Abstract
ixml is a declarative language for transforming data representations, which
became a stable specification in 2022.
The original pilot implementation of ixml, ixampl, was written in
the very-high-level programming language, ABC, the forerunner of Python. The
implementation is split into two parts: a bootstrap parser, that reads ixml
grammars and transforms them into the structure needed for part 2, which is a
generic parser that reads any document and transforms it into XML. Part 1 is
about 700 lines of code, part two about 780.
One of the many possible uses of ixml is to transform any data
representation into XML so that it can be used as input to other applications
in the XML toolchain. One of those applications is XForms, a Turing-complete
declarative programming language that uses XML as its data format.
To illustrate this, a code browser was made for the ixampl implementation,
in a nicely self-referential way, using a 30 line ixml grammar to transform the
ABC code into an XML representation, and use this as input to an XForms
application of around 90 lines, plus some CSS, that enables you to browse and
search in the ixampl code. Although the browser is for ABC code, with the
exception of the ixml grammar, there is little that is specific to ABC, meaning
that with a different bit of ixml, it would be easy to adapt it for another
language. So combining three declarative technologies, we were able to create a
useful, functional, adaptable, code browser in under 150 lines of code.
Keywords: ixml, code browser, declarative languages,
declarative programming, ABC, XForms, UTF-8
Introduction: ixml
ixml is a declarative language
for transforming textual documents with implied structure into documents where
the structure has been made explicit [ixml]. It has had a
stable specification since 2022 [spec], and there is a
"Community group" at W3C for its support and further development [cg]. There are at the time of writing at least four running
implementations, and others in development.
To give a taste of how ixml works, for a very simple example, given the
input
3 November 2023
and the ixml description
date: day, -" ", month, -" ", year.
day: d, d?.
month: "January"; "February"; "March"; "April"; "May"; "June";
"July"; "August"; "September"; "October"; "November"; "December".
year: d, d, d, d.
-d: ["0"-"9"].
this would produce as output:
<date>
<day>3</day>
<month>November</month>
<year>2023</year>
</date>
The Transformation Process
The ixml process for transforming a textual document into a structured
document looks like figure 1. The ixml processor takes a textual document, and
a structured description of the format of that document, and converts the input
document into a structured output.
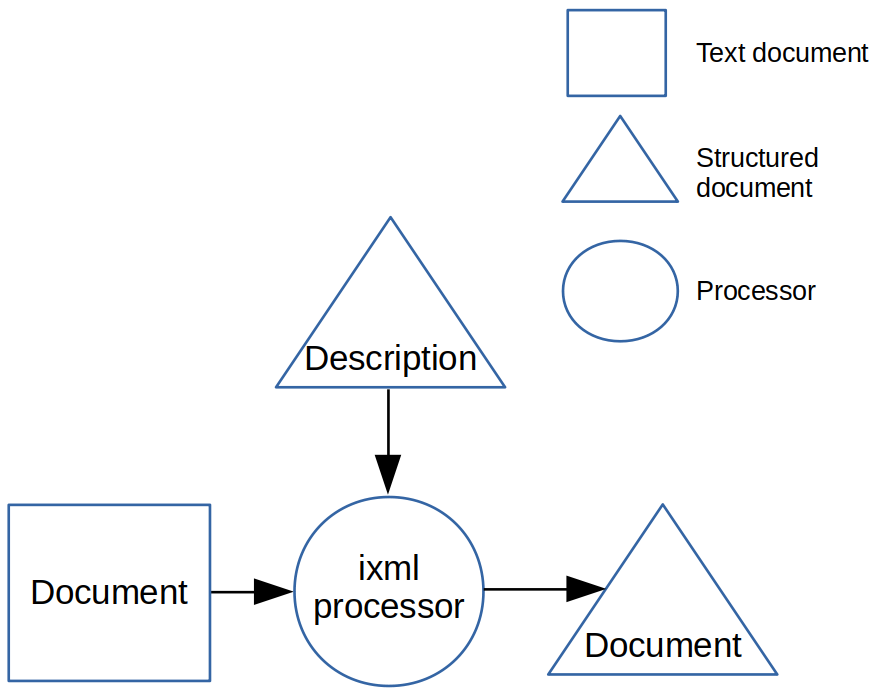 Figure 1.
