Issue
Article
Vol.28 No.3, July 1996
Article
Issue
Issue |
Article |
Vol.28 No.3, July 1996 |
Article |
Issue |
Multimodality is a powerful concept for dealing with dialogue cohesion in a Human-Computer Natural Language centered system. Two issues, important for a the more effective exploitation of the potentially large bandwidth of communication provided by this situation are presented: (i) the integration of navigational and mediated aspects of interaction; (ii) the use of a graphical representation of the dialogue structure to allow the possibility of direct manipulation. Examples from real interaction with AlFresco, a prototype for art exploration, are used to give a concrete idea of the implemented concepts.
The more effective exploitation of the potentially large bandwidth of communication provided by multimodal dialogue systems can open new scenarios in Human-Computer Interaction.
In this paper we will focus on two points that have been central in our work on AlFresco, an interactive system for users interested in Fourteenth Century Italian art:
We shall try to give an idea of the results by means of examples of actual interactions with the AlFresco prototype.
Integrating NL with hypermedia facilities provides some advantages: from the NL perspective, integration is a way of organising heterogeneous and unstructured information, for favouring the direct manipulation of all objects, and for facilitating explorative behaviour; from the hypermedia perspective, integration provides a solution to the problems of disorientation and of cognitive overhead ([Conklin,1987]) resulting from the presentation of too many explorative possibilities (i.e. links). It allows complex goal-oriented behaviour, typically expressed through natural language dialogues. Integration allows us to look at all this as an independent new approach [Stock,1995]. It offers a high level of interactivity and system habitability in which each modality overcomes the constraints of the other, resulting in a novel class of integrated environments for complex exploration and information access. Some of the main problems in information access interaction lie in the fact that the user may not have a clear goal at the beginning of the interaction, or she may not be aware of the system coverage and capabilities or of features of information actually available. Exploration of the information space is a key point. We briefly introduce a two-dimensional model of information exploration following [Waterworth and Chignell,1991]. We then show an interaction with AlFresco in which the user combines explorative and goal-oriented behaviours smoothly moving along the two dimensions.
As far as the graphical representation of the discourse structure is concerned, when a reference error occurs in natural life situations, another natural language process of communication has to be started to agree on the suspended, failed process. The two uses of the same NL medium are obvious in human-human communication. In an NL human-computer system it is quite possible to avoid using natural language for this kind of metacommunication. In a number of situations a fast turnaround confirmation, on the basis of some key coherence elements (resulting from some accurate underlying processing) to be conveyed in a simple graphical format, will do. An important point for our human-computer system is that feedback is provided with a modality that involves light cognitive load, compared with the one involved in a complex clarification sub-dialogue or even in a paraphrase interpretation process by the human participant. The dialogue model exploited in AlFresco is explained in an informal way, and a case of recovery from a reference interpretation error by the system is shown. An idea along the same direction is presented in ([Cohen,1991]) and has been integrated in the Shoptalk system [Cohen et al.,1989]. Shoptalk was probably the first system in which multimodality was used to resolve meta-level problems: anaphora is transformed into a problem of pointing with the use of windows for managing different focus spaces. In our work, the difference between communication and metacommunication is explicit. Cohen's principle of synergicity ([Cohen,1991]): "to use the strengths of one modality to overcome weaknesses of another" is applied to good advantage at the level of metacommunication.
Natural use of anaphora is not substituted, nor does the user have all the burden of explicitly relating things. The system understands, feeds back in a cognitively light manner and communication may be adjusted with little effort by the user.
Before getting in the details of the system, a brief overview of the AlFresco Interactive System will be given with particular emphasis on its pragmatics modules.
