At the moment of writing, the project is still in an early stage. As it is primarily a research project - although having prototypes as deliverables - our ideas will undoubtedly continue to evolve as the work proceeds and influence the final product. So this paper should be read as a snapshot of our present views. Rather than giving an overview of all envisioned functionality, we focus on some of the aspects that we find most interesting. As we go along, we point out our various aims and plans.
The Acela project is supported by the Netherlands Technology Foundation (STW), and, through the linked MathViews and winst projects, by the Netherlands Foundation for Computer Science Research (SION) and the Netherlands Foundation for Mathematics (SMC). At present, some ten more people (Hugo Elbers, James Faux, Willem de Graaf, Nico van den Hijligenberg, André van Leeuwen, Marc van Leeuwen, Bert Lisser, Steven Pemberton and Marcel Roelofs) work directly on the project, with several others (Henk Barendregt, Michiel Hazewinkel, Norbert Kajler and Jan-Willem Klop) involved more peripherally. It should be clear that the ideas presented here are not only those of the authors of this paper, but were shaped and refined by a collective effort.
In general, that combination of text and expert is important. Traditional books are infinitely patient: you can consult them as often as you want. At the same time, they are oblivious to any reader need beyond the static text offered: you cannot ask questions to a book and expect an adequate response. Traditional teachers are not - or shouldn't be - oblivious to their students' needs, but infinitely patient they are definitely not. An interactive book can combine (some of) the best of two worlds, and at the same time encourage and support active participation of the reader - as opposed to the often too passive modes of reading a book or listening to a teacher.
The observation that human teachers are of limited patience has been one of the motivations for the earlier work on Computer-Aided Instruction. We wish to point out a fundamental difference between "classical" CAI and our view of how the reader will interact with the book.
In classical CAI, the assumption is that there is a given syllabus, a well-delineated body of knowledge, that students are supposed to master, whether motivated or not. Accordingly, there is generally a fixed route through the material, with much emphasis on testing if the student indeed mastered a morsel of knowledge, typically with a dialogue controlled by the automated instructor.
Our assumption is that the reader, in consulting the book, is motivated to understand, or at least find out, something - and it is up to the reader to define what precisely that something is. It might be a mere trifling trinket in the wealth of wisdom stowed in the book. Thus, the book metaphor is essentially more apt than the instructor metaphor. In a paper book, the reader can just browse, instead of perusing it from cover to cover, consult it in any haphazard order, skip any sections, examples, exercises, et cetera, and come back to any point at any time. To call an interactive system an interactive book, not only should there be a text(1), prepared by an author for readers, but we also hold the tenet that all interaction is initiated, and in general controlled, by the reader.
Not in all aspects are interactive books superior to more traditional books. For the time being, they (or, rather, the equipment needed for consulting them) will be less easy to carry around. (On the other hand, for electronic books it hardly makes a difference whether we have a small text or a comprehensive encyclopedia.) The resolution of affordable screens is an order of magnitude less than that of high-quality printing, which makes it tiring to read the fine print in mathematical formulae like "npi". Also, the initial investment in acquiring the necessary equipment is sizable, and the initial production cost is appreciably higher (although, on the other hand, the unit reproduction cost of the book texts themselves is basically the cost of the medium, and if distributed through networking virtually free).
A book's interactive potential has to be substantive before it offsets these disadvantages. We now discuss several possibilities that are offered by an interactive setup. Although we group them for convenience, the boundaries between these groups are not sharp. As a non-mathematical running example we take an interactive cookbook. Most of the sophisticated interactive "features" mentioned below for this cookbook can be found in commercially available programs, such as Haute Cuisine.
Unfolding/folding can be used for quick navigation through a table of contents. In a cookbook, clicking on the first item of the following list
A beginning chef might not know the meaning of some technical term, say "sauté" . Clicking on such a term will display an explanation. An alternative possibility is to "macro" expand the sentence in which the term occurs. For example, Sauté the slices of liver" is expanded into "Cook the slices of liver in a small amount of cooking fat or oil until brown and tender, using a skillet on medium fire and stirring well".