Converting a document into a structured version.
Figure 1.
Converting a document into a structured version.
Although the description of the format is represented here as a structured
document, it starts off as a textual document that has to be transformed
itself, as shown in figure 2. Here the textual description is converted in
exactly the same way, using a structured description of the ixml format.
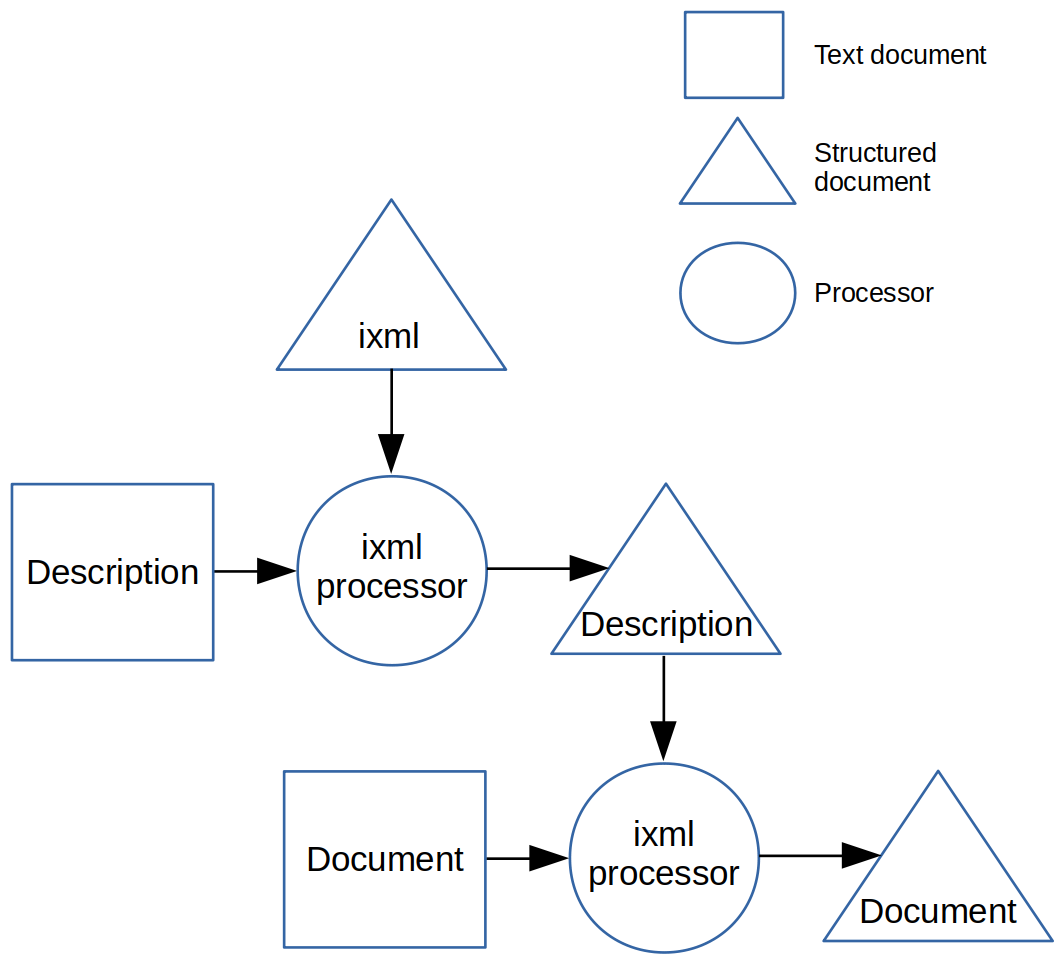 Figure 2.
Producing the structured version of the format description.
Figure 2.
Producing the structured version of the format description.
In this diagram ixml is also represented as a structured document, but it
too starts off as a textual document, that is transformed in a bootstrap phase,
as shown in figure 3.
