Finding meaningful objects in a fully automatic way is impossible. The higher the level of automation, the stronger the components found will rely on the actual technical implementation of the legacy code. The purpose, however, is to find object that are close to the application domain, not to the technical infrastructure.
Therefore, tool support for object identification must not aim at full automation, but rather at providing interactive system understanding, i.e., at assisting the re-engineer in understanding what components (modules, databases, screens, copybooks, ...) the system consists of, and how these are related to each other.
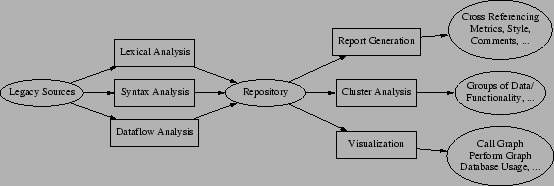
Figure 1 shows the extractor-query-viewer approach used in most reverse engineering tool sets [37,16,20]. It can be used to extract all sorts of facts from the legacy sources into a database. This database, in turn, can be queried, and relations of interest can be visualized.
In the extractor phase, syntactic analysis will help to unravel the structure of the legacy code. This requires the availability of a parser (or grammar) for the legacy language, which is not always the case. Issues pertaining to parser development are discussed in more detail in Section 3. If no parser is available, and if the required fact extraction is sufficiently simple, lexical analysis methods may be used: these are less accurate, but simpler, faster to develop and to run, and tolerant with respect to unknown language constructs or errors in the source code [38,20].
In the querying phase, operations on the repository include relational queries, restriction of relations to names matching regular expressions, taking transitive closures of, for example call relations, lifting call relations from procedures to files, etc. A crucial aspect of querying is filtering: restricting the relations to those items that are relevant for the understanding task at hand, Such a task could be, e.g., finding variables and programs representing business entities and rules. Several heuristics for filtering in the COBOL domain, for example based on call graph metrics or the database usage, are discussed in [20].
In the viewing phase, the derived relations can be shown to the re-engineer in various forms. One way is to use metrics for this purpose, pointing the re-engineer to, for example, programs with a complexity measure higher than average. An alternative technique is the use of cluster analysis in which a numeric distance between items is used for the purpose of grouping them together. Of particular importance is system visualization. Most common in the area of system understanding is the use of graph visualization, to display, for example, call graphs, database usage, perform graphs, etc. Interesting other ways of program visualization are discussed by Eick [24], who, for example, is able to visualize extremely large code portfolios by representing each source line by just one colored pixel.
The main benefit of this three-phase tooling approach is that the repository permits arbitrary querying, making it possible to apply the tool set to a wide variety of renovation problems. Generally speaking, a system understanding session will iterate through these three phases, using, for example, visualization to see which filtering techniques to apply in the next iteration.
Obviously, the application of system understanding tools goes beyond mere object identification: other possibilities include generation of (interactive) documentation, quality assessment, and introducing novice programmers to a legacy application.