Note that the extent of navigation facilities need not be confined to the book itself; the book proper may be a coordinated collection of nodes in a larger web of active knowledge. This is of obvious relevance to mathematics (as well as many other fields of knowledge), and we come back to this in the next section.
There are more exotic possibilities. Given a menu (a collection of recipes, one for each course) the book can present a merged and sorted shopping list. Also, it can merge the preparation steps of the recipes for the various dishes into one time axis and produce one combined list of instructions, so that a cook can work in parallel on several dishes without ever having to jump to and fro between different recipes.
Expert assistance can also be helpful in composing a menu. In its simplest form, the user composes a tentative menu, whereupon the book reacts with an evaluation, using basic rules about the desirable variation in a menu as well as "common-sense" and user-supplied constraints. In a more advanced setup this can be a truly interactive affair, with the book also suggesting modifications, and using the user reaction to those to adjust the constraints.
This does not exhaust the possibilities; neither in general (for example, we have not mentioned setting bookmarks), nor those specific to cookbooks (for example, planning ahead to use parts of a preparation for a later day, or giving advice what to do with leftovers), and, in fact, the possibilities are limited more by our imagination than by technical constraints. The preceding should be indicative, though, of the nature of the extra value that interactivity can add to a book.
Yet, there is something unique to the mathematical world: it is a formal world that does not of itself refer to the outside world. Any such references, as in mathematical physics, are externally imposed interpretations on symbols that by themselves have no meaning grounded in reality.
To learn to cook, the aspirant cook has to get hands-on experience and stir the pots and pans. No amount of reading, however interactive, can fully replace that experience(2). In mathematics, the "real world" is the mathematical world "in here": if some piece of mathematics can be done at all, it can - in principle - be done now and here, in the medium of the book. This opens unique possibilities for active reader involvement.
Let us examine in more detail the interactive potential that is of specific value (although generally not exclusively so) in a mathematical context. We follow the same grouping as in the previous section.
By taking Lie algebras as the subject matter for our first prototype, we hope to establish convincing evidence that an interactive book offers the reader a more active involvement than is possible with a paper book, a better guided tour than is provided by a computer-algebra package, and a more rewarding experience than obtained by using these two together but separately, as independent entities.
This system needs content, like a record player needs a record; in this case, the content is the text of the book.
For a proper separation of concerns, we wish to consider the "truly" subject-dependent part as belonging to the content. So the content of a book can consist, next to a text, also of algorithmic entities: author-supplied methods to work on the types of objects occurring in the text. When the book "record" is loaded into the system "player", these methods are loaded as well. Part of the project is indeed devoted to create powerful implementations of various algorithms for Lie algebras.
Still, we foresee that we have to take account of the future mathematical content right from the start, and very seriously so, even for the design of the kernel system. The demands posed by the requirement that mathematics can be brought to life are non-trivial, and would be virtually impossible to meet by afterthought modifications.
A simple example of this is the user control over the mathematical notation. This requires a strong logical separation of content structure and visual presentation, something that is missing in almost every mathematical-document preparation system. For example, although the presentation structure of f(x) is juxtapose(identifier(`f'), parenthesis(identifier(`x'))), its content structure is apply(function=identifier(`f'), argument=identifier(`x')). If content structure and presentation structure are not kept separate in the software ab initio, it is practically impossible to pry them apart later. Such a separation is only possible if it is catered for in the architecture itself.
More generally, the desire to achieve transparent interoperability with external engines requires a flexible juggling with various representations for the same (mathematical) object. The actual representation rules are, of course, part of the (algorithmic) content of the book, but it would be awkward, to say the least, if the infrastructure for handling "Protean" representations and interposing the right transformations is not provided by the kernel system.
