On the Design of Notations
Steven Pemberton, CWI, Amsterdam

ME
ME
= Maine
Looking at GA= Georgia, and FL= Florida, it appears that there is no real rule.
Looking at GA= Georgia, and FL= Florida, it appears that there is no real rule.
NE: Nevada or Nebraska?
NE: Nevada or Nebraska?
It's Nebraska, but NB (or NR, NR, NS, NK) would have been better
NE: Nevada or Nebraska?
It's Nebraska, but NB (or NR, NR, NS, NK) would have been better
MI: Mississippi, Missouri, Michigan, or Minnesota?
NE: Nevada or Nebraska?
It's Nebraska, but NB (or NR, NR, NS, NK) would have been better
MI: Mississippi, Missouri, Michigan, or Minnesota?
It's Michigan, but MG would have been a better choice
NE: Nevada or Nebraska?
It's Nebraska, but NB (or NR, NR, NS, NK) would have been better
MI: Mississippi, Missouri, Michigan, or Minnesota?
It's Michigan, but MG would have been a better choice
MS: Mississippi, Missouri, or Minnesota?
NE: Nevada or Nebraska?
It's Nebraska, but NB (or NR, NR, NS, NK) would have been better
MI: Mississippi, Missouri, Michigan, or Minnesota?
It's Michigan, but MG would have been a better choice
MS: Mississippi, Missouri, or Minnesota?
It's Mississippi, but MP would have been a better choice.
But solving these problems with reading 2-letter codes would still not solve the problem of writing them: your passive and active abilities are different.
I couldn't believe it wasn't possible to do the 2-letter codes better.
So I wrote a program (in ABC as it happens; more on that later).
The best rule I came up with:
This is about the original design: Canadian territories were later integrated into the system.
But that doesn't invalidate the argument: the 2-letter codes were introduced because of automation, but that is no excuse for ignoring the needs of people.
(Recommendation: How The States Got Their Abbreviations)
Usability is about designing things (software/programming languages/cookers) to allow people to do their work:
Efficient, Error-free,
Enjoyable or
Fast, Faultless and Fun
A problem is that the people designing things are usually not the people who will be using those things, and yet they tend to design for themselves.
So... you have to use HCI techniques:
Few talk about the usability of notations.
Yet the design of notations affects what you can do with them.
For instance, Roman numerals:
CXXVIII+CXXVIII
=CCXXXXVVIIIIII
=CCXXXXVVVI
=CCXXXXXVI
=CCLVI
I was helping my children with their maths homework, and a question arose for me:
Why do they make things so difficult?
My conclusion was that the problem is mathematics is taught in a historical order, and there has never been a synthesis.
So I went back to first principles with the question:
What would mathematical notation look like if it were designed with consistency and usability in mind?
What follows was more than a year's work, using reams of paper. It is hard work making things simple.
When you achieve a final simple result, it often looks so obvious that it hard to appreciate how difficult it was to get there.
As a colleague who designs program interfaces remarked: "When you succeed in making an interface as easy to use as a coffee machine, they treat you like a plumber"
I'm only going to show you the tip of the iceberg here.
It resulted in a monograph that I wrote for my sons' birthdays. You can read it here: Numbers.
Before I show the details, let me remind you of the difference between procedural and declarative approaches.
Procedural approaches describe the how.
Declarative approaches describe the what.
In school you learn procedurally how to add, subtract, multiply and divide, and then you are told
The square root of a number is another number that when you multiply it by itself, gives you the original number.
This doesn't tell you how to calculate the square root; but no problem, because we have machines to do that for us.
function f a: {
x ← a
x' ← (a + 1) ÷ 2
epsilon ← 1.19209290e-07
while abs(x − x') > epsilon × x: {
x ← x'
x' ← ((a ÷ x') + x') ÷ 2
}
return x'
}
This is why documentation is so essential in procedural programming, because the distance between the description of the problem space and the code is so great.
We have addition:
a+b
You can define subtraction as
(a+b) − b = a
This is a declarative definition. It tells you the what but not the how.