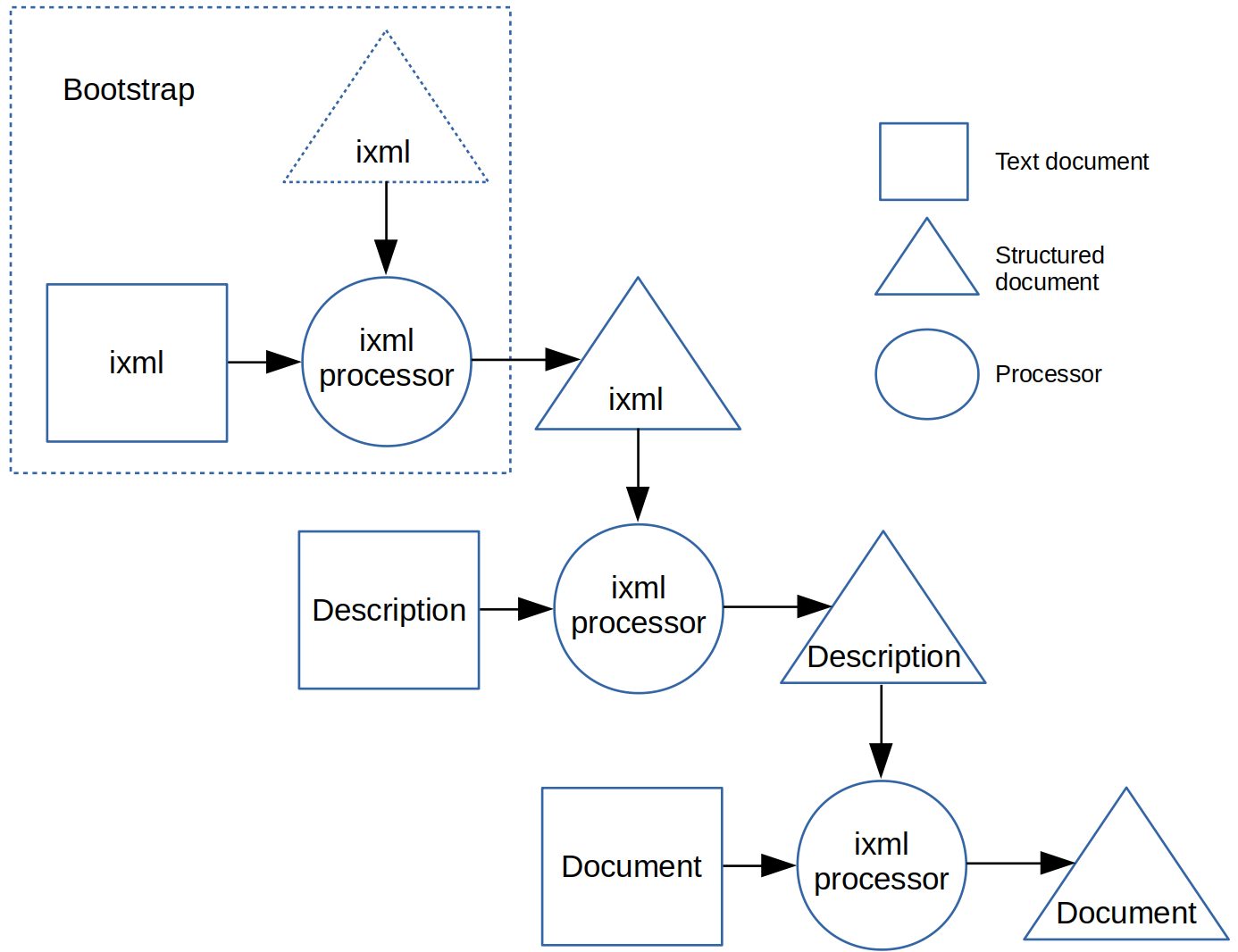 Figure 3.
Bootstrapping the ixml description.
Figure 3.
Bootstrapping the ixml description.
ixampl: The Pilot Implementation
Although figure 3 shows the idealised situation, in fact the pilot
implementation [ixampl] has the description of ixml
hardwired into stage one, as shown in figure 4.