AlFresco [Stock and Team,1993] is an interactive, natural-language centered system for a user interested in frescoes and paintings, with the aim not only of providing information, but also of promoting other masterpieces that may attract the user. It runs on a workstation connected to a videodisk unit and a touch screen. The particular videodisk in use includes images of Fourteenth Century Italian frescoes and monuments. The system, besides understanding and using language, integrates it with hypermedia both in input and output. The user can interact with the system by typing a sentence, navigating in the underlying hypertext, and using the touch screen. In input, our efforts have been focused on combining the interpretation of linguistic deictic references with pointing to images displayed on a touch screen. In output, images and generated text with buttons offer entry points for further hypertextual exploration. The result is that the user communicates linguistically and by manipulating various entities, images, and text itself.
We shall not report here of the specific Natural Language processing modules. Let us only briefly introduce some modules in AlFresco relevant for our discussion. The domain and some dialogue information are represented in a knowledge representation language based on descriptive logics (Loom). Concepts are described in the so called Terminological Box (or Tbox) and instances in the Assertional Box (or Abox).
A dynamic user model develops as the dialogue proceeds and contains two kinds of information (represented in two modules called UK and UI): what the user has been exposed to (linguistically or through images) or is assumed to know, and what the user seems to be interested in. The former kind of information is mainly used during the recognition of communicative intentions and the latter is used in the process of output generation. The user's knowledge model, or UK, is based on an initialization (depending on a user profile) and on a modelization of what the user has become aware of so far or of some limited implicatures. The user's interest model, or UI, provides a model of the potential interest of the user and consists on an activation/inhibition network whose nodes are associated with ordered sets of individual concepts.
It plays an important role for defining context especially for what concerns focus management. The version used at present is described in [Zancanaro et al.,to appear] and is based on an adaptation of the Centering Model, developed for dialogues in a multimodal environment. Its tasks are (i) to resolve anaphoras (ii) to build a dialogue structure based on cohesion and (iii) to manage focus spaces. The use of a graphical feedback of the dialogue cohesion status to the user was presented in [Zancanaro et al.,1993]. An example is shown later.
Communication from the system's part can result in actions such as describing a fresco, showing a picture or indicating on a map how to reach a particular place and so on. The system must determine how to present the information to be conveyed. According to [Arens et al.,1993] the types of knowledge required for this task are: a) the nature of the information to be conveyed; b) the characteristics of the media to be used; c) the communicative situation (i.e. communicative intention and surface intention). In our system the presentation action is determined through classification (Loom realization mechanism) in the KB. Taxonomies of presentation actions, media and kinds of objects are defined at the conceptual level and are transportable over domains and situations by adding, if needed, more specific presentations and media. Implicit in the module's output is the offer of a shift between a navigational modality of exploration and a mediated access to information. For instance it may show a hypertext card, giving the user the opportunity of starting a hypertextual navigation.
Following [Waterworth and Chignell,1991], there are at least two dimensions for a model of information exploration: structural responsibility and target orientation. Structural responsibility involves the issue of which agent (i.e. the user or the system) is responsible for carrying out search and for giving structure to information. It gives rise to a dichotomy between navigational and mediated exploration. Navigation is unstructured from the system's point of view; it is the user that gives structure to it. The dimension of target orientation presents a dichotomy between browsing and querying. Browsing is distinguished from querying by the absence of a definite target in the mind of the user. This distinction is determined only by the cognitive state of the user, not by her actions nor by the configuration of the system. In reality there is a continuum of user behaviours varying between querying and browsing so that it is inappropriate to build systems that reflect this strict dichotomy, imposing one particular attitude on the user's exploration.
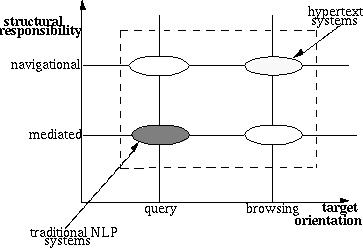
Figure 1: Two Dimensions for Information Exploration
In figure 1 a diagram of this situation is depicted, positioning in it traditional question-answering systems and hypertext systems. Our aim is to propose an environment in which all the depicted interactional possibilities are integrated: interaction should move smoothly along the two dimensions. Dialogue management must include a communicative action coordinator which is responsible for proper media usage (and so, for example, it can take into account the deictic context at any time of the interaction) and for suggesting to the user a shift along the structural responsibility dimension.