There is also a monadic version of −, which can be defined as:
−a = 0−a
Where 0 is the identity for addition, since
a+0 = a
Multiplication is at its heart repeated addition:
a × 3 = a + a + a
(Actual declarative definition:
a×(b+c) = a×b + a×c
)
It also has an identity value:
a×1 = a
Its complement is division, defined in the same way as subtraction:
(a×b) ÷ b = a
(I use ÷ instead of / because when user-testing with my target audience, they said "Please use the same symbols as on a calculator")
Notably, there is no monadic version of divide. But if we define it using the same pattern:
÷a = 1 ÷ a
something surprising happens: identities that we know from the lower level have exactly the same form as ones at this higher level. For instance:
−−a = a
÷÷a = a
a−−b = a + b
a÷÷b = a × b
−(a−b) = b−a
÷(a÷b) = b÷a
(Note that although − and ÷ are not commutative, they are therefore commutable.)
Just as multiplication is repeated addition, raising to the power is repeated multiplication:
a×3 = a + a + a
a↑3 = a × a × a
So we can define its complement in the same way:
(a↑b)↓b = a
This is of course what we know of as root, where x↓y traditionally, and weirdly, is notated
y√x
So if ↑ is a higher version of multiplication, then ↓ is just a higher version of division.
Defining it in this way suddenly exposes literally dozens of well known identities that have a similar form to identities at the two lower levels!
Just to pick a couple out:
a×(−b) = −(a×b)
a×(−b) = −(a×b)
a↑(−b) = ÷(a↑b)
a×(−b) = −(a×b)
a↑(−b) = ÷(a↑b)(a−b = 1/ab)
a×(÷b) = a÷b
a×(÷b) = a÷b
a↑(÷b) = a↓b
(I consider this so beautiful, that even if this had been the only result, the whole exercise would have been worth it!)
a×(÷b) = a÷b
a↑(÷b) = a↓b(a1/b = b√a)
Since + and × are commutative
a+b = b+a
a×b = b×a
you can extract both a and b from an expression:
(a×b)÷b = a
(a×b)÷a =
(b×a)÷a = b
But ↑ is not commutative (nor commutable)
a↑b ≠ b↑a
So we need another operator to get b.
(a↑b)↓b = a
(a↑b)⇓a = b
This is logarithm, where x⇓y is equally weirdly notated traditionally as
logy x
This exposes yet more interesting identities, of which I will show only one.
÷(a÷b) = b÷a
÷(a÷b) = b÷a
÷(a⇓b) = b⇓a
÷(a÷b) = b÷a
÷(a⇓b) = b⇓a(1/ logba = logab)
(I may have learned this at school, but if I did, I had forgotten it. When I saw this result, I was so amazed, that even though I could prove it, I have to admit I checked it with some values as well, to make sure it was right).
a+2 = 4
a = 4−2a × 2 = 4
a = 4 ÷ 2a↑2 = 4
a = 4↓22↑a = 4
a = 4⇓2
There's much more, but you'll just have to read the monograph
2023 — 32nd anniversary of the World Wide Web being announced:
6 August 1991: Tim Berners-Lee posts a short summary of the World Wide Web project to an internet newsgroup inviting collaborators
The first web servers had been made publicly available a few months earlier [History of the web] .
The web had been made possible by the internet becoming open and international:
The first open internet node outside of North America was installed at the CWI in Amsterdam, the Netherlands in November 1988 [CWI]. Two spin-offs were created to extend the internet into the rest of Europe.
On that day in 1988, public computing itself was barely thirty years old: in 1957 a computer had been installed for the first time in a municipality, as it happens in Norwich, UK [Norwich].
The original web was not revolutionary: hypertext programs that could do similar things already existed.
But the web had the right mix of existing elements:
and possibly the most important one:
A major property was that it was based on declarative principles.
Although there were some mistakes, HTML largely specified the role of the elements, rather than how they should appear.
For instance, an h1 was a top-level heading with no a
priori requirement that it be displayed in any particular way, larger or
in bold. It just stated its purpose.
