaths" being a rather derogatory term for what in design circles is normally referred to as "Desire Paths". This is a design-principle used in architecture: when you build a campus or estate, don't pave the paths, but wait and see where people actually walk, so you can see where they need paths.
But the design document got it wrong:
"When a practice is already widespread among authors, consider adopting it rather than forbidding it or inventing something new. Authors already use the
<br/>syntax as opposed to<br>in HTML and there is no harm done by allowing that to be used."
This however is not "Paving the cowpaths", which would be more like noticing that huge numbers of sites have a navigation drop-down, and supporting that natively.
But even "Paving the cowpaths" is not necessarily a good design practice in itself. Cows are not designers. Cowpaths are data. If you pave cowpaths, you are setting in stone the behaviours caused by the design decisions of the past. Cowpaths tell you where the cows want to go, not how they want to get there. If they have to take a path round a swamp to get to the meadow, then maybe it would be a better idea to drain the swamp, or build a bridge over it, rather than paving the path they take round it.
Paving cowpaths is a bad design principle in the way that it was applied. It can be a good design principle, but they apparently misunderstood it.
Faulty Cowpath-based Design
As an example, the HTML5 group spidered millions of pages, and then on the basis of that data decided what should be excluded from HTML5. This is exactly the opposite to "paving the cowpaths": it is putting fences across cowpaths that are used by fewer cows than some other paths, and even goes against their own proclaimed design principles.
As an example, take the @rev attribute.
<link rel="next" href="chap2.html"/> <link rev="prev" href="chap2.html"/>
@rel and @rev are complementary attributes, they
are a pair, like +/-, up/down, left/right.
The HTML5 group decided that not enough people were using @rev,
and so removed it. This breaks backwards compatibility, and puts a fence before
those who do need to use it. This is doubly bad in the light of
another of their design principles: "Support Existing Content".
Irritated by Colon Disease
For years, the wider community on the web had agreed to use a colon (:) to
separate a name from the identification of the vocabulary it comes from. A
colon was a legal name character, and so it was chosen to be backwards
compatible, but in some environments could be interpreted in a new way. For
instance, xml:lang was an attribute that could be used on any
XML-based markup language to identify the (natural) language being used in the
contained content.
But for some reason a new separator was developed for HTML5: the hyphen. For example:
<div role="searchbox"
aria-labelledby="label"
aria-placeholder="MM-DD-YYYY">03-14-1879</div>
apparently re-inventing namespaces.
This also went against another of their design principles: Do not Reinvent the Wheel.
Reinventing the Wheel
Despite not reinventing things being one of the design principles, nevertheless that precept wasn't followed. As has been noted:
"The amount of “not invented here” mentality that [pervades] the modern HTML5 spec is odious. Accessibility in HTML5 isn’t being decided by experts. Process, when challenged through W3C guidelines, is defended as being “not like the old ways”, in essence slapping the W3C in the face. Ian’s made it clear he won’t play by the rules. When well-meaning experts carefully announce their opposing positions and desire for some form of closing the gaps, Ian and the inner circle constantly express how they don’t understand." [CSSquirrel]
"Not invented here" (NIH) syndrome is often warned against in design books. For instance:
"Four social dynamics appear to underlie NIH:
- Belief that internal capabilities are superior to external ones.
- Fear of of losing control.
- Desire for credit and status.
- Significant emotional and financial investment in internal initiatives." [Lidwell]
Many groups had already solved problems that HTML5 should have used, but HTML5 decided to reinvent, usually with worse results, since they were for areas that they were not experts in.
Not Invented Here: Microdata
To take an example, consider RDFa. This came as the result of the question: How should you represent general metadata in HTML?
In 2003 a cross-working-group task force was created of interested parties to address the problem. This produced in 2004 a first working draft of RDFa, which in 2008 finally became the RDFa Recommendation [RDFa], representing more than 5 years of work, consensus, and agreement on how metadata should be represented in HTML and related technologies.
Then a year later in 2009 the HTML5 group created Microdata out of the blue [Microdata], with no warning, and no discussion or consultation, clearly copied from RDFa (it used the same attributes), but different, and less capable. This created a lot of confusion in the web community, muddying the Semantic web area. In 2013 Microdata was abandoned, by which time the whole semantic area had been damaged. Microdata has since been periodically revived.
Forward compatibility: Empty elements
One major improvement that XML introduced was a new notation for empty
elements: <br/>. This one simple change meant that you could
parse a document without a DTD or Schema; you could parse any document without
knowledge of the elements involved, which made the parser forward-compatible.
Incomprehensibly, HTML5 dropped the requirement for this notation (probably
because of Irritated by Colon Disease), meaning that a processor now has to
know which elements are empty, and making it impossible to add new empty
elements to HTML (since it would break compatibility).