Our intentions with regard to proof checkers are twofold. First, we want to explore to what extent the mathematics presented in the interactive book can be formalised so as to be understandable to a proof checker such as Lego [7]. Second, as logic-based proof checkers like Lego are notoriously inefficient in dealing with equational reasoning, the task of checking straightforward computations (both arithmetic and by symbolic calculus) had better be checked by a package more suitable for this task: a computer-algebra system.
As an experiment, a definition of Lie algebra and a check that the commutator for an associative algebra defines a Lie algebra have been formalised, and checked by a combination of Lego and Reduce. Although, for this exercise, the interoperation has been programmed ad hoc, this has shown that a non-trivial automated synergy between logic-based proof checkers and symbolic computation is feasible, as well as provided insight into the requirements for a more generic approach.
The book will provide the infrastructure for the interaction between, e.g., a proof checker and a computer-algebra system. In order that a proof checker can ask the book to evaluate an equality involving symbolic computations, which the book can redirect transparently to a computer-algebra engine, a connection with a computer-algebra engine must be established. The representation that this engine requires for input is in general quite different from the proof checker's query: representations vary from engine to engine. From the point of view of the book proper, the editor can further be seen as yet another external engine. As the interactive book needs to communicate with all these applications, it needs to be able to convert the internal representation of an object to the various external representations and vice versa. This poses several demands on the internal representation of a mathematical object. One key concept here is that of application descriptions: information relating the functionality of an application to the interpretational capabilities of the book - in particular giving the (co)domains and mapping rules for different operations as well as rules for maintaining a shadow copy of application-bound state information. Another key concept is that of context: a formalised description of the active set of mathematical knowledge in which the information is to be interpreted(3). These concepts are worked out further in [5].
For our setup we need to use a protocol and transfer format for the transfer of basic data. While developing it, we will stay in correspondence with other groups, such as the Open Math project (which is developing a transfer protocol to be added to Maple) and the CMLT working group (see Section [5.2]). Also of relevance is the SGML data type definition developed for the Euromath editor [10].
We want the reader of the book to get into it with a minimum learning effort. The general experience is that users of interactive systems do not read the manual first. It is better to acknowledge this fact when designing the interaction. We hope, in fact, to design it in such a way that the reader does not need a manual to use the system, but can do with a small "try-me" interactive note on how to get started, together with adequate on-line help facilities. For the latter, we can use the basic navigation-support technology - provided that the user can do basic navigation without needing help for that. Providing access to the help facility using suggestively labelled buttons for hierarchical browsing, supplemented by an "enter-topic" query field, should do the job. More advanced navigation support should then be among the easily found help items.
For the more significant interactive potential, the expert assistance, it is helpful to the user if there is a uniform interaction paradigm. It may or may not be possible to obtain, through the book, direct access to some external engine, i.e., where the access is not mediated by the book. That depends on the contents of the book - authors can always create a book in which this is possible, and if the topic of the book is, say, "Using Maple", this will be completely appropriate. However, the idea is that, such exceptional cases apart, all access to external engines is mediated transparently by the book.
"Transparent" implies here that the interface keeps the same "look and" feel, whatever the engine used. Our intention here is to use the interaction paradigm developed in the Views project [8], specifically with the aim of creating a unified interaction model for the interoperability of varying applications. (see Figure 2).
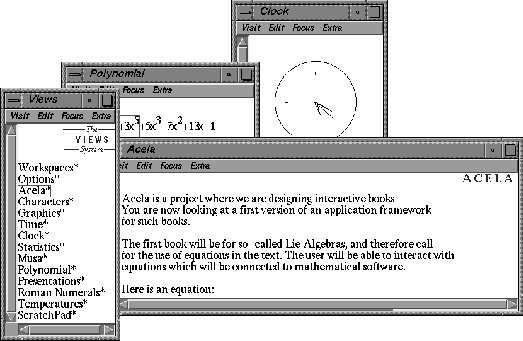
The conceptual model there is that all interaction is achieved by the user by editing documents. These documents may be structured, and contain mathematical objects. The notion of editing comprises ways to enter and change text, as well as facilities for moving around and searching - in short, navigation.