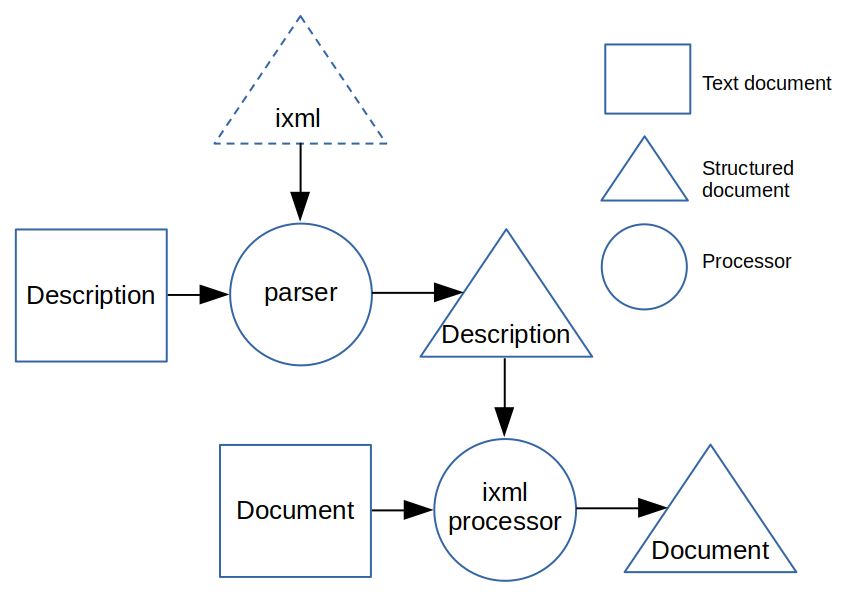 Figure 4. The structure of the pilot implementation.
Figure 4. The structure of the pilot implementation.
So the implementation consists of two parts:
- Part 1, for reading and parsing the ixml description, and serialising
into the format expected by part two.
- Part 2, for using that description to parse the text document, and
serialise it as XML
ABC: The Implementation language
The implementation is written in the very-high-level interactive language
ABC [abc]. It has only 5 data types: Numbers, Strings,
Compounds, Bags, Maps. Bags and maps are kept sorted. All data (even numbers)
is unbounded, and dynamic.
The language is statically typed without declarations, and formed the basis
of Python [Py].
Dealing with Unicode
The character set used by ixml is Unicode [unicode].
One problem with ABC is that it predates the development of Unicode, and only
has 8 bit characters, which is not enough for Unicode. Furthermore ABC
characters are atomic, and so initially it was thought that it wouldn't be able
to process Unicode.
Character sets are just a mapping from numbers (the 'code-point') to
character representations (the 'glyph'). Since historically memory was very
expensive, many early computers had only a 6-bit character set, allowing only
64 characters. This meant for instance, only a single case of letters. ASCII
was a 7-bit character set giving 128 characters, including two cases of (Latin)
letters. Later Latin1 [latin1] used the spare
8th bit to add another 128 characters.
Unicode was initially designed to represent all the world's characters, and
it was thought that 16 bits would be enough: "In a properly engineered
design, 16 bits per character are more than sufficient for this purpose"
[u16].
But as it turned out it wasn't, and so it was expanded to, currently, 21
bits (10FFFF being the current highest character), giving the pleasantly
palindromic number of 1,114,111 characters.
UTF-8
Before Unicode, all characters fitted into one 8-bit byte, but 21 bits meant
that there had to be a multi-byte encoding. Several such encodings
exist. UTF-8 [utf8a, utf8b] was born
because of a problem with Unix-like systems: files had no metadata for
character encodings, and thus all files used the same encoding. UTF-8 was
invented as a variable-length encoding of Unicode, with ASCII as a subset: so
at a stroke all existing Unix ASCII files became Unicode-compliant.
Traditionally UTF-8 is described as a bit-oriented encoding: a character
consists of one to four bytes, where the first few bits of each byte tell you
the role of that byte within the character.
Each byte either starts a character, or is a continuation byte. "The first
few bits" means: there are a number of 1 bits followed by a zero stop bit; all
remaining bits are data. Counting the number of leading 1 bits tells you the
role of that byte:
- 0: this is a single-byte ASCII character
- 1: this is a continuation byte
- 2: start of 2-bytes, 1 continuation byte follows
- 3: start of 3-bytes, 2 continuation bytes follow
- 4: start of 4-bytes, 3 continuation bytes follow.