Let us follow an example of actual interaction with AlFresco.

Figure 2
The user asks: "Speak to me about Ambrogio Lorenzetti" (see figure 2).
AlFresco answers producing a generated text with buttons in a hypertextual card. A generated text with buttons can be seen as an implicit negotiation. The system proposes the responsibility to the user, but the final decision is left to the user herself: she can choose whether to shift from a mediated to a navigational browsing or not. Let us suppose the user wants to see a comment by Argan (a famous art critic) about the "Annunciation" (a fresco by Lorenzetti) and she clicks on the <Argan> button. The user starts a hypertextual navigation. Once the user has chosen to follow a hypertextual link she takes the responsibility of giving structure to information on her own. The system maintains awareness of the changes in the context of the communication: so the user is free to give back the responsibility to the system whenever she wants. In figure 3, the system displays Argan's comment about the "Annunciation". After having read it, the user may want to see the fresco and clicks on the first button of the card. The second monitor (touchscreen) now is displaying the "Annunciation" by Ambrogio Lorenzetti.

Figure 3
A complex nonlinguistic exchange, starting with a clicking act on a hypertextual button has taken place which links the subsequent linguistic question to preceding one. In figure 4 the user switches from hypertextual navigation to a NL query and asks: "Who is this ^ person?" touching a character on the fresco (on the touch-screen not represented in this picture). The system answers `Madonna'. Querying the system in NL the user is now giving the responsibility back to the system.

Figure 4
The system is aware that on the touchscreen the Annunciation is now shown, even if its displaying was not under its responsibility.
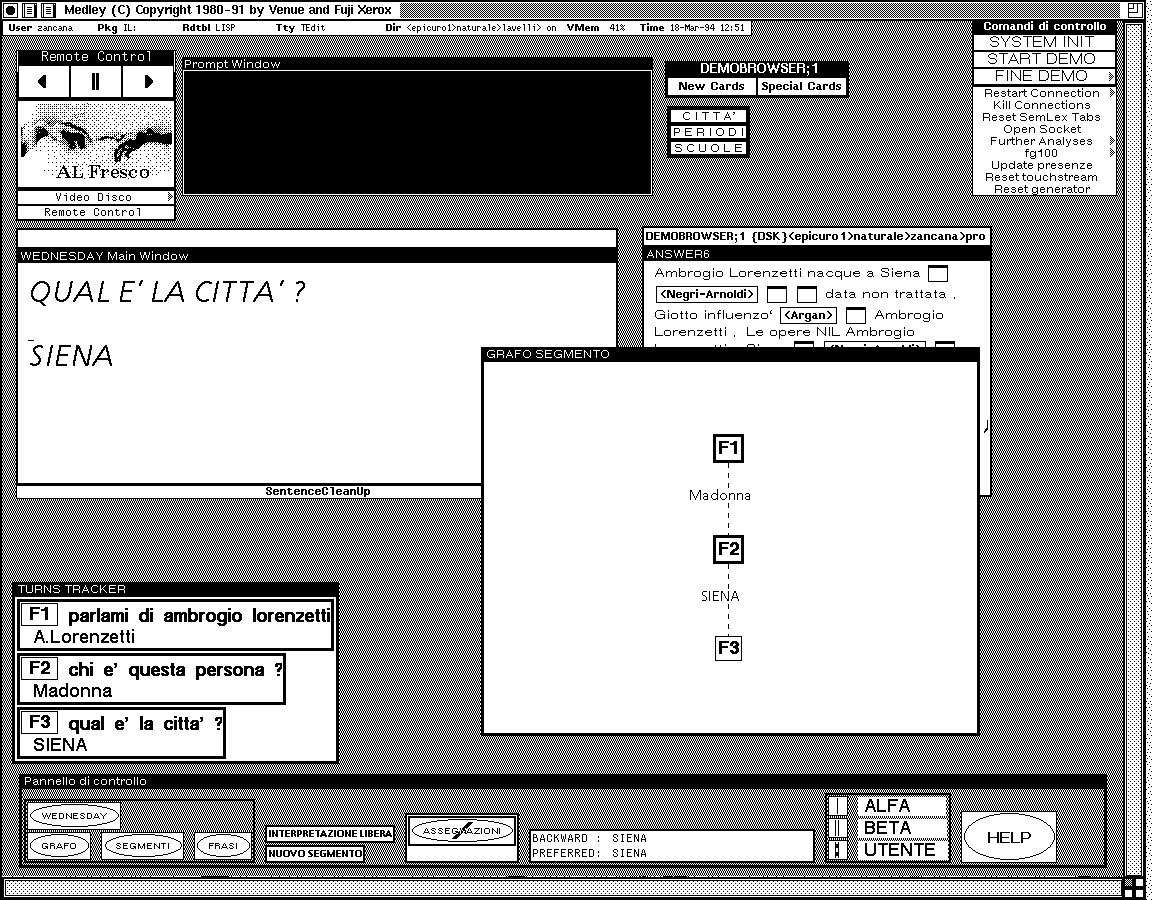
Figure 5