In this interaction paradigm, performing some "symbolic" operation on a formula (like EVALUATE or SIMPLIFY) is then best modelled as an edit operation that is performed in situ. By selecting a subformula, the operation can be restricted to only that subformula. (The semantics of such an operation may depend on the kind of formula on which it is performed. Moreover, just as for a PRINT operation, various options for a complicated operation can be set by the user in a "preferences sheet" for that operation. However, ultimately, which method is invoked given all this is determined by the author of the book.) While the operation - which may possibly take a long time - is not completed, the reader will not be locked in but be able to continue with something else. The result of a still uncompleted operation is temporarily represented by a promise: a special object that can be copied, and all of whose instances will be replaced by the result upon completion.
An essential part of the Views interaction paradigm is that the semantics of the system as it presents itself to the user is based on defined logical relationships between various documents. If one is modified by the user, the system recomputes and updates the other. A basic example of this is a spreadsheet. A more involved example can be a query on a database and the result. By editing the query, the result is automatically updated. Exercises and active examples can easily be created with this mechanism.
Similarly, the visual presentation of formulae is determined by one or more "notation sheets", which are style sheets for the type or sub-types of "formula". By editing these sheets, the user can exercise control over the notation.
Since all users are familiar with the basic edit paradigm, getting to work with this interaction paradigm needs hardly any learning.
As for reading, the interaction paradigm for authoring will be that of editing text. The additional tools will facilitate structuring and restructuring, creating hyperlinks as well as the dependencies that are used for setting up routes, and interactively plugging in interfaces to external engines, together with monitoring and debugging aids.
For technical reasons, the first volume, on Lie algebras, will not entirely be built in this way: we cannot afford to wait until the prototype system is stable before starting to create the contents of the book. In addition, in designing the authoring facilities, we hope to learn from the experience obtained by the off-line creation of the text, in particular what need for facilities was felt.
Our goals are to produce a text that
The documentation on the algorithms used should be quite extensive. In fact, we will strive for the following facilities:
A first prototype of a discrete-mathematical algorithm was written by M. van Leeuwen and J. Faux. It represents the mathematical objects "Young tableau" and "Zelevinsky picture" in an attractive pictorial way on the screen, with possibilities to visually invoke algorithms like Schützenberger's "glissement" and the Robinson-Schensted correspondence.
Both are based on proprietary commercial systems, Mathematica and the GRIF editor [9], respectively. This makes them unsuitable as a vehicle for our research plans. Nevertheless, as an experiment, we are trying and setting up a sample from our text on these systems, to get a clearer picture of what hard limitations are encountered.
As to the Mathematica notebooks, these can be seen as a shell around Mathematica, which is not only a computer-algebra engine, but also a document processor and a programming language in one.
In many respects Mathematica is a fine product, and for many subjects it is an easy tool for building an interactive textbook (see Figure 3).

Figure 3: Mathematica notebook
However, it has several shortcomings that make the user interface of such a book more awkward than is desirable.
The internal representation of mathematical objects is dictated by Mathematica. It does not offer control over linking the interpretation of various symbols to the context in which they occur, and thus makes it impossible to achieve the interoperability we aim at. For example, in "x", the assumption is that "x" is a number, and not an element of some other algebra with a multiplication operator - like word concatenation in formal language theory.
The text of a Mathematica notebook is static, and it is impossible to tailor it to user need. Apart from an outlining facility, there is no hypertextual support. The activity comes from the reader talking directly to Mathematica. Thus, there is no hope of using the Views user-interface paradigm for an interactive book based on Mathematica.
Mathematica has also (somewhat rudimentary) facilities for communicating with external programs - all conversion has to be done on the other side.