You then concatenate the data bits of the n bytes to give you the
code-point.
This encoding has some advantages and some disadvantages: an advantage is
that it is context-free, so you can always find the start of the next character
from wherever you are. A disadvantage is that you have to count to know how
many characters are in a file, and you can't index directly into a file at a
specific character position. (It is also worth mentioning that it additionally
creates a confusion between programming languages about what the length of a
string is: is it the number of bytes, the number of Unicode characters, or,
since some Unicode characters combine to create a single abstract glyph, is it
the number of glyphs the string represents? Before Unicode these numbers were
roughtly the same.)
The problem for ABC was that the language predates Unicode, and has 8 bit
characters, but they are atomic: you can't look at the bits. This led to the
conclusion that Unicode processing was not possible. And then came an
aha moment: there are only 256 bytes, and each has only one role.
0-127: ASCII
128-191: continuation character
192-223: start a 2 byte character
224-239: start a 3 byte character
240-247: start a 4 byte character
248-255: illegal (5 or more leading 1 bits)
(The illegal characters are available for a future expansion, allowing up to
a 42 bit representation of characters, or in other words, 4,398,046,511,104
characters maximum, which should be enough for anyone!)
Put another way, you could express UTF-8 in ixml:
input: u*.
u: u1; u2; u3; u4.
u1: b1. {ASCII, 7 bits}
u2: b2, b0. {#80-#7FF, 11 bits}
u3: b3, b0, b0. {#800-#FFFF, 16 bits}
u4: b4, b0, b0, b0. {#10000-#10FFFF, 21 bits}
b1: [#0-#7F]. {7 bits of data}
b0: [#80-#BF]. {adds 6 bits of data}
b2: [#C0-#DF]. {adds 5 bits of data}
b3: [#E0-#EF]. {adds 4 bits of data}
b4: [#F0-#F7]. {adds 3 bits of data}
{Continuation characters never start a character}
{#F8-#FF are illegal everywhere}
So the solution for ABC was to record for each of the 256 bytes its role,
how many bytes it starts: 1 for ASCII, 2 for the start of a 2 byte character,
etc, 0 for continuation and illegal characters.
Once that is done, you can use the | string operator of ABC,
which delivers the leading substring of a string:
"dishonest"|4 = "dish"
So string|1 is the first byte, and string|0 is an
empty string. And string|start[string|1] is the next Unicode
character! If it's an empty string, there was an encoding error.
All without bit-twiddling!
The Use of ixml
The principle aim of ixml is to allow the injection of other things than XML
into the XML pipeline. For instance, bibliographies in the past have
traditionally been plain text, but are much more useful as a structured
document, allowing different fields to be more easily identified.
As an example, bibliographic entries such as
[spec] Steven Pemberton (ed.), Invisible XML Specification,
invisiblexml.org, 2022,
https://invisiblexml.org/ixmlspecification.html
can be processed by an ixml grammar whose top-level rules are along the
lines of
bibliography: biblioentry+.
biblioentry: abbrev, (author; editor), -", ",
title, -", ", publisher, -", ",
pubdate, -",",
(artpagenums, -", ")?,
(bibliomisc; biblioid)**-", ", -#a.
abbrev: -"[", [L]+, -"]", " "*.
...
to produce a structured entry like this:
<biblioentry>
<abbrev>spec</abbrev>
<editor>
<personname>
<firstname>Steven</firstname>
<surname>Pemberton</surname>
</personname>
</editor>
<title>Invisible XML Specification</title>
<publisher>invisiblexml.org</publisher>
<pubdate>2022</pubdate>
<bibliomisc>
<link xlink-href='https://invisiblexml.org/ixml-specification.html'/>
</bibliomisc>
</biblioentry>
What this means is that just as UTF-8 made all ASCII files Unicode, so ixml
makes all parsable text XML processable. Once you have your structured output,
this can then be injected into the XML tool pipeline.
As an example, XForms is a Turing-complete declarative programming language
that uses XML as its data model. What this meant was that we could make a
nicely self-referential application: use ixml to make the ixml implementation
source code available as XML to an XForms application for browsing that
code.
So the steps were simple: convert the source code to XML, and then input
that XML into a suitable XForm for browsing.
