Steven Pemberton, CWI, Amsterdam
Invisible XML [ixml] has had a stable specification since 2022, there are currently a half dozen implementations, and typically a dozen presentations per year have recently been given at conferences. At the beginning of 2026 the first International Symposium on Invisible XML was held [sym], with 14 presentations and 40 or so attendees. Meanwhile there is a working group [wg] developing the language further.
This paper gives an overview and discussion of the topics and issues currently being considered within the community on the route to the next version.
Keywords: markup, invisible xml, ixml, notation design, parsing, standards
Since its introduction, ixml usage has been increasing over a surprisingly broad range of applications, including art [art], analysing late Roman trials [trials], aircraft maintenance parts ordering communications [msg], designing knitting patterns [knit], processing Vehicle Identity Numbers [vin], banking [bank], parsing literature [lit], and many others. With this experience emerges requests for features or support for use cases. These requests get noticed by, or passed on to, the working group for consideration, and often arrive as requests for particular features, for instance, similar features available in other languages.
There are two observable streams in notation design, the one which could be characterised as 'kitchen sink' design, adding all imagined features to the language without consideration of how they fit together; the programming language perl can be seen as an example of such a design. The other stream is about recognising requirements, and finding unified, consistent ways of satisfying those requirements, python being a contender for being an example of such a design: see for instance The Zen of Python [zen] for a set of rules that was used to direct the design of the language. Einstein's maxim "Everything should be kept as simple as possible, but no simpler" is a good aim when designing: it implies not adding two different mechanisms to achieve the same result, which means designing from use cases, and not features.
The rest of this paper will discuss individual issues under consideration within the community.
Rules in ixml define two things: 1) the input syntax, and 2) the details of how the resulatant parsetree should be serialised. In ixml 1.0 the serialisation of an element or attribute always has the same name as the rule it comes from.
However, two different input syntaxes might represent the same output serialisation (for instance two different date formats). This originally meant that one abstraction, with two different input formats, had to have two separate output formats as well.
Renaming gives you more control over this, by allowing you to use a different name from the rule name on serialisation. Without renaming, you get
date: y, m, d.
⇒
<date><y>2025</y><m>08</m><d>06</d></date>
While using renaming gives a different serialisation:
date > d: y, m, d.
⇒
<d><y>2025</y><m>08</m><d>06</d></d>
This is completed work that is already agreed on by the group, but not yet officially published. It gives control over the element and attribute names used in serialisation and is already widely implemented. See the modularisation paper [mod] for examples of its use, and the work-in-progress ixml draft [ixml2] for its definition.
Since the release of ixml, two developments have been observed: firstly, some very large grammars are emerging, such as the one for XPath 4 [xp4] at 350 lines, and 200 rules; the second is that several grammars are being written with common subparts, for instance for URIs, and indeed XPath expressions.
Modularisation addresses these issues by allowing you to split grammars into smaller more manageable parts, and allowing you to specify which rules may be used by other grammars, while at the same time protecting you from name clashes across the combined grammar. For example here is the proposed syntax of a module, using its own definition:
+uses ixml, name, s, RS from ixml.ixml;
iri from iri.ixml
+shares module
module: s, (multiuse; shares)*, ixml.
-multiuse: -"+uses", RS, uses++(-";", s).
shares: -"+shares", RS, entries.
uses: entries, RS, -"from", RS, from.
-entries: share++(-",", s).
share: @name, s.
@from: iri, s.
The proposal allows modularisation to be done by a preprocessor, so that a processed modularised grammar can still be fed to implementations that don't support modularisation directly.
See the paper from MarkupUK 2025 [mod] and a slightly different proposal from Norm Tovey-Walsh [mod2].
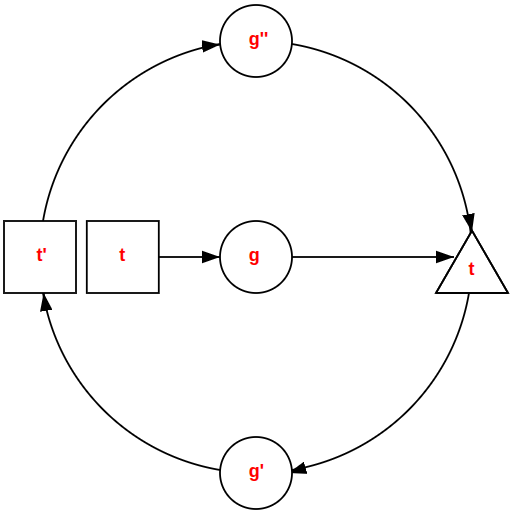
Round tripping is about recreating an equivalent input document from the output of ixml.