The Euromath system is basically a kernel system consisting of a versatile generic structure editor, together with appropriate definitions of mathematical structures. The kernel system itself has - as in our envisaged architecture - no specific mathematical knowledge. There is a separation between logical structure and presentation structure, and the presentation rules are specifiable for each object type. The editor can handle most of conventional mathematical presentation, both for input and for output.
The set of edit actions is extendible, and the semantics of these actions can be an arbitrary piece of code. So the Views interaction paradigm would seem consistent with this architecture, and to a certain extent it is; in fact, this possibility is an addition to the original GRIF editor that was inspired by the Views paradigm.
However, unlike what we aim at and consider indispensable, the presentation rules can only be changed off line; during a session (a run of the system), they have to remain fixed. The concept of routes depends on the interactive computation and activation of a new presentation, and can therefore not be modelled (except by computing a complete new text).
As in Mathematica, there is no support for interpreting formulae in context. For interfacing with external engines, there is a translation facility, which, however, works only in one direction: outward. Thus, text can be shipped to LATEX, e.g.; but there is no convenient way to receive results from computer-algebra engines.
Most of the limitations mentioned above for Euromath and Mathematica are addressed in CAS/PI [4], an experimental system whose central notion is the interoperability of various engines: the internal representation of text and formulas is independent of the display views and the external views, and the necessary translations are handled transparently. CAS/PI offers the user a graphical interface to a formula editor, in which it is possible to mix text and expressions (but not graphs), and to select subexpressions via the mouse and request in situ evaluation (see Figure 4).
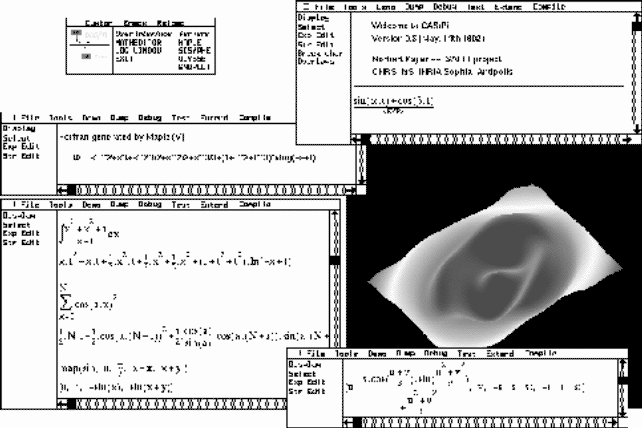
Figure 4: Sample CAS/PI session
The graphical notations, as well as the menus and mouse-based edit actions, are extendible at run-time. Like Mathematica, CAS/PI offers no hypertextual support.
None of the individual aims we have is by itself unique, in the sense that some product exists that realises it. At the same time, each existing product - in its current incarnation - has limitations that make it unsuitable for realising the interactive book we have in mind. The main contribution of our project in this context would be in showing how the various desiderata can be combined gracefully.
The architecture of the system will be strictly modular, and every component module is by itself a piece of software with a well-defined and documented functionality, usable and useful in a variety of contexts and software products.
The whole project is structured modularly as well, in a similar fashion. It has been set up as a collection of co-operating subprojects (textbook, algorithms, kernel architecture, mathematical objects, proofs), in which each subproject has goals and deliverables that are useful and worth aiming for in their own right, and no subproject is critically dependent on the results of some other subproject.
Whenever possible, we intend to reuse existing software, or adopt existing satisfactory solutions, and concentrate in the research on the aspects that we see as novel. Among those are the development of a theory of mathematical objects that allows for transparent interoperability with a large variety of external engines, and the development of an architecture for interactive books that allows for a proper separation of concerns - in particular between those concerning the book "player" as opposed to the contents of the book, as well as between structure and presentation.
Any form of interoperability can ultimately only be successful through the use of a common standard, whether used at the scale of a single project (requiring some form of adaptation for externally supplied software), or adopted at a wider range. System-level standards for document-centred computing are now emerging and will be watched closely. An essential requirement for us, though, is that such standards be both platform-independent and vendor-independent.