Source Code
ABC, like Python, uses indentation for grouping, and so is not context-free.
However, it can still be parsed with ixml up to a maximum indentation.
As an example, here is the top-level 'how-to' (function or procedure) for
processing ixml. There are two documents, ixml, the format
description in ixml, and input, the document to be converted. The
ixml is converted to its structured form by the how-to GRAMMAR; if
that was successful, then the input document is processed using
that structured grammar by how-to PARSE. If that in its turn was
successful then the result is serialised by the how-to
SERIALISE.
\=================== ixml system
\ Thu 31 Aug 15:44:15 CEST 2023
HOW TO IXML ixml WITH input ENDLF endlf:
SHARE trace, g
GRAMMAR ixml IN g AT root
SELECT:
g <> {}: \Parsed OK
INIT INPUT input ENDLF endlf
PARSE input WITH g AT root
IF error.free:
SERIALISE root FROM trace WITH g USING input
ELSE:
WRITE "Failed" /
The input format of the source code is thus a number of how-tos, that all
begin with the words "HOW TO", with optional documentation, which are lines
that begin with the ABC comment character which is a back-slash \,
and possible blank lines. The ixml that describes this looks like the below.
Note that it handles indentation up to 9 levels deep.
abc: (documentation?)++how-to.
documentation: caption, commentary?.
caption: -"\=", -"="*, ~[#a; "="], ~[#a]*, -#a+.
commentary: talk+.
-talk: -"\", ~[#a]*, #a+.
how-to: -"HOW TO ", header, comment?, -#a,
body,
refinement*,
blank-lines.
header: ~[#a; "\"]*.
comment: -"\", ~[#a]*.
-body: line1+.
refinement: name, comment?, -#a, body.
name: [L], [L; " "]*, ":".
-blank-lines: -#a*.
line1: in, line, line2*.
line2: in, in, line, line3*.
line3: in, in, in, line, line4*.
line4: in, in, in, in, line, line5*.
line5: in, in, in, in, in, line, line6*.
line6: in, in, in, in, in, in, line, line7*.
line7: in, in, in, in, in, in, in, line, line8*.
line8: in, in, in, in, in, in, in, in, line, line9*.
line9: in, in, in, in, in, in, in, in, in, line.
-line: (text, comment?; comment), -#a.
-text: ~[" "; "\"], ~[#a; "\"]+.
-in: -" ". {indent}
If we observe the output for the how-to presented above, it looks like
this:
<abc>
<documentation>
<caption> ixml system</caption>
<commentary> Thu 31 Aug 15:44:15 CEST 2023
</commentary>
</documentation>
<how-to>
<header>IXML ixml WITH input ENDLF endlf:</header>
<line1>SHARE trace, g</line1>
<line1>GRAMMAR ixml IN g AT root</line1>
<line1>SELECT:
<line2>g <> {}:
<comment>Parsed OK</comment>
<line3>INIT INPUT input ENDLF endlf</line3>
<line3>PARSE input WITH g AT root</line3>
<line3>IF error.free:
<line4>SERIALISE root FROM trace WITH g USING input</line4>
</line3>
</line2>
<line2>ELSE:
<line3>WRITE "Failed" /</line3>
</line2>
</line1>
</how-to>
The XForms Application
In the XForms application, the above output is read in (in two stages, one
for each part), and then displayed. Since at the top level there are only two
types of elements, <how-to>, and
<documentation>, the structure of the display code deals
with each top-level element accordingly:
<repeat ref="*">
<group ref=".[name()='how-to']">
<switch>
<case id="closed">
displays just the header
<case id="open">
displays the header and content
</case>
</switch>
</group>
<group ref=".[name()='documentation']">
...etc...
</group>
</repeat>
Just the header is displayed as a single minimal trigger:
<trigger appearance="minimal">
<label>
<output class="header-closed" ref="header"/>
<output class="comment1" ref="comment"/>
</label>
<toggle case="open" ev:event="DOMActivate"/>
</trigger>
and the header with its content displayed similarly:
<trigger appearance="minimal">
<label>
<output class="header-open" ref="header"/>
<output class="comment1" ref="comment"/>
</label>
<toggle case="closed" ev:event="DOMActivate"/>
</trigger>
<repeat ref="descendant::*">
<output class="{name()}" ref="text()"/>
<output class="comment1" ref="comment"/>
</repeat>
Note how this uses the name of the element (line1,
line2, etc) to select a CSS rule to display the line with the
right indentation.