Then the user comes back to the generated hypertext, claiming the responsibility for herself once again, and clicks a button to see "Gli Effetti del Buon Governo" (The Effects of Good Government), another famous fresco painted by Lorenzetti. The touch-screen is now displaying this fresco. Finally (figure 5) the user comes back to a NL query and asks: "What is the town?". `Siena' is the answer from AlFresco. Let us note that the new picture on the touchscreen is essential to give sense to the question (the Annunciation does not include a town).
As mentioned in the introduction, the dialogue manager was meant to fulfil two different tasks: to constrain inference in the anaphora resolution process and to provide a graphical representation of the discourse structure. The latter can be useful to limit the problem of opacity and, through the use of direct manipulation, to avoid the necessity of operating linguistically at the meta-level.
To do this, a dialogue model was needed simple enough to be shown on the screen, but powerful and accurate. Here the centering model (the more complete work on centering is [Grosz et al.,1995]) was revisited and modified for adaptation to an information access system. The model has been also extended to deal with deixis. See [Zancanaro et al.,to appear] for more details.
In an information access dialogue we can imagine that a question is coherent with the preceding dialogue when it is a follow-up of a preceding turn. There are at least two ways in which a question may be a follow-up of a turn, either it is about the same subject of the question of that turn, or it is about the same subject of its answer. The former is called α-coherence (in the graphical representation it is depicted as a single line) and the latter �-coherence (depicted as a double line). Turns are totally ordered with respect to the moment of their occurrence. Thus a segment can be formally defined as a totally ordered set of turns among which some coherence relation holds.
Let us show an example of a reference problem resolved using the graphical feedback. In figure 6 the dialogue proceeded as follow
F1: U: Show me a painting of Giotto in the Cappella degli Scrovegni
S: <the system shows Fuga in Egitto on the touch screen>
F2: U: Is there a painter who was influenced by the master?
