Internet: The Next 35 Years
Steven Pemberton, CWI, Amsterdam

 This year marks the 35th anniversary of the open internet in Europe
This year marks the 35th anniversary of the open internet in Europe
It started in November 1988 in this very building, at the breathtaking speed of 64kb/s connecting all of Europe (=me and a handful of other researchers here) with all of North America.
Since then the speed here has nearly doubled every year, so that the Science Park has the world's fastest internet node at nearly 12 Tb/s.
12 Teraseconds is approaching half a million years. It is a very big number, and every second that many bits pass through here.
Cast your mind back to 1988 (if you are old-enough).
Let me tell you what we didn't have:

So what did you do?
 Trains: timetable book
Trains: timetable bookSo we have a lot to be grateful to the internet for.
But is this it? Have we reached peak internet, or is there more to come?

Whenever a new technology is introduced, it imitates the old.
Early cars looked like "horseless carriages" because that is exactly what they were.
It took a long time for cars to evolve into what we now know.
 Before the introduction of printing in 1450, all books were
literally made by hand (Manu script: hand written). This was a long
slow process, and very expensive.
Before the introduction of printing in 1450, all books were
literally made by hand (Manu script: hand written). This was a long
slow process, and very expensive.
Until the introduction of printing, books were rare, and very, very expensive, maybe something like the price of a small farm.
Only very rich people, and rich institutions, owned books.
In 1424 The University of Cambridge had one of the largest libraries in Europe: 122 books.

Gutenberg combined known technologies: ink, paper, wine presses, and added movable type.

For the first 50 years, books looked just like manuscripts.
Why?
That was what was expected of a book at the time.
It was where the money was.
They didn't know any different!
The introduction of book printing had several effects:
Before, producing a single copy of a book took several years. By 1500:
And bear in mind, you didn't just "set up a print shop". You had to:
It was a real revolution.
After about 50 years, readable fonts, and the features we now expect from a book emerged, so that books became what we now think of as books.