At first sight, it would appear that round tripping of ixml, recreating the identical document that produced the output, is not in general possible, since an ixml grammar can delete characters that were in the input, and add other characters to the output. However, by defining round tripping as "producing a document that would produce the same output", it is possible in the general case.
The process works by transforming the ixml grammar that produced the output into one that recognises the output produced by the original grammar, and serialising only the terminal characters of a resultant parse, thus producing a textual document that when processed with the original grammar produces the same output. The one implementation to date [rti] refers to this process as "creating the canonical value", since although the new document is not character-for-character identical with the original, running it through ixml, and back again will continually produce the same textual document.
An interesting corollary to this is that transforming the transformed
grammar in the same way a second time produces the same output as the original
grammar, but requiring less work from the ixml serialiser, pointing to a
possible way of simplifying the ixml serialiser.
The round tripping process. Input t is the original input, which is processed using the original grammar g to produce output t. Transforming grammar g to produce grammar g' allows the output t to be transformed back to input document t', which though not identical to t, will produce the same output as t when processed using grammar g. However, transforming g' using the same transformation process to create grammar g'' will also produce the identical output, but with far simpler use of the ixml serialiser.
This is further described in [rt].
Ambiguity in ixml is a property of the input.
Although the aim of ixml is to describe input formats so that their structure can be recognised without the need for markup, ambiguity is nevertheless deliberately accepted, firstly from a usability point of view, since it allows you to get some result, with a warning that there are other possibilities, and secondly because some input ambiguities may not produce an output ambiguity, in which case it makes no difference which parse gets serialised.
Since ixml does not dictate which parser should be used, but only the properties of an acceptable parser, it is not reasonable to require a particular parse of the ambiguous input, so it is unspecified which parse is serialised; this means that different implementations may produce a different result.
Although ixml permits and handles ambiguity, there are some disadvantages to having an ambiguous grammar: apart from the uncertainty of whether the serialisation represents what the grammar writer intended the structure of the document to be, there is the disadvantage of speed, since an ambiguous grammar requires the input to be parsed multiple times.
Ambiguities can be divided into several classes.
Some ambiguities are only on the input, such as deleted spaces in this example:
input: number*. number: spaces, digit, spaces. digit: ["0"-"9"]. -spaces: -" "+.
Even though this is ambiguous, all parses will produce an identical serialisation.
Some ambiguities are due to badly written grammars. For instance,
expression: number; identifier; expression, op, expression. op: ["+-×÷"]. identifier: [L]+. number: ["0"-"9"]+.
For an input like
a-b-c
this will produce two different parses one effectively
(a-b)-c
and the other
a-(b-c)
which have different meanings. The grammar has been incorrectly written.
Nothing should be done about this case. There is no doubt that tracking down ambiguities can be difficult, and time-consuming for inexperienced grammar writers, but trying to solve this by ad hoc means doesn't solve the underlying problem that the input is not properly described, nor would it guarantee that you get the serialisation that you want in all cases. It is a potential source of technical debt.
Some ambiguities are inherent in the input, such as US/World dates, like
4/5/2026,
date: us; world.
us: month, "/", day, "/", year.
world: day, "/", month, "/", year.
day: d, d?.
month: d, d?.
year: d, d, d, d.
d: ["0"-"9"].
Still, even in these cases it is possible to rewrite it to an unambiguous grammar that explicitely identifies ambiguous and non-ambiguous cases:
date: us; world; ambig.
us: month, "/", day, "/", year.
world: day, "/", month, "/", year.
ambig: md, "/", md, "/", year.
day: "1", ["3"-"9"]; "2", "0"-"9"; "3", ["0"-"1"]. {13-31}
month: "0"? ["1"-"9"]; "1", ["0"-"2"]. {1-12}
md: -month.