S: Yes, for example Ambrogio Lorenzetti
F3: U: Who is this ^ baby? (The user touches the image of Infant Jesus on the touch screen)
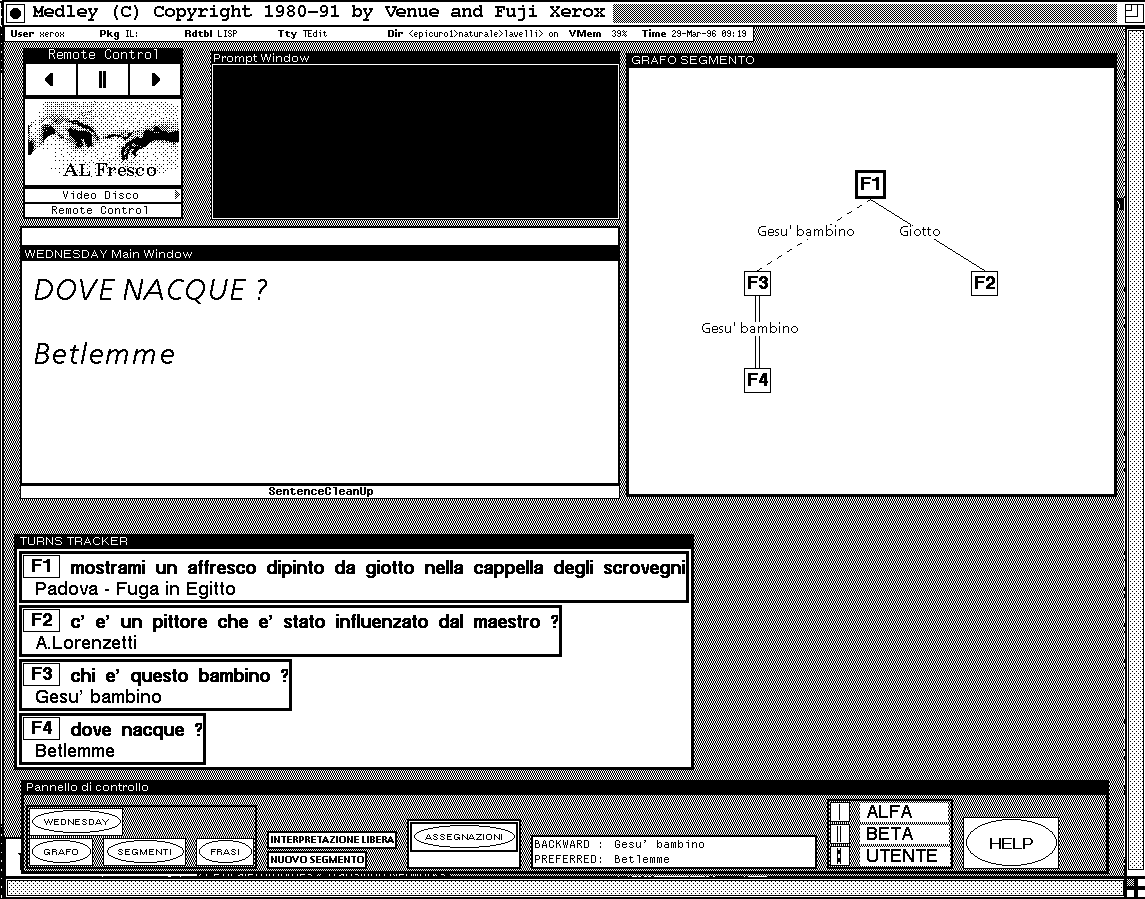
Figure 6
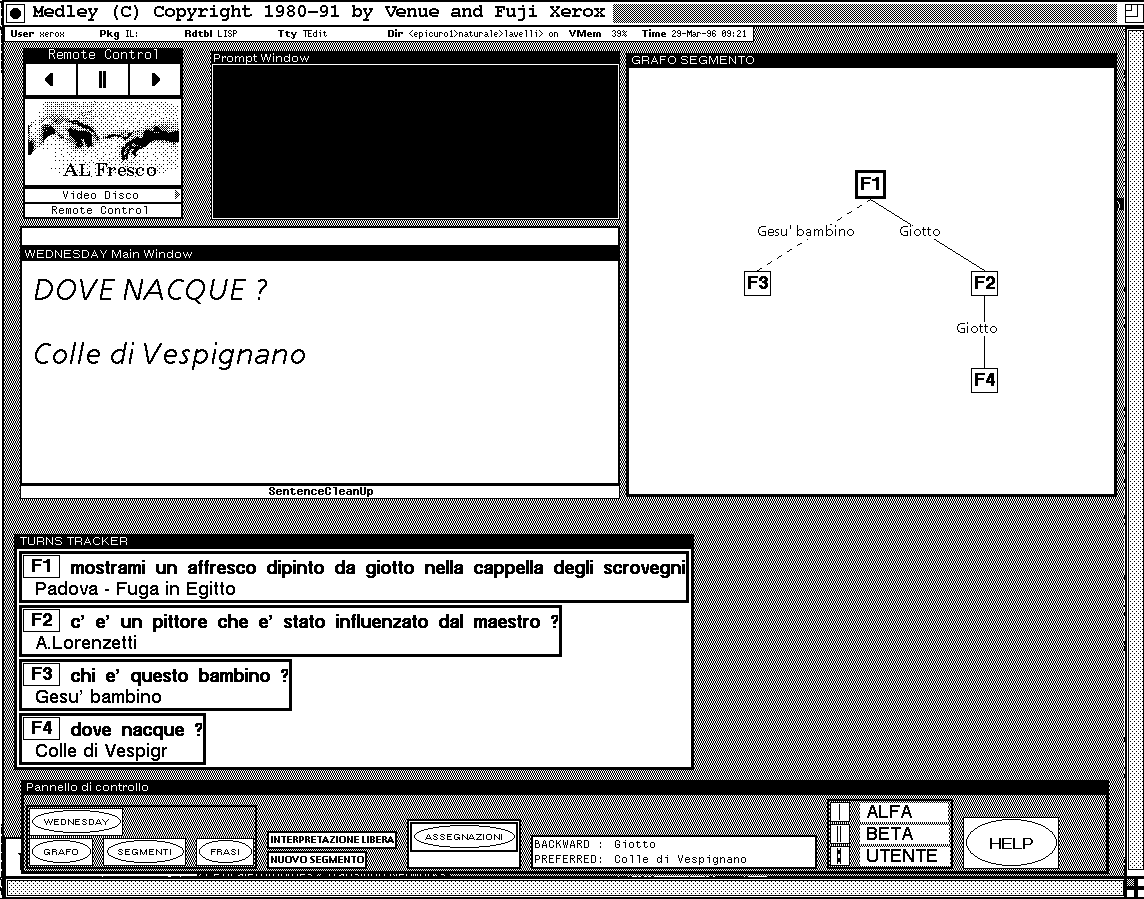
Figure 7
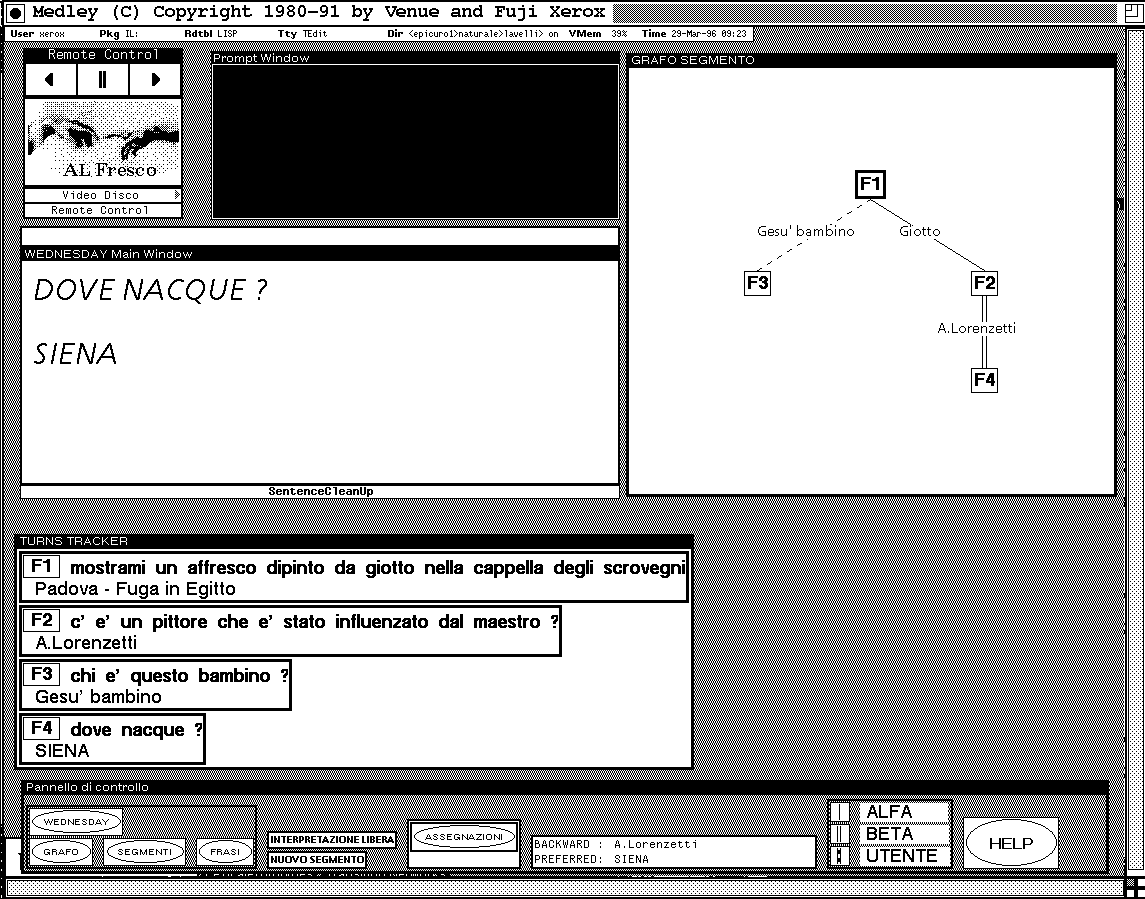
Figure 8
S: Infant Jesus
F4: U: Where was [s/he/it] born? (In Italian the pronoun is not expressed and there are no gender constraints)
S: Bethlehem
Suppose the user meant instead Giotto's birthplace. The system misconception can be immediately detected because the graphical representation of the discourse is different from what was expected. The user can easily resolve the problem imposing the correct relation by direct manipulation (see figure 7). Another possible interpretation (Lorenzetti's birthplace) with �-relation to F2 in the place of the α-relation is shown