Up until the introduction of printing, all information had been in the hands of the church (even universities were primarily religious institutions run by the church).
After books arrived, the church and state instituted censorship, to try and control information. Writers were killed or imprisoned for publishing things that weren't approved of. For instance:
Consequently many thinkers relocated to get out of the reach of the church.
"The twin occurrences – that the city became a hub for scientists, and that it became the centre of publishing – fed one another, resulting in the astounding fact that, over the course of the 17th century, approximately one-third of all books published in the entire world were produced in Amsterdam" - Russell Shorto
Printing enabled the rise of Protestantism, and the Enlightenment is ascribed to the availability of books.
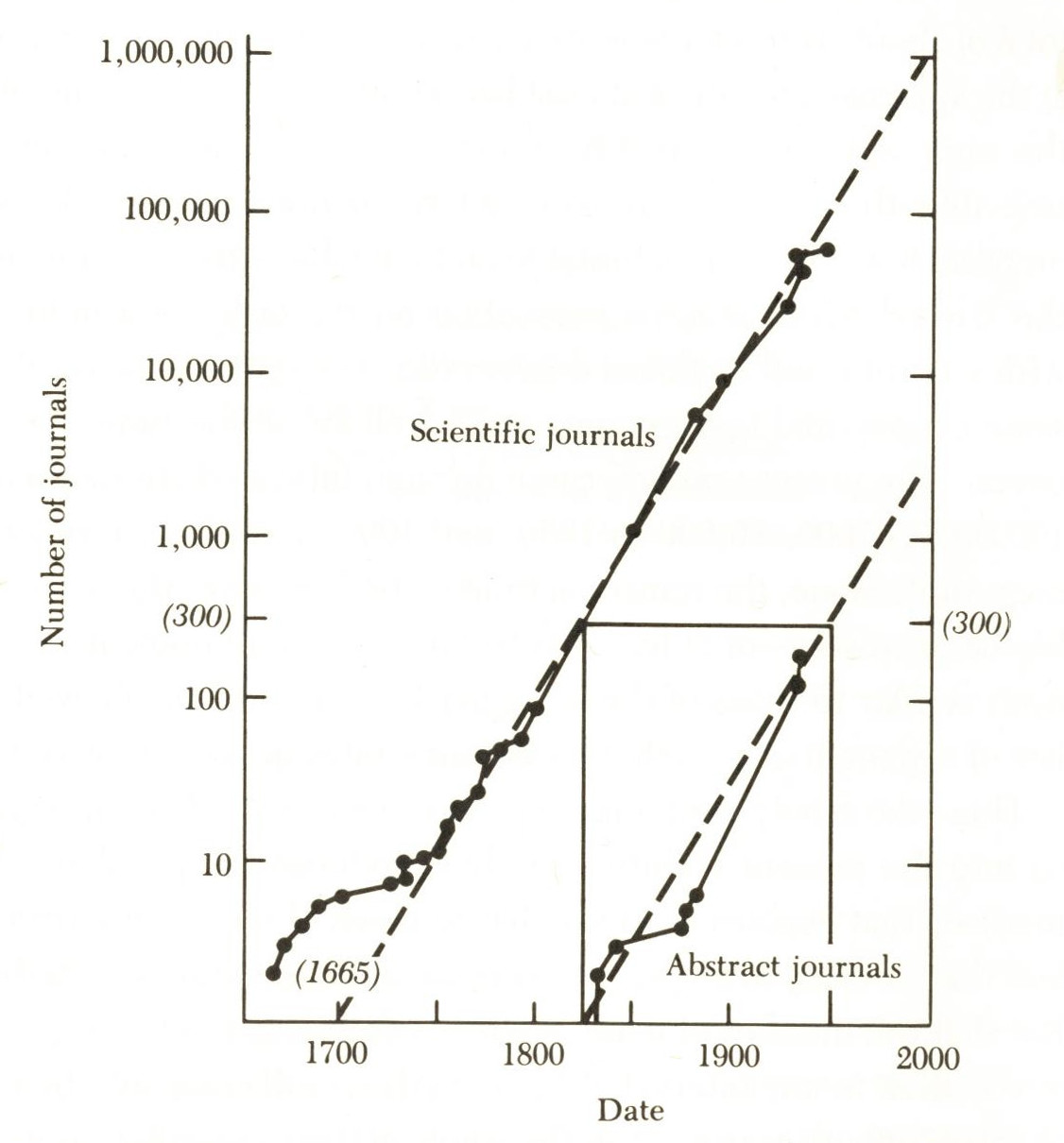 1665:
first two scientific journals French Journal des Sçavans and the
British Philosophical Transactions
1665:
first two scientific journals French Journal des Sçavans and the
British Philosophical Transactions
From then on the number of scientific journals doubled every 15 years, right into the 20th century.
Even as late as the 1970's if you had said "there has to come a new way of distributing information to support this growth", they would have thought you crazy, more likely expecting the growth to end.
(Source: Little Science, Big Science, Derek J. De Solla Price)
The coming of the internet in Europe in 1988 enabled the Web.
Tim Berners-Lee (and Robert Caillau) created the Web at CERN: first server 1991.
They brought together existing technologies (Hypertext, the internet, MIME types) and created a cohesive whole.
The Web is now replacing books and many other things: Telephone directories, yellow pages, encyclopaedias, train timetables, other reference works are already gone. Others will follow.
Books (as an artefact) will become a niche market. All information will eventually be internet-based.
In many ways, the development of the web has echoed that of the book. It has:
Books created turmoil in society by creating new ways for information to be distributed, which disturbed the existing power structures.
We are now living through a similar information turmoil, since society has not yet worked out how to deal with these new sources of information.