This has a number of advantages, including machine and modality independence: you can just as easily 'display' such a document with a voice-reader as on a screen, without having to use heuristics to guess what is intended.
The poster-child of HTML declarative markup is the <a>
element:
<a href="talk.html" title="…" target="…" class="…">My Talk</a>
This single line compactly encapsulates a lot of behaviour including
Doing this procedurally in program code would be a lot of work.
Mistakes included hr (horizontal rule), and elements like
b and i for bold and italic, which
specify a visual property rather than a purpose.
But most of the structure was purely declarative.
The original HTML surprisingly did not have facilities for embedding images into documents, so they were added by the implementers of the first really successful browser, Mosaic.
Unfortunately, they didn't do a great job. They added a single element
<img src="…"> to embed an image at that location in the
code.
This has two regrettable, related, disadvantages: firstly, there is no failure fallback, and secondly there is no alternative for non-visual environments.
A better design would have allowed the element to have content to be used in fallback cases. For instance
<img src="cat.png">
<img src="cat.jpg">
A <em>cat</em>, sitting on a mat.
</img>
</img>
If the outer img should fail for whatever reason (the resource
unavailable, the browser not supporting png images, or it being a
non-visual browser), the nested img would be tried, and if that
failed, the text would be used.
The advantage of such a design to visually impaired users of the web should be obvious.
When png images were introduced on the web, their usage was
held back for a long time because of the lack of such a mechanism: people had
to wait until a critical mass of browsers were available that could display the
new image type before they could start using them.
This created the conditions for a potential vicious circle of png not being used because there were no implementations, and not being implemented because there were no users.
Then there are the unfortunate blink and font
elements that were introduced by the implementers, and we should not let that
excrescence the frameset, with its security and usability
problems, go unmentioned either.
A major innovation of ther web was the URL, which allowed you to combine documents from a plethora of sources into a single web page.
The URL is an ultimate example of a declarative interface, specifying what you want, and not step-wise how to get it.
Coding a URL as program code is truly a lot of work.
Analysing the design of the URL would require a complete 45 minute talk in itself, so let me point you instead to: Pemberton: On the design of the URL
The https scheme is a mistake, one of a number of early mistakes introduced
by Mosaic/Netscape, like <blink>, <img>,
and <frameset>.
The two URLs
http://www.example.com/doc.html
https://www.example.com/doc.html
locate the same resource in every way. The only difference is in details of the protocol being used to retrieve the resource.
Whether the connection is encrypted or not should be part of the protocol negotiation; users shouldn't have to be confronted with the negotiation between the machines about how they are going to transport the data.
Now we are being forced to change all our documents to use
https links. That shouldn't have been necessary.
Another advantage of declarative markup is that since display properties are not baked in to the language you can use style sheets to control the display properties of a document, without altering the document itself.
In fact one of the first activities of the newly-created W3C was to add
style-sheets as quickly as possible to undo the damage being done by the
browser manufacturers, who were unilaterally adding visually-oriented elements
to HTML, such as font, and blink.
The result, CSS, is another example of a successful declarative approach [CSS].
When W3C started the CSS activity, Netscape, at the time the leading browser, declined to join, saying that they had a better solution, JSSS, based on Javascript – in other words a procedural rather than declarative approach. Instead of the declarative CSS
h1 { font-size: 20pt }
you would use script to say
document.tags.H1.fontSize = "20pt";
The entry on Wikipedia remarks:
"JSSS lacked the various CSS selector features, supporting only simple tag name, class and id selectors. On the other hand, since it is written using a complete programming language, stylesheets can include highly complex dynamic calculations and conditional processing." [JSSS]
The first version of CSS was produced quickly, and has proved to be durable.
CSS is a greatly underappreciated resource. It is surprising how much can be done in a declarative manner, where many resort to using javascript.
I highly recommend You don't need Javascript for that for examples.
That notwithstanding, there were some initial design faults.
A design requirement was that CSS should stream. So any selector that couldn't support streaming was excluded. This is why the selectors are not symmetric, for instance you can select the following sibling, but not the preceding one.