in figure 8. As far as possibilities of direct manipulation of the structure are concerned, the following features have been implemented:
AlFresco has been developed to be an innovative multimodal system based on an integration of natural language and hypermedia. The ideas behind the project are: a) information access can become much more effective in an environment where navigational and mediated moments of interaction can coexist coherently and contribute synergistically to the dialogue; b) natural language communication with a computer can exploit a larger bandwidth of communication than in telex-like, natural language only modalities; some concepts such as feedback can be realized exploiting the graphical interface on the screen, differently from what we are used to; c) altogether a new modality of natural language may slowly develop (after face to face and written language and their variations). AlFresco has been built at IRST across a number of years and it was also a point of integration of a number of natural language functionalities. It runs on a Unix machine and is implemented in Xerox Medley Lisp. Finally, many issues originated from the work presented here are part of our research program; among these we are currently focusing on a more sophisticated user modelling including surface intention, beliefs and plan recognition in the multimodal environment.
We would like to thank all the IRST group that was involved in the various steps of the development of AlFresco.
Istituto per la Ricerca Scientifica e Tecnologica,
I-38050 Povo/Trento, Italy
e-mail:
stock@irst.it
strappa@irst.it
zancana@irst.it
Issue |
Article |
Vol.28 No.3, July 1996 |
Article |
Issue |