Although this still identifies dates like 1/1/2026 as
ambiguous, since they are syntactically ambiguous, even though they aren't
semantically ambiguous, even these cases are in principle handleable with a yet
more complex grammar; this wouldn't disambiguate the cases though, just choose
one in favour of the other.
There are two possible approaches to dealing with ambiguity. One is to allow it, and add the ability to select amongst ambiguous parses. The other is to add expressiveness to the grammar notation to ease making unambiguous grammars.
For the first, some approaches add priorities to rules [peg], [prio], that allow the selection of
one rule above another when it comes to ambiguity. There are some dangers to
this approach; for instance CSS [css] has a similar feature
where the !important keyword gives a rule priority over others.
This was introduced for a very particular (legal) use case, but has proven to
be an enormous source of technical debt, since people often tend to use it for
a quick fix, making stylesheets that use it fragile, and hard to update.
One of the observable problems of specifying grammars is the difficulty of splitting input into distinct cases. For example:
catalogue: entry*.
entry: header, item+.
header: text, code, #a.
item: text, #a.
text: word++" ".
-word: (l; d)+.
-l: [L].
-d: ["0"-"9"].
@code: l, l, l, d, d, d.
Example input:
Fiction fic001 Ulysses Brave New World 1984 NonFiction non123 Translating Beaudelaire The Sixth Extinction
The underlying problem here is a badly designed input format, but it is
necessary to deal with the real world and handle formats like this. In this
case, word and code are not distinct, so
header also matches item. You could add a priority to
a rule:
header: text, code, #a. !important
which would say that in the case of ambiguity, choose this rule, but this doesn't explicitly express what is going on, making it hard to understand, and harder to update later, nor does it take away the problem of having to parse an ambiguous document in the first place.
A better solution would be the ability to say explicitly "An item is any string of characters where the last word doesn't match a code." For instance,
item: word**" ", " ", lastword, #a. -lastword: word!code.
Here word!code means a word, as long as it doesn't match a
code. This approach will mentioned more shortly.
In passing it is worth mentioning the problem of spaces, since they are a typical source of ambiguity, and one of the harder aspects of free-format inputs for inexperienced grammar writers. This may be because classically there is a lexical analyser feeding tokens to the parser, so that the parser never sees spaces, and so the grammar doesn't need to mention them.
One way to deal with this in ixml is to have a 'lexical' part to the grammar, that simulates the lexical analyser, and deals with spaces between symbols:
OPEN: "(", s.
CLOSE: ")", s.
PLUS: "+", s.
and so on, so that spaces don't have to appear in the main body of the grammar. Adding a lexical analyser to ixml wouldn't solve this problem, because the syntax of tokens still have to be described, and ixml already has a method of describing syntax.
Since spaces are such a recurring problem, it would be tempting to define a
mode of processing where if an input character fails to match, and it turns out
to be a space, then it is just ignored, but in truth, there are few input
languages where spaces are never relevant. In the 60's programming languages
like FORTRAN and the Algols were explicitly designed so that spaces were never
relevant (even in strings, in the case of the Algols), but nowadays that is
seldom the case. For instance in CSS p.note and p
.note have very different meanings. Even ixml has places where spaces
are required.
As mentioned, traditionally parsing has been done in two stages, with two parsers running in parallel, a low-level lexical analyser, whose input is a string of characters, and whose output is a string of 'tokens', and then the main parser whose input is those tokens, and the output a parse tree.
This was needed traditionally to enable the use of non-general parsing algorithms such as LL(1), which would otherwise not be possible in most cases. However, there are new approaches that add constructs to the syntax description method that remove the need for a lexical stage. See for instance [vdb].
The current ixml proposal is to add one construct, with the syntax not yet finalised. Alongside A*, A+, A?, a construct A! is added to mean "An A may not appear here".
For example,
identifier: letter+, letter!.
means "The longest stretch of letters that can be matched". Thus, with
keyword: "if", letter!;
"then", letter!;
"else", letter!.
identifier: keyword!, letter+, letter!.
this last rule would then mean "an identifier is the longest string of letters that is not a keyword".
In designing XML, the group responsible did a clever thing when adding a
notation for namespaces [xmlns]: they designed the
namespace declarations to look like attributes, so that XML documents would be
syntactically compatible with earlier software, but they would have a different
semantic interpretation because they begin with the characters
xmlns.