Furthermore, a basic selector is the 'descendent of', which is very expensive: some environments even recommend against its use. 'Child of' would have been a more useful basic selector, with 'descendent of' an advanced selector.
The streaming decision I believe was an error: the more so since CSS selectors are now being used for other purposes than streaming. It would have been better to design a symmetric set, and indicate which were safe for streaming.
Another error was the ad hoc nature of the selector design: if a new selector was needed, they would look at the available characters left for its representation.
Compare this with XPath selectors, that started off with a coherent design first.
The first version of CSS was designed by people from print environments, and not designers. Consequently they failed to understand how important a grid was.
Luckily this has been corrected now, but it took far too long for such an essential design element.
The lack of designers initially also accounts for the appalling colour specification mechanisms.
RDF is the underpinning for the Semantic Web.
The original design of RDF made the mistake of conflating the abstraction with its representation, and produced an XML definition of RDF.
Later, other serialisations emerged, making it clear that RDF is an abstraction, independent of representations.
RDFa is one such alternative notation, layered on top of HTML, XHTML, and XML, that uses attributes to allow the extraction of RDF from documents.
You can add metadata to an HTML document by adding <meta>
and <link> elements in the head.
<meta name="description" content="A site about fish" />
gives a description of the current document. You could say that the current
page has a description property, whose value is "A site
about fish".
Similarly you can say:
<link rel="next" href="thecod.html" />
which says that if you consider this page as one in a series of pages, the
next one is thecod.html. In other words, this page has a
next relation to thecod.html.
There are a smattering of other places in HTML where you can add some
metadata, such as the title element and attribute in places, and
the cite attribute on <blockquote> and others,
but that is about it.
In passing, you might wonder why you can't say
<meta name="description">A site about fish</meta>
and the answer is simply that at the time this feature was added to HTML,
some browsers would incorrectly have displayed the text in the
meta element, even though it was in the <head>
and so to prevent that happening the content was put in an attribute
instead.
This was a mistake. They should have provided both and allowed the browsers to catch up.
RDFa generalises the meta and link elements to allow any element to generate metadata about the document. For instance
<h1 property="dc:title">Fish of the World</h1> <p>by <span property="dc:creator">John Smith</span></p>
and
<link about="[_:StevenPemberton]"
rev="foaf:img" type="image/jpg"
href="Steven.Pemberton.jpg" />
<link about="[_:StevenPemberton]"
rel="foaf:primaryTopicOf"
href="" />
<h1><a href="photos.html"
about="[_:StevenPemberton]"
property="foaf:name">Steven Pemberton</a>
</h1>
The original HTML was based on SGML, which is fairly complex and hard to implement.
As a result, XML, a pure subset of SGML, was created.
It was a good design, and they were brave to keep it to a subset.
For an analysis see: Pemberton: On the representation of abstractions
"Parsing is quite easy
It would be fairly easy to add a generalised part to the XML pipeline that parsed unmarked-up text, and produced XML as a parse tree: it's just a different sort of transform.
We could have our cake and eat it!"
Data is an abstraction: there is no essential difference between the JSON
{"temperature": {"scale": "C"; "value": 21}}
and an equivalent XML
<temperature scale="C" value="21"/>
or
<temperature> <scale>C</scale> <value>21</value> </temperature>
or indeed
Temperature: 21°C
since the underlying abstractions being represented are the same.
We choose which representations of our data to use, JSON, CSV, XML, or whatever, depending on habit, convenience, or the context we want to use that data in.
On the other hand, having an interoperable generic toolchain such as that provided by XML to process data is of immense value.
How do we resolve the conflicting requirements of convenience, habit, and context, and still enable a generic toolchain?