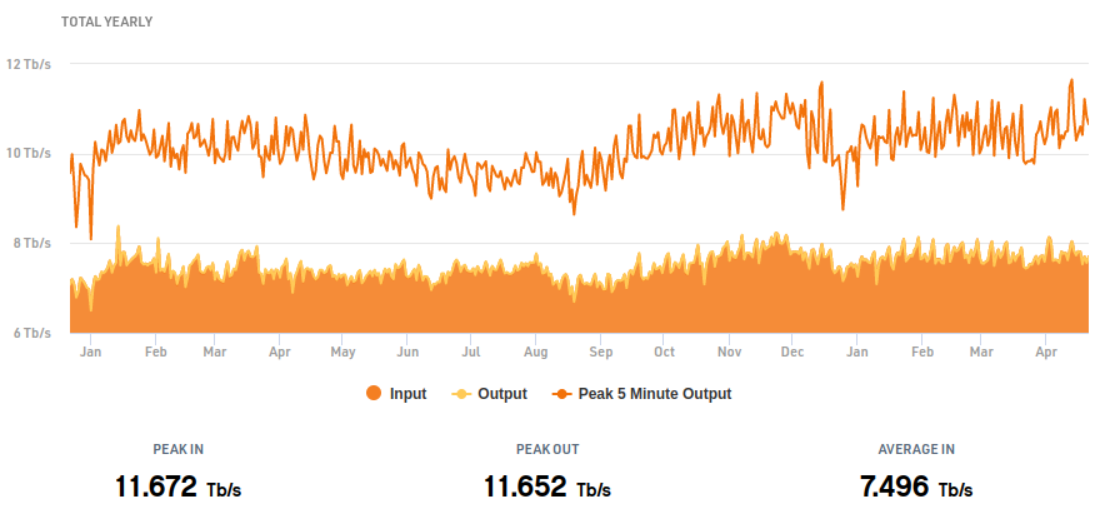 And weirdly, just as Amsterdam
produced the largest number of books in the 17th century, it has the fastest
internet switch in the world, currently peaking at nearly 12Tb/s.
And weirdly, just as Amsterdam
produced the largest number of books in the 17th century, it has the fastest
internet switch in the world, currently peaking at nearly 12Tb/s.
The web is still imitating the old.
It is still very much presentation oriented, and not information oriented.
As an example, I recently had to:
 Other examples are
ticketing, contracts, and receipts.
Other examples are
ticketing, contracts, and receipts.
These are all typically PDFs, with no machine processable elements. They are a picture of a paper version of the thing.
The only thing that has happened is that the paper has been digitised away, and is sent to you electronically. Otherwise it is the same as it ever was.
Information can be used in two ways (at the same time): to communicate to people, and to communicate between machines.
For instance there is a service, tripit, to which you send tickets, hotel bookings, and so on. It assembles them and creates an itinary for you automatically. Really handy: everything in one place.
But it has to know what the information is.
It has to try and work out what is in these things, in order to do something useful with it. It often gets it wrong.
This is a ticket recently sent to me, as a PDF

This is the essence of that PDF ticket
document: ticket type: train supplier: Eurostar reference: PCX4GZ passenger: Steven Pemberton train: 9114 date: 2023-07-20T08:16:00+02:00 from: Amsterdam CS to: St Pancras International arrive: 2023-07-20T13:51:00+01:00 class: SP coach: 3 seat: 21
Making this pretty for a human reader is a trivial task, and the technology already exists to do that.
Automatically getting the information out of a PDF is not trivial. It is hard, and it is often got wrong.
Providing papers for a conference is a often a choice between using latex (which is a pre-web technology) or Word!
There's a page limit!
There's a styleguide including how references should be visually displayed!
IT'S ALL ABOUT PAPER!
Conference papers are paragraphs, headings, diagrams, references.
The author shouldn't have to care about how the conference wants it formatted. The information is there, let them format it as they will.
I write all my papers in (a rational version of) XHTML, supposing it to be the current format that has the best chance of longevity. Using HTML doesn't commit me to any particular presentation: style sheets let you change the look at will.
But I have to convert my HTML to Word in order to submit.
Which they then convert back to HTML and PDF!
(See The Tyranny of Formatting (from 2013!) for further details.)
So eventually books went from pretending to be manuscripts to being proper books.
When can we expect the Web to stop pretending to be the old things, and start being what it really ought to be?
Why did it take 50 years for books to become their real selves?
This question has long troubled me.
So eventually books went from pretending to be manuscripts to being proper books.
When can we expect the Web to stop pretending to be the old things, and start being what it really ought to be?
Why did it take 50 years for books to become their real selves?
This question has long troubled me.
My reluctant conclusion: the old generation of users and producers have to die, before the new generation who had never known the old way can start asking why things are done in such a weird way and start fixing them.
The requirements of the non-paper internet include
How do you prove who you are?
Your real identity is just you: my local grocer shop was fine if I forgot my money, and said I'd come back later to pay.
Your phone may recognise your face, or your fingerprints.
Google Assistant can recognise you by your voice.