The same approach could be used for ixml: by specifying that things that
look like attributes in the serialisation but begin with the characters
xmlns should be interpreted as namespace declarations. For
implementations that produce textual output, this adds no extra processing; for
implementations that go directly to an XML internal form, the namespace
declarations have to be recognised and handled appropriately, as they are in
XML processors.
Accepting this, you could define a rule whose output is the shell of an HTML document to include a namespace in this way:
html: xhtml-ns, head, body. @xhtml-ns>xmlns: +"http://www.w3.org/1999/xhtml".
which would give
<html xmlns='http://www.w3.org/1999/xhtml'>
A problem for beginners coming to ixml is that they may have internalised idioms from other similar systems that work differently from ixml. A good example of this is greedy matching as used in typical regular expression recognisers, where in many regular expression implementations the pattern
["a"-"z"]*
matches the longest-possible stretch of lower case letters; however, in traditional grammar usage it represents any length that fits in the context of where it is used, and not necessarily the longest.
An option would be to introduce a separate notation to specify the longest possible stretch, for example
["a"-"z"]>>
which then for consistency would require a similar construct for separated repeats
["a"-"z"]>>(",", s?)
However, as already seen, the negation construct would already allow the specification of longest stretches, so it is not clear that adding another construct for this explicit case would be necessary.
Grammars in ixml have extra constructs available, not available in traditional grammars, and not mentioned in traditional parsing algorithms, in particular the structures for repeated constructs with separators. As a section in the ixml specification points out, it is easy to handle these constructs, partly thanks to serialisation control, by transforming the grammar into an equivalent one that doesn't use the constructs.
Some grammar systems allow the specification of numbered repeats, for instance "zero or more up to 6 letters". As an example ABNF [abnf] allows
3 digit
to specify exactly 3 digits,
1*4 digit
to specify 1-4 digits, and so on.
There are very few grammars that requires such a notation, though it would be easy to transform a grammar using such a construct into one not using it.
This is surprisingly a contentious issue: how to address individual pieces of software.
Software occasionally provides a mechanism for instructing a processor to act in a certain way. XML itself has Processing Instructions, that consist of a target that specifies what the pragma is about, and content, which is used by software that processes such instructions. For instance
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
These are typically a type of comment: they don't alter the semantics of the language, but instruct a mode of operation to the processor.
A paper [pragmas] proposed using pragmas not only to address individual software, but also as an extension mechanism. The danger of this is that conflating the two aspects risks undermining the interoperability of ixml.
Since pragmas are there to talk to individual pieces of software, it would seem advisable to let the software specify what they expect, within a broad but simple structure in the style of XML processing instructions: identify the target, and let the target do the rest. A pragma should be identifiable as such, and the content should be up to the addressed software.
Most software (for instance programming languages) doesn't require its input to specify which version of the processor is required. In fact XML is a bit of an exception on this point, and it is not obvious what the advantages are to the user of requiring it; it certainly seems to have obstructed adoption of new versions. It may be used as a pragma to the processor to require a certain type of processing or checking, but this is only really necessary when the semantic meaning of a particular syntactic structure has changed between versions.
The current method of specifying the version was added in haste shortly before publication of the specification, which was a mistake, because it left no time to implement and try it out beforehand. In general, a user shouldn't have to be confronted with the need to know which version they are using. As a result, the absence of a version should always be taken to mean "use the most recent version"
The adage "Good food takes time" applies equally well to design: there are many interlocking decisions where a change in one part can affect the design of another part, and they need to be designing to achieve a good symbiosis with each other, and then user tested to see the real-life effects of the changes.
The design of the first version of ixml itself went through several iterations, and had small-scale user testing before it ended up as version 1.0. The next version, 1.1, or 2.0, however it will be numbered, has many, sometimes apparently conflicting, requirements that need to be resolved and meshed together.