Invisible XML (ixml) is a method for treating non-XML documents as if they were XML, enabling authors to write documents and data in a format they prefer while providing XML for processes that are more effective with XML content.
ixml lets you treat any parsable format as if it were XML, without the need for markup.
body {color: blue; font-weight: bold}
can be converted into XML like these two, depending on choice:
<css>
<rule>
<simple-selector name="body"/>
<block>
<property>
<name>color</name>
<value>blue</value>
</property>
<property>
<name>font-weight</name>
<value>bold</value>
</property>
</block>
</rule>
</css>
<css>
<rule>
<selector>body</selector>
<block>
<property name="color" value="blue"/>
<property name="font-weight" value="bold"/>
</block>
</rule>
</css>
You have one or more documents in a non-XML format. You supply a description of that format, that includes how it should be converted to XML. The ixml processor then reads the description, and uses that to read and convert the documents to XML.
As a simple example, you want to convert a date to XML:
4 November 2021
So we describe what a date looks like:
date: day, " ", month, " ", year.
A day is one or two digits:
day: digit, digit?.
digit: ["0"-"9"].
Define a month:
month: "January"; "February"; "March"; "April";
"May"; "June"; "July"; "August";
"September"; "October"; "November"; "December".
A semicolon can be read as "or": it allows you to specify alternatives for a rule definition.
Finally a year is just four digits:
year: digit, digit, digit, digit.
Running it on the input "4 November 2021" gives:
<date>
<day>
<digit>4</digit>
</day>
<month>November</month>
<year>
<digit>2</digit>
<digit>0</digit>
<digit>2</digit>
<digit>1</digit>
</year>
</date>
But we're really not interested in the digit elements. To
indicate that, we just put a minus sign before the rule for digit:
-digit: ["0"-"9"].
which says this element should not be produced (we still get the element content though), giving:
<date> <day>4</day> <month>November</month> <year>2021</year> </date>
Unsurprisingly ixml is also expressed in ixml.
For instance a rule is
rule: (mark, s)?, name, s, ["=:"], s, -alts, ".".
More details at Introduction to Invisible XML which has links to a number of design papers, tutorials, and a link to the specification.
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Also pretend, just for a moment, that their chief method of communicating with a computer was with programming languages.
Imagine, hypothetically, that programmers are humans...despite all evidence to the contrary:
Also pretend, just for a moment, that their chief method of communicating with a computer was with programming languages.
What should you do?
We designed a programming language: ABC
We used HCI principles:
A procedural language with only 5 very high-level data types.
Our biggest take aways:
Many cryptographic algorithms in use today were designed with ABC.
ABC went on to form the basis of Python.
In building a programming environment for ABC, we developed a concept that was a stronger version of WYSIWYG, that we called TAXATA: Things are exactly as they appear
We built a system (Views) that made this principle the central element of the design: if you changed something (edited it) the system changed itself to match.
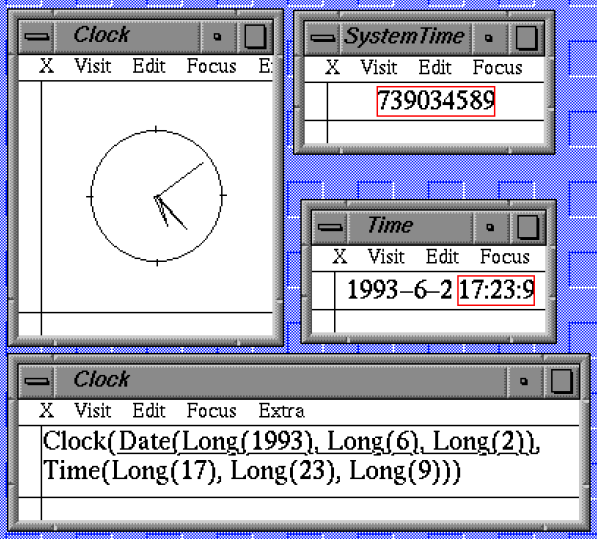
This system had an extensible markup language, vector graphics, style sheets, a DOM, client-side scripting ... today you would call it a browser (it didn't use TCP/IP though).
It ran on an Atari ST (amongst others).
The Views system client-side programming language was a first attempt at defining a declarative programming language.
We saw that it gave you immense power, and ease of use at the same time.
But that is for next time...
Notations are a greatly overlooked issue in the field of usability.
Good notations have all the features of good interaction designs:
And see you in person in April!