Searching
To make the code searchable, we add a search string and a control to input
it:
<input incremental="true" ref="instance('q')/q"><label>search (case-sensitive)</label></input>
And then only repeat over matching elements by replacing the line
<repeat ref="*">
with
<repeat ref="*[contains(., instance('q')/q)]">
which causes only how-tos and documentation that contain the query string to
be displayed. See Figure 5. for an example.
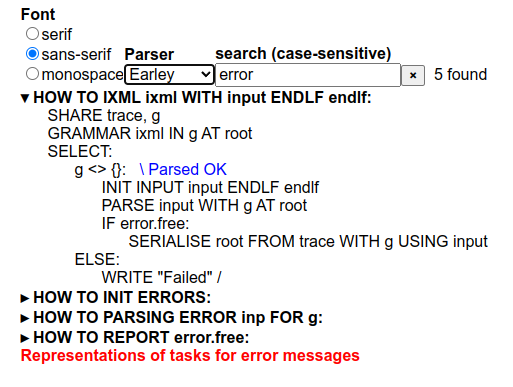 Figure 5.
The search interface in use: searching for the word "error" has revealed 4
how-tos and one piece of documentation that contain the word. One of the
how-tos has been opened.
Figure 5.
The search interface in use: searching for the word "error" has revealed 4
how-tos and one piece of documentation that contain the word. One of the
how-tos has been opened.
Adaptation for other languages
It is observable in the above that there is nothing essential in the browser
that is particular to ABC: there are folding sections of two types, where each
fold consists of a header and a number of lines at different indentations, with
optional comments.
So by changing the abstractions suitably, any format could be injected into
the browser, to make a quick and easy code browser for any format.
Code size
The browser uses 3 declarative languages:
- ixml: 29 lines
- XForms: 87 lines
- CSS: 25 lines
Conclusion
This example application was a quick and easy proof-of-concept demonstration
of the power of combining declarative languages. It was constructed in a couple
of hours. What it showed was that ixml makes injection of unstructured data
into the XML pipeline easy, and that declarative languages make life easy in
general.
The browser is available at [demo].
References
[abc] Geurts et al., The ABC Programmer's Handbook, CWI,
1990, https://cwi.nl/~steven/abc/programmers/handbook.html
[cg] Invisible Markup Community Group, https://www.w3.org/community/ixml/
[demo] Steven Pemberton, ixample source code, CWI, 2023,
http://cwi.nl/~steven/forms/examples/ixampl/ixampl.xhtml
[ixampl] Steven Pemberton, A Pilot Implementation of
ixml, in Proc. XML Prague 2022, ISBN 978-80-907787-0-2, https://archive.xmlprague.cz/2022/files/xmlprague-2022-proceedings.pdf#page=51
[ixml] Invisible XML, https://invisiblexml.org/
[latin1] ISO/IEC 8859-1 https://en.wikipedia.org/wiki/ISO/IEC_8859-1
[py] Lambert Meertens, The Origins of Python, Inference,
Vol. 7, No. 3 / November 2022, https://inference-review.com/article/the-origins-of-python
[spec] Steven Pemberton (ed.), Invisible XML
Specification, invisiblexml.org, 2022, http://invisiblexml.org/1.0/
[u16] Becker, Joseph D., Unicode 88, Unicode Consortium,
1988, https://unicode.org/history/unicode88.pdf
[unicode] The Unicode Consortium (ed.), The Unicode
Standard — Version 13.0, Unicode Consortium, 2020, ISBN
978-1-936213-26-9, http://www.unicode.org/versions/Unicode13.0.0/
[utf8a] Rob Pike, UTF-8 History, 2003, https://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt
[utf8b] Rob Pike, Ken Thompson, Hello World or
Καλημέρα κόσμε or こんにちは 世界, AT&T Bell
Laboratories, 1993, https://www.cl.cam.ac.uk/~mgk25/ucs/UTF-8-Plan9-paper.pdf