[abnf] D. Crocker, Ed., RFC 5234 Augmented BNF for Syntax Specifications: ABNF, ietf.org, 2008, https://datatracker.ietf.org/doc/html/rfc5234
[art] Mary Holstege, “Invisible Fish: API Experimentation with InvisibleXML.” In Proceedings of Balisage: The Markup Conference 2024, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Holstege01
[bank] Steven Pemberton, Banking with ixml and XForms, Proc. Declarative Amsterdam 2024, Amsterdam, The Netherlands. https://declarative.amsterdam/article?doi=da.2024.pemberton.banking
[css] Håkon Wium Lie et al. (eds.), Cascading Style Sheets level 1, W3C, 1996, https://www.w3.org/TR/CSS1/
[ixml2] Steven Pemberton (ed.), Invisible XML Specification Community Group Editorial Draft, Invisible XML Organisation, 2026, https://invisiblexml.org/current/
[ixml] Steven Pemberton (ed.), Invisible XML Specification, Invisible XML Organisation, 2022, https://invisiblexml.org/1.0/
[knit] Bethan Tovey-Walsh, “When women do algorithms: a semi-generative approach to overlay crochet with iXML and XSLT.” In Proceedings of Balisage: The Markup Conference 2024. Balisage Series on Markup Technologies, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Tovey-Walsh01
[lit] Steven Pemberton, “The Book of Doublends Jined: Parsing Finnegans Wake with ixml.” In Proceedings of Balisage: The Markup Conference 2025. Balisage Series on Markup Technologies, vol. 30 (2025). https://doi.org/10.4242/BalisageVol30.Pemberton01
[mod2] Norm Tovey-Walsh, An Invisible XML modularity proposal, 2026, https://nineml.org/proposals/2026/modularity/
[mod] Steven Pemberton, Modular ixml, Proc. MarkupUK 2025, pp 6-20, https://markupuk.org/pdf/proceedings-2025-2.pdf
[msg] Ari Nordström, “Adventures in Mainframes, Text-based Messaging, and iXML.” In Proceedings of Balisage: The Markup Conference 2024. Balisage Series on Markup Technologies, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Nordstrom01
[peg] Bryan Ford, "Parsing Expression Grammars: A Recognition Based Syntactic Foundation" (PDF). Proceedings of the 31st ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. 2004, ACM. pp. 111–122. doi:10.1145/964001.964011. ISBN 1-58113-729-X.
[pragma] Tomos Hillman, C. M. Sperberg-McQueen, Bethan Tovey-Walsh and Norm Tovey-Walsh. “Designing for change: Pragmas in Invisible XML as an extensibility mechanism.” In Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27 (2022). https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01
[prio] E. Shinan, Lark: A parsing toolkit for python (2025), github, https://github.com/lark-parser/lark
[rti] Alain Couthures, Text normalization with Invisible XML round-tripping, Proc Declarative Amsterdam 2025, https://declarative.amsterdam/article?doi=da.2025.couthures.grammix
[rt] Steven Pemberton, Round-tripping Invisible XML, in Proc. XML Prague 2024, Prague, Czechia, 2024, pp 153-164, ISBN 978-80-907787-2-6, https://archive.xmlprague.cz/2024/files/xmlprague-2024-proceedings.pdf#page=163
[sym] Various, The First International Symposium on Invisible XML, invisiblexml.org, 2026, https://invisiblexml.org/events/symposium2026/
[trials] C. M. Sperberg-McQueen, “From Word to XML via iXML: a Word-first XML workflow in the TLRR 2e project.” In Proceedings of Balisage: The Markup Conference 2024. Balisage Series on Markup Technologies, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Sperberg-McQueen01
[vdb] M.G.J. van den Brand, et al., Disambiguation Filters for Scannerless Generalized LR Parsers. In: Horspool, R.N. (eds) Compiler Construction CC 2002. Lecture Notes in Computer Science, vol 2304. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-45937-5_12, https://cwi.nl/~jurgenv/papers/CC-2002.pdf
[vin] Ari Nordström, It's Useful After All — VIN Numbers, DITA, and iXML, Proc XML Prague 2024, pp 295-306 https://archive.xmlprague.cz/2024/files/xmlprague-2024-proceedings.pdf#page=305
[wg] Invisible Markup Community Group, https://www.w3.org/community/ixml/[xmlns] Tim Bray et al., Namespaces in XML 1.0, W3C, 2009, https://www.w3.org/TR/xml-names/
[xp4] John Lumley, Invisible XML workbench, Github, 2024, https://johnlumley.github.io/jwiXML.xhtml
[zen] Tim Peters, PEP 20 - The Zen of Python, python.org, 2004, https://peps.python.org/pep-0020/