But in other cases, you have to prove your identity in some way: Passport, driving license, ID card.
And how do you prove who you are when getting your first passport?
You use your birth certificate.
This is called transitivity, where a property (in this case your identity) passes down the line.
How do we prove our identity on the internet?
Mostly by passwords...
You log in to your computer, by whatever means. It therefore knows it is you. But then you have to log in to a website to identify yourself, and then again, and again.
What do we use to get a new username/password?
Our email address, the digital equivalent of our birth certificate.
An email address is unique, so can be used as a proxy for your identity.
(It doesn't matter if you have several email addresses: they all refer back to the same person.)
Your identity should really be passed transitively down the line. You shouldn't need to repeatedly log in.
It works by everyone having two keys, a private one and a public one. A message locked with one can only be unlocked with the other.
If I lock a message with my private key, everyone can read it, but they know it is really from me.
If I lock a message with your public key, only you can read it.
When I register with a site, I give it my public key.
Then when I log in, my browser sends the site a message locked with my private key: the site knows it is from me.
The message can also be locked with the site's public key, so that I know that it is going to the right site.
The good news: Passkeys are now being implemented in browsers. With any luck passwords on the web will be a thing we will laugh with our grandchildren about.
The internet was originally built with no mechanisms for trust and identity built in.
It was after all a network for computer scientists and computer departments to communicate with each other.
Anonymity was originally seen as a good thing...
It turns out that it is good for a small number of things (whistleblowing, avoiding abusers), but is bad for a lot more.
Russia used hundreds of fake accounts to tweet about Brexit, data shows
Royal Mail ransomware attackers threaten to publish stolen data
Some years back, researchers at the CWI devised a form of digital money that was anonymous, unless you misused it, such as trying to spend it twice.
So you could spend the money anonymously, but if you misused it, they could trace who you were.
Ideally we need a form of anonymity that allows for whistleblowers, or people hiding from abusers, but lets you track down money launderers or abusers.
The web is 32 years old this year.
On 6 August 1991, Tim Berners-Lee posted a short summary of the World Wide Web project to an internet newsgroup inviting collaborators; the first web servers had been made publicly available a few months earlier.
The original web was designed as a distributed system.
Computers connected to each other, with no central authority.
A read/write web, where you could both read and publish.
Unfortunately, Mosaic, the first really successful browser, left out the writing part.
Which mean that another way had to be found to publish on the web, which resulted in a lot of centralisation.
And so emerged a generation of websites that allowed you to post stuff to them, and that got their value from users adding stuff.
Sites like Facebook, Twitter, Photo websites, Family tree websites, LinkedIn, github, bandcamp, dating sites, or any of a thousand more.
Where we had hoped for a distributed system, we ended up with lots of centralisation.
You have a (small) home server.
Everything you want to share, you put there.
You control who can access it.
You can then have a distributed Facebook, where only your friends can see your stuff, and you theirs.
You could allow different family tree sites access your tree, without having to repeatedly enter it.
You could put something online for sale, and several sites could add it.
You could put an event online that several services collect.
The data is yours, you control who sees it; you don't have to repeat the work; if the sites die, you've still got your data.
In real life you might be able to prove you own something by showing a receipt.
I think I could prove I own my computer. I'm not sure I could prove I own any of my bikes.
For larger and/or more expensive objects we have papers, or documents, or the ownership is registered centrally.
To buy and sell such things we use third parties who are usually legally registered to do such things.
Often we end up with some sort of certificate that declares your ownership, with a reference back to the third party, so that the claim can be verified if needed.
The legal system is geared to deciding claims.
As more and more things become digitised, new ways are needed to identify things.
This is one of the central issues at the heart of the future Web: how do we identify things, and how do we specify what properties they have, so that conclusions can be drawn automatically without anyone having to read or interpret text.
This would allow you to describe all human knowledge in a machine-readable way.
But it would also allow you to create, for instance, digital contracts.
Decentralisation is the only safe option for any future version of the web.
We are still in the "looks like a manuscript" phase of the internet. We are still imitating the old ways.
We will need to resolve the identity:anonymity conflict
Machine-readable semantics will be at the root of future improvements
The legal system will have to adapt to new ways of specifying contracts.
The real web can't emerge until the